arm
ESP8266
安全
导航
postman
vsprintf
wpf
时间复杂度
技术美术
xcode
漏洞
dreamweaver
深度信息
ZYNQ
PDF合并与拆分
信奥
VIVADO
Scratch等级考试四级
android 9
Starter
big data
2024/4/12 8:39:38
物联卡管理平台是否重要
在物联网蓝海中,众多物联卡代理平台层出不穷,但迄今为止能够依然占据市场的绝非等闲之辈。同在物联网行业中发展,为什么有的物联卡代理平台能做的风生水起,而有的从此一蹶不振?主要还是看物联卡代理平台提供的物联卡云平台&#…
物联网卡可以应用在哪些领域
现在我们频繁地提起智能城市、智能、智能家居、智能物流、智慧农业……这些产业都离不开物联网的支持,随处可见的广告 机、自动售货机、共享单车、pos 机……物联网已经渗透到我们的生活的方方面面。 物联网卡解决方案应用的行业领域比较多,包括农业…
对物联网的误解有哪些
物联网是数字化转型的新面孔,尽管一些组织并不了解它的全部功能,并且仍然对它如何以多种方式利用物联网(包括在制造中)感到困惑。数字化转型正在企业的方方面面发生,尤其是制造业。工厂不再远离其他业务流程,工人不再抱怨孤立的数…

spark-Standalone 三种运行模式
一、驱动driver在集群运行模式, 以cluster方式提交时,port最好设置为6066,因为这种方式提交时,是以rest api方式提交application
bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop101:6066 \
--depl…

pyspark学习41:用正则表达式过滤dataframe的指定列
创建一个dataframe:
df spark.createDataFrame([("a", 1), ("b", 2), ("c", 3)], ["Col1","a"]) df.select(df.colRegex("(Col)?.")).show() #返回字段名中以Col开头的列
,也可以理解…

pyspark学习41:计算皮尔森相关系数、协方差、查看行数和描述性统计信息、更改列名、删除列
对应视频40、41
课件3.3
启动pyspark:
pyspark --master spark://hadoop101:7077 --executor-memory 950m --executor-cores 2
读取hdfs上的文件创建一个dataframe
>>>df spark.read.csv(/sql/customers.csv,headerTrue)
1、查看行数 2、查看数据…
sql列印_列印支架编号
sql列印Problem statement: 问题陈述: Given an expression exp of length n consisting of some brackets. The task is to print the bracket numbers when the expression is being parsed. 给定表达式exp的长度为n,由一些方括号组成。 任务是在解析…
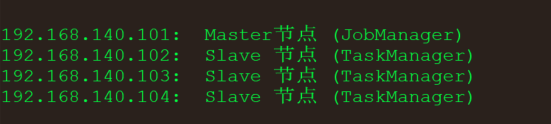
Flink的安装和部署--Standalone集群模式
Flink提供了多种集群模式,主要包括:Standalone和Flink on Yarn两种方式,Standalone是Flink的独立部署模式,它不依赖其他平台,如果
想搭建一套独立的Flink集群,可以考虑使用这种模式。 具体安装步骤(主节点)
(flink-1.10.2-bin-scala_2.11.tgz用这个即可)
flink-1.…

《推荐系统实践》 第一章 好的推荐系统 读书笔记
推荐系统的方法 按照数据分:协同过滤、内容过滤、社会化过滤 按照算法分: 基于邻域、基于图、基于矩阵分解、概率模型
好的推荐系统
推荐系统的主要任务、推荐系统和分类目录以及搜索引擎的区别等
背景
随着信息过载,有目的的购买东西方式变化过程&a…
0622-马棕榈跌9%
最近市场氛围极度偏空。PVC甚至日线十连阴。直线下跌。最近市场跌的很流畅。尤其是铁矿石黑色系。PVC塑料,油脂,铜。这种流畅的单边下跌你都没有进场的话,你还能干什么呢。刚刚八点收盘的马来西亚棕榈油甚至跌了9%。棕榈油今天九点开始单边下…
DB2数据库的简单导出和导入
目录
场景:需新做一个开发环境数据库,需要在原数据库SCHEMA_NAME复制一份到新SCHEMA_NAME命名的DM_STDD
1.导出结构
2.导出数据
3.更新数据库名称为DM_STDD
4.导入结构DM_STDD
5.导入数据DM_STDD 场景:需新做一个开发环境数据库&#x…


光模块质量如何判断?
光模块的质量决定了光网络的传输质量,劣质的光模块会存在丢包、传输不稳定、光衰大等问题,市面上贴牌、二手和劣质的光模块比比皆是。以下是光模块质量判断指标。 ①标准协议 光模块必须符合MSA多源协议,厂家需通过CE、ROHS、FCC、ISO…

发射光功率和接收灵敏度的正常范围
由上文我们可以了解到光模块的发射光功率和接收灵敏度在正常范围之内,才能确保光模块是可以正常工作不丢包、没有光衰的。但是不同工作波长、传输距离和速率的光模块发射光功率和接收灵敏度是不同的,在使用光功率计进行测试的时候要有一个参考数值。例如…

高速率光模块能否用在低速率端口上?
现在市场上用得比较多的光模块速率大多在1.25G到100G之间,交换机上的端口类型有1G/10G/电口/25G/100G等。但在外观上1G端口和10G端口类似。这时就有疑问了,高速率光模块能否在低速率端口使用,低速率光模块能否在高速率端口使用? …

纯千兆电口模块和自适应电口模块的区别
在网络的建设当中,光模块是必不可少的一个配件,面对不同环境的网络建设,光模块的选择也是大不相同,今天我们要讲的是特殊的电口模块。 电口模块支持热插拔,具有功耗低、性能高、设计紧凑等特点。现如今常见的有…

传统智能网卡 vs DPU智能网卡
传统数据中心基于冯诺依曼架构,所有的数据都需要送到CPU进行处理。随着数据中心的高速发展,摩尔定律逐渐失效,CPU的增长速度无法满足数据的爆发式增长,CPU的处理速率已经不能满足数据处理的要求。计算架构从以CPU为中心的Onload模…
湖为底·数共生·谋未来,纳多德参加易华录2021第三届数据湖大会
12月17日,以“湖为底数共生谋未来”为主题的易华录2021第三届数据湖大会在天津华录未来科技园成功举办。纳多德与来自易华录、华为、英伟达的专家、学者以及众多产业链生态伙伴进行了精彩纷呈的主旨分享,为实现“双碳”战略集思广益、开拓思路࿰…
spark——简单操作
启动作业 spark-submit --master yarn --deploy-mode cluster --executor-memory 512m --class 主类包.类名 xxx.jar spark-submit --master yarn --deploy-mode cluster --executor-memory 512m --executor-cores 1 --num-executors 1 --conf spark.cores.max5 --class com.ad…
当前发展通用视觉的核心,是提升模型的通用泛化能力和学习过程中的数据效率
“书生”在分类、目标检测、语义分割、深度估计四大任务26个数据集上,基于同样下游场景数据(10%),相较于最强开源模型CLIP-R50x16,平均错误率降低了40.2%,47.3%,34.8%,9.4%。同时&am…
人类发展人工智能的一个方向就是,让人工智能变得越来越聪明
封面新闻:相对于而言,很多人会认为人工智能是一个非常偏工科的课科学研究,而您研究哲学,为什么想到要用哲学来谈论人工智能呢?您是如何看待哲学和科学之间的关系的呢?你是怎么想到要将人工智能作为自己的哲…
人类其实很脆弱,一个小小的条件变化,就能导致人没法享受元宇宙
封面新闻:目前关于“元宇宙”的讨论和关注度非常高。有很多不同的视角去阐述和理解。您本人对之如何理解?
徐英瑾:我理解的“元宇宙”跟现实帝国平行的一个网络虚拟王国国。在这个虚拟王国里,人可以像使用真金白银一样购买现实物…
新技术发展带来的文艺创作正在或即将营造出的“可能世界”
从自由生长到精品孵化:营造文艺评论灵动的气韵 动辄受众超过百万的弹幕、豆瓣评论中,不乏对传统文艺评论的模仿和致敬之作,囿于短小的篇幅与随意性、碎片化的传播形式,难以与传统文艺评论连接起来。借力网络文艺评论的规范效应&am…
人工智能算法帮助艺术家从创建的数据库中提炼视觉精髓
初次看到您的作品《人造自然史》时,它使用了一种非常逼真的视觉语言,就像是来自18世纪的植物学或动物学的百科全书插画一样。所以古典的生物分类学吸引您的地方是什么? 吸引我的地方在于,它基本上准确地概括了我们在照相机出现以前&…
如果给后互联网的社交电商时代总结,可以称之为去库存时代
一场以产业深度变革为主导的新发展时代正在上演。早些时候,这样一场发展,还是以互联网为主体的,主打的是互联网的概念,我们可以将这样一个阶段看成是互联网的延续。这个阶段之后,产业的变革开始进入到以新技术为主导的…
数字化仅仅只是工具,智慧才是终局
数字化,是智能化的先导。这一点,正在成为越来越多的人的共识。无论是在零售行业,还是在制造行业,这一点都是适用的。尽管数字化可以让零售行业从传统的有形存在,变成一个无形的、数字化的存在,但是…
人工智能将有助于创造在线环境,让人们在元宇宙中体会宾至如归的感觉
网络安全领域的人工智能 今年1月,世界经济论坛发布《2021年全球风险格局报告》,认为网络安全风险是全世界今后将面临的一项重大风险。 随着机器越来越多地占据人们的生活,黑客和网络犯罪不可避免地成为一个更大的问题,这正…
人工智能在技术发展和落地应用等方面都获得了诸多突破
信息技术的发展使得数据采集、存储、管理等成本下降,同时也给机器学习等人工智能方法提供了足够的训练样本,使大数据成为人工智能发展的三大重要基础(数据、算法和算力)。在近年来大数据技术发展的基础上,人工智能在技…
从词到曲这个创作过程用 AI 的方式来解 是典型的序列到序列学习任务
我们的整个研究主要围绕理解和生成两个方向进行。在音乐生成方向,商品化音乐的整个制作流程是非常长的,涉及很多技术链条。举个例子,创作一首音乐最基本的就是词曲创作,从词到曲这个创作过程用 AI 的方式来解,就是一个…
人工智能里常见的自然语言生成、系列到系列学习、可控的系列生成
再举一个歌声合成的例子。歌声合成是曲谱和歌词合成声音,实际上它和语音合成非常类似。两者相比最大的区别在于,语音中的人声音高和时长基本上是比较平稳的、确定的,比如男生音高大概是一两百赫兹,女生音高大概是两三百赫兹。 …
不希望演化成 AI 完全取代人类,这也是不太得体的一种方式
InfoQ:AI 音乐大概什么时候可以完全不需要人工参与呢? 谭旭:关于这个问题,可以从两种角度进行回答。一种角度是,我们是不是真正期待 AI 音乐完全不需要人类?如果 AI 真正取代了人类,不需要任…
AI的神话假设我们将通过在狭义的应用上取得进展来实现AGI
深度学习的最新进展重燃了人们对可以像人类一样思考和行动的机器或通用人工智能(AGI, Artificial General Intelligence)的兴趣。 这种想法认为,沿着构建更大更好的神经网络的道路前进,我们将会向创造数字版的人类大脑不断迈进…
分布式应用程序架构和混合云使服务器之间所需的通信量成倍增加
早在拨号互联网时代之前,当病毒通过受感染的软盘传播时,网络安全就一直很重要。对手与 IT 专业人员之间的战斗不断升级。攻击者会创建新的和不同类型的恶意软件或攻击,IT 团队部署新的或改进的防御类型来保护他们不断增长的数据库存。 在…
人工智能通常是无实体的,如自然语言处理等机器学习
我们都知道大脑是控制身体的中枢,或者夸张点说,身体只是大脑的傀儡。然而事实果真如此吗?认知科学指出,人类并不总是“先知后行”,很多时候也会“先行后知”,身体在塑造精神方面也有着强大的能力。但是人工…
人工智能进入生产生活的各个领域,将深刻改变方式和思维模式
随着我国经济发展达到一个新的阶段,科技创新日益成为经济建设的核心力量。 目前经济处于转型期和过渡期,新的代表未来先进生产力的新兴科技产业将逐步从孕育期走向成长期。以科技创新为代表的战略性新兴产业才是未来长线牛股的诞生方向。 新的科…
科技是国之利器,人工智能与机器人发展势不可当
当今,全球科技界最炙手可热的名词莫过于“人工智能”。 第二届“清华大学国强研究院杯”全球人工智能与机器人双创大赛由清华大学国强研究院主办,将于即日启动,并持续至今年年底,分为项目征集、海选、晋级赛、决赛和颁奖五个阶段。大赛将在全球范围内征集优秀参赛项目,着重…
人一直生活在其用技术构建的世界里,元宇宙可能是技术世界的未来版本
若认识到这一点,未来,对元宇宙的监管和治理可能面临的不是单一维度的技术体系——唯一的大写的元宇宙帝国,而是一个多维整合的技术体系——多样化的元宇宙共和国或多种微世界的联合体。对元宇宙的治理应有前瞻性的考量。 首先,…
人工智能是在海量数据集的基础上运行的 被运用于代替人类决策
人工智能有助于解决这个时代最棘手的一些问题,如气候变化和流行疾病。但如果使用不当,人工智能也会造成伤害。为了减轻人工智能的潜在危害,需要构建一个数据治理框架,在经济上促进并保护大家的权力。 人工智能是在海量数据集的…
从行业和企业的角度看,部分领域的数字化和智能化水平发展相对缓慢
随着新一轮科技革命和产业变革蓬勃兴起,数字经济正在加速改变世界。正如强调的:“互联网、大数据、云计算、人工智能、区块链等技术加速创新,日益融入经济社会发展各领域全过程,数字经济发展速度之快、辐射范围之广、影响程度之深…
利用人工智能进行自动决策,将为我们带来更加智慧的路
至于高级人工智能拥有自我意识后,还会听人类的使唤吗?人类该怎么办?真的很难给出答案。或许我们可以通过某种机制避免这样的事情发生,或者禁止创造拥有自我意识的智能机器。 人工智能的最终目的就是为了让人们的生活更美好&am…

计算机毕业设计之SpringBoot+Vue.js租房爬虫数据可视化 租房大数据分析 大数据毕业设计 大屏统计
前端开发框架:Vue,jsecharts
后端开发框架:springboot webmagic mysql
创新点:租房爬虫、大屏统计图
新版本已经二次开发改为spark、hadoop分析数据,很符合大数据的味道

制造型企业为何需要MES管理系统,企业怎样选择合适的MES
MES管理系统是专门针对制造型企业而设计的,能实现对生产车间、工厂信息化管理,帮助制造型企业提高生产效率,加快数字化转型。目前针对制造型企业生产效率、企业竞争力和生产管理状况的需求,MES管理系统已经成为实现生产经营目标的…
ttkefu在线客服即时通信的系统
随着互联网的不断发展,在当前电商平台时代背景下, 智能化管理模式是提升企业核心竞争力的重要手段。智能化的软件作为信息化的重要载体要得到充分的重视,选择一款合适的软件对于企业来说是很重要的。 从企业用户的角度来说,产品的丰富性使得企业在选择上的余地就大了很多&#…
B域,M域,O域具体是指什么
O域(运营域)、B域(业务域)、M域(管理域)特指电信行业大数据领域的三大数据域。 B域(业务域) business support system的数据域,
O域(运营域) ope…
拆分数据库表中某个长字段为几个小字段
直接在数据库层去执行,可借鉴操作语句: //第一句是 在mysql在原字段内容的基础上添加 字符串内容
update tbuser set t.real_nameCONCAT(t.real_name,(贵宾)) where t.real_name张三;//如果执行错误,可以进行还原回来-->Mysql up…
对人工智能算法共谋进行反垄断法规制的根源在于“共谋”行为
对人工智能算法共谋进行反垄断法规制的根源在于“共谋”行为,而非“算法”技术本身。云计算、大数据、算法等信息技术本身是中立的,但这并不意味着其对社会及市场竞争的影响是中立的,它们的性质取决于企业如何使用它们,市场结构如…
专家观点:未来人工智能或许能创造新一轮发展红利
中国人工智能有多厉害,未来机器人都能做手术?可能很多国人还不知道,其实这个看似遥远的技术,已经深入到中国人的日常生活中,打开支付宝,就可以和阿里机器人进行对话,打开手机,就可以…
人工智能人才缺口很大,迫切需要推动人工智能教育体系健康发展
“双减”之后,育人质量如何提升,是很多家长关注的问题。 放学时间普遍从下午3点半调整为5点半,“学生们作业和课外培训压力减轻,时间被争取出来,就是要支持综合素质培养,这反过来就要求创新课堂形式和内…
以人工智能和大数据为核心的第四次工业革命已经悄然而至
智能电网的核心要义是“智能”。近些年,我国在智能电网的物理建设方面取得了显著的成果,但其智能化水平却表现不足。如何进一步提高智能化水平,是发展智能电网急需解决的问题。 以人工智能和大数据为核心的第四次工业革命已经悄然而至。人…
人工智能行业发展新图景,行业关注度与活跃度不断攀升
在投票帖「在安防AI、自动驾驶等人工智能行业中奋斗着的友友们今年会考虑跳槽吗」中,有2146位脉友参与投票。其中803人选择本分上班,706人选择正物色机会,领完年终奖后走,也有600余人因为主动或被动原因已准备离场。 最新发布…
hutool 字符串工具类
//字符串工具类Testpublic void test13(){//判断空,空字符串,以及空格 isempty不能判断空格String a" ";if(StrUtil.isBlank(a)){System.out.println("dddd");}//去除后缀String b"j.a.txt";Console.log(StrUtil.removeSuffix(b,".txt&qu…

鼓励商城优惠券服务模块数据库
谷粒商城优惠券
一、优惠券数据库设计 二、sms_coupon优惠券表,优惠券的信息 优惠券的信息
三、sms_coupon_histor优惠券的领取信息 某个会员在某个订单对应的优惠券使用情况
四、sms_coupon_category_relation优惠与商品分类 优惠券与商品分类的关系
五、sms_c…

IDEA连接数据库,xml写sql没有提示
在xml中写sql,没有提示需要一种去查看字段名,非常低效。我们首先需要再IDEA的Datebase连接上数据库,然后按以下设置就可以了 1. 打开设置 2. 搜索 SQL Dialects 保存既可以了
人工智能落地的时候,落地效率、落地广泛度会更高
人工智能工程化对企业有很多好处,企业在进行人工智能落地的时候,落地效率、落地广泛度会更高。 可以预见,人工智能工程化将会是未来 2-3 年需要持续关注的方向,人工智能工程化应该关注三大核心要点:数据运维、模型…
让业主资源缴纳物业费-捷径智慧物业管理系统
这个小区物业费自愿缴纳率为百分之99,全靠捷径智慧物业系统这个商业模式,让物业公司市值飚增183% 世界上没有一帆风顺的人生道路。只有经历了挫折才会成长。 第一次见到焦翔,很难想象这名瘦弱、看起来有点沉闷的女孩居然是一家拥有超过1000名…
怎么提升业主满意度?捷径智慧物业系统提出解决方案
业主满意度难以提高?捷径智慧物业系统提出解决方案
最近天福小区的物业经理罗先生头痛的不行。
他所属的物业集团总公司最近下发了一个新的要求,每一个季度都要收集所负责小区的业主对物业的满意程度。
虽然罗经理以前没有收集过业主意见,…
捷径智慧物业系统打造真正“学区房”
学区房新要求,文化氛围浓,捷径智慧物业系统打造真正“学区房”
随着时代的发展,我国物业服务市场趋于成熟,也有了长久的发展。
越来越多的物业公司意识到在竞争愈加激烈的市场中想要抢夺先机需要主抓质量,打造优质品…
捷径智慧物业管理系统为社区注入新活力-捷径智慧物业管理
业主服务实现跨越式提升?捷径智慧物业系统为社区注入新活力
江苏省南通市的某江景楼盘去年年底交付了,业主们都满怀着期待的心情入住其中,时间过了不久,有不少业主投诉小区物业未能恪尽职守,导致物业费不能够统一缴纳…
捷径智慧物业管理-为广大住户提供更便捷、高品质的生活。
捷径智慧物业管理系统:以高品质服务助力高品质生活
近年来,智慧物业逐渐成为物管服务新的发展方向。许多小区在引入捷径智慧物业管理系统后好评如潮,所谓的智慧物业服务“智”在哪里?引入这样一个智慧物业平台又有什么意义呢&…
通过这种跨界融合的模式,物业行业正在积极推进智慧社区新模式。-捷径智慧物业管理系统
信息技术助力智慧社区建设,捷径智慧物业系统让业主和物业顺畅沟通
现代物业管理进入中国的时间也有30多年的历史了,在这个过程中,物业管理也随着时代和科技的发展不断改变。
尤其是进入21世纪之后,信息技术正在影响和改变着传统…

盘点十大免费低/无代码开发软件,数字化转型看这里
在数字化日益普及的当下,低代码开发技术逐渐受到大众的追捧。这种技术让缺乏编程经验的大众也能轻松创建应用程序和网站。通过直观的图形界面和拖拽功能,用户可以无需编写任何代码,轻松实现自己的开发需求。本文将为您介绍十大免费的低代码开…

IPA进军城市大脑丨实在智能与银江技术达成战略合作
11月9日,杭州实在智能科技有限公司(简称“实在智能”)与银江技术股份有限公司(股票代码300020,简称“银江技术”)签署战略合作协议。实在智能创始人兼CEO孙林君、银江技术执行副总裁兼董事会秘书花少富,出席…
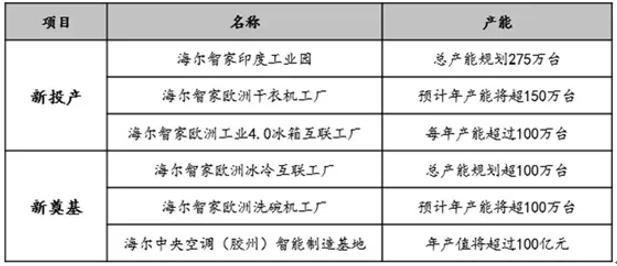
家电行业被迫“大象转身”,破局出路在哪?
家电行业,正在经历一些罕见的变化:一边是产品价格持续上涨,一边是利润率却持续低迷。
来自行业监测机构中怡康的数据显示,2021年的六个月内,国内冰箱市场均价累计平均上涨13%,洗衣机市场均价累计平均上涨1…
elasticsearch in 语句
select * from aaa where id in (1,2,3,4)对应es查询语句
GET /index/type/_search
{"query": {"terms": {"id": [1,2,3,4 ]}}
}对应Java API
Autowired
private RestHighLevelClient client;SearchRequest request new SearchRequest(i…
人工智能技术不断从概念走向应用 智能生活场景特征实现革命性升级
根据国家《新一代人工智能发展规划》的要求,我国在2020-2025年人工智能发展将进入第二阶段,人工智能成为带动我国产业升级和经济转型的主要动力,智能社会建设取得积极进展。 当前人工智能技术不断从概念走向应用,与产业和社会…
头歌Educoder云计算与大数据——实验五 Java API分布式存储
实验五 Java API分布式存储第1关: 利用shell把电商数据上传到HDFS任务描述相关知识HDFS shell常见命令编程要求测试说明代码实现第2关:利用Java API把电商数据上传到HDFS任务描述相关知识常用 HDFS Java接口的使用编程要求测试说明代码实现第1关…

推荐系统——引擎技术栈
典型的推荐引擎架构如下: 具体应用到的技术栈有:
目录 一、ElasticSearch
二、Kafka
三、Flink 一、ElasticSearch
1、简介:
ES是一个实时的分布式存储、搜索、分析的引擎;
2、作用:
对模糊搜索很擅长ÿ…

Kafka的存储详解
文章目录我的疑问:为什么要对主题进行分区 ?Kfaka的备副本为什么不提供读取功能?如何选主的?生产者设置的应答值等于 -1 ,服务端必须等待 ISR 所有副本都同步完消息,才会发送生产结果给 生产者。 消费者或备份副本设置…

数据质量系列文章整理
聊聊大数据质量监控的那些事_诸葛子房的博客-CSDN博客
浅谈网易大数据平台下的数据质量-社区博客-网易数帆
伴鱼数据质量中心的设计与实现 | 伴鱼技术团队 (ipalfish.com)

第一篇:从0到1了解数据库——以MapDB为例
1、MapDB使用
MapDB是一个基于(Apache 2.0 licensed)开源的Java嵌入式数据库引擎和集合框架。他支持针对Map,Set,Queues,Bitmaps 的范围查询,数据过期,压缩,堆外存储和流的操作。MapDB可能是Java最快的数据…
大数据技术应用 第3章管理Oracle数据库
ZHANGQIANYI2020 Oracle-医学信息工程专业3.2 启动数据库与实例3.2.1. 数据库的启动步骤3.2.2. 启动模式3.2.3. 转换启动模式3.3 关闭数据库与实例3.3.1. 数据库的关闭步骤3.3.2. 正常关闭方式(NORMAL)3.3.3. 立即关闭方式(IMMEDIATE…

4.Spark 学习成果转化—机器学习—使用Spark ML的线性回归来预测房屋价格 (线性回归问题)
本文目录如下:第4例 使用Spark ML的线性回归来预测房屋价格4.1 数据准备4.1.1 数据集文件准备4.1.2 数据集字段解释(按列来划分)4.2 使用 Spark ML 实现代码4.2.1 引入项目依赖4.2.2 加载并解析数据4.2.3 对 DtaFrame 中的数据进行筛选与处理4.2.4 特征抽取与转换4.…

数据库表字段、索引 调整
目录 1、表字段
1.1、添加列:
1.2、删除列:
1.3、修改列名/类型
1.4、修改列类型
1.5、修改字段默认值
2、表:
2.1、修改表名
2.2、修改表选项
3、约束:
3.1、查看约束条件
3.2、添加索引:
3.3、修改列的约…

Chapter7 Hadoop架构架构演进与生态组件
7.1 Hadoop的优化与发展
7.1.1 Hadoop的局限和不足
Hadoop在刚刚推出时,存在很多不足。存在的不足如下:
抽象层次低,需人工编码。 很多工作没有办法从高层撰写逻辑代码,必须从最底层进行逻辑编码。即使是很简单的任务都要编写完…

核音智言数据中台,让行业数据“动”起来
一、前言
数据中台不是简单的一套软件系统或者标准化产品,更多的是一种强调资源整合、集中配置、能力沉淀、分部执行的运作机制,是一系列数据组件或模块的整合,为企业数据治理效率的提升、业务流程与组织架构的升级、运营与决策的精细化赋能…

成为独一无二的店铺,用不一样的照明系统让你的品牌脱颖而出!
2020年,社会消费品零售总额为391981亿,受疫情影响,新型消费快速发展,智慧零售进入高速增长期,其中不少大型企业已经加速布局。一时间零售行业硝烟弥漫!线下零售商需要探索全新模式来吸引顾客和改善店内体验…
实验5:MapReduce 初级编程实践
由于CSDN上传md文件总是会使图片失效 完整的实验文档地址如下: https://download.csdn.net/download/qq_36428822/85709497 实验内容与完成情况: (一)编程实现文件合并和去重操作 对于两个输入文件,即文件 A 和文件 B&…

spark2.3在Windows10当中来搭建python3的使用环境pyspark
在python中编写spark的程序,需要安装好Java、spark、hadoop、python这些环境才可以,spark、hadoop都是依赖Java的,spark的开发语言是Scala,支持用Java、Scala、python这些语言来编写spark程序,本文讲述python语言调用p…
实验六 MapReduce数据清洗-气象数据清洗
实验六 MapReduce数据清洗-气象数据清洗第1关:数据清洗任务描述编程要求测试说明代码实现命令行代码文件step1/com/Weather.javastep1/com/WeatherMap.javastep1/com/WeatherReduce.javastep1/com/Auto.javastep1/com/WeatherTest.java第1关:数据清洗
任…
人工智能已被证明在破译古代人类语言方面非常有效 探索动物语言是合理的
你看过《忠犬八公的故事》吗? 这部评分很高的电影,完美诠释了秋田犬小八和主人公帕克之间的情谊。小八每天都想方设法去车站等已故的主人,风雨无阻,一等就是十年。还有不少优秀的影视作品都反映了同一个主题:人和动物的…

解码阿里健康财报背后的“阵形”变化
11月24日晚间,阿里健康对外发布了2022财年中期业绩公告。
期内,得益于供应链、服务、产品等的升级,阿里健康各业务板块均呈现不同程度的增长,推动营收同比增速超30%,不过净利方面的表现却并不乐观。
值得一提的是&am…
武汉人工智能计算中心可支持重大AI应用的模型训练及推理
正所谓“近水楼台先得月”,武汉人工智能计算中心除了为政企提供AI赋能外,还助力大学与科研机构完成重大国家级项目研究。比如武汉大学承担的“大规模遥感影像样本库构建及开源遥感深度网络框架模型研究”项目,基于武汉人工智能计算中心提供的…
数字藏品叠加元宇宙热潮,数字艺术会迎来怎样的发展
NFT(非同质化代币)正在中国快速兴起,当前被人们习惯性称为数字藏品,在叠加元宇宙热潮的背景下,数字艺术会迎来怎样的发展? 1月18日,“第七届中国艺术金融年会”在线上召开,孔中在…

Spring Cloud 快速上手
Spring Cloud 快速上手
maven版本依赖
简介:
单体拆分成微服务:
面向服务拆分
SOA它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。
领域模型拆分
请领域专家来…
赛道“冰火两重天”,捞王上市能否用“清汤”破局?
火锅界的又一巨头发起了对上市的冲击。 9月1日,据港交所披露,粤式火锅连锁餐厅“捞王”递交招股说明书,中金公司和华泰国际担任联席保荐人。
这个夏天,单看资本市场,火锅的表现似乎不如从前沸腾,但事实上&…
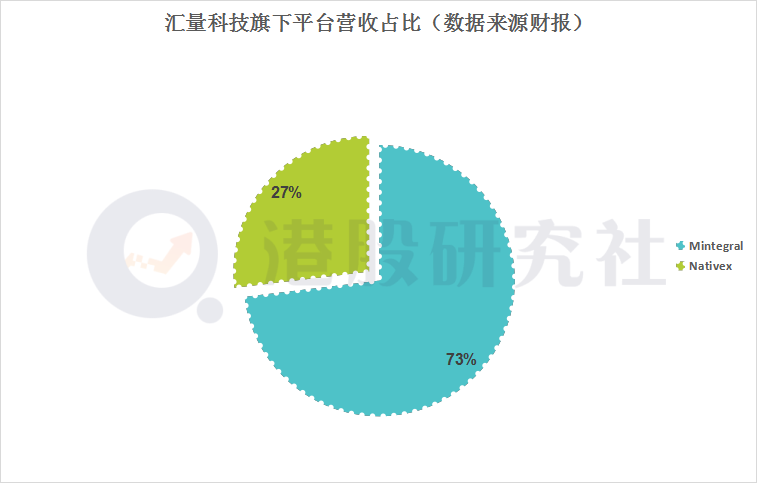
上半年净利由盈转亏,依赖游戏产品的汇量科技能否持续破局?
第四次工业革命方兴未艾,云计算、大数据等技术普及加速了企业数字化转型的推进。
国内MarTech领域一片大热,这也催生一批批赛道玩家的兴起。
8月31日港股盘后,专注营销SaaS玩家汇量科技发布了2021年中期业绩报告。
就基本面数据而言&#…

高级订阅服务成第二增长曲线,能否成为美图的新财富密码?
中国美颜术、韩国整容术、日本化妆术、泰国变性术,一度被网友调侃并称为“亚洲四大邪术”。
中国的美颜类APP高达几十款,如激萌、B612、一甜相机、轻颜相机等,在《2020中国移动互联网年度大报告》的榜单上,美图旗下产品——美图秀…
透过赤子城中期财报:看国内社交出海迎来“分水岭”
出海,似乎成了国内互联网玩家必须迈过的一道坎。
8月25港股盘后,国内最大的社交出海公司赤子城发布了截至今年6月底,中期业绩报告。
就基本面数据而言,营收与净利均实现多倍增长,特别是在净利方面,同比增…
未经解码的语音数据犹如黑盒,同时是非结构化的
这时,他们需要通过分析手中已有的数据,来找到拯救萎靡业绩的方案。而回顾已有数据,企业的唯一法宝,是保存了大量的沟通语音或文本数据。 对于计算机来说,未经解码的语音数据犹如黑盒,同时是非结构化的。…
人工智能技术作为一项新兴技术,毫无疑问可以提高社会生产效率
2021是AI治理极具实质性突破的一年。2022新年初始,由人民智库和旷视AI治理研究院组成联合课题组,中国人工智能产业发展联盟(AIIA)作为课题支持单位,共同发布了《2021年度全球十大人工智能治理事件》(以下简…
人工智能治理的未来:多方参与、协同治理、科技向善
放眼全球,AI治理发展趋于同频。联合国世界卫生组织于2021年6月28日正式发布“世界卫生组织卫生健康领域人工智能伦理与治理指南;联合国教科文组织2021年11月25日正式通过首份人工智能伦理问题全球性协议;2021年4月21日,欧盟首次发…
大数据--hive--经典SQL题目(百度面试SQL题目)
目录 一:题目一:第n多和连续三天思维
1.1 统计近10天每日行为数量
1.1.1 答案:
1.1.2 注意事项:
1.2 行为第三多的用户及其数量
1.2.1 答案
1.2.2 注意事项
1.3 连续3天有行为的用户
1.3.1 思路
1.3.2 答案
1.3.3 注意…


大数据技术实验一-在ubuntu18.04中安装伪分布式Hadoop并使用自带wordcount案例
必要时转载请标明出处 本文是在ubuntu上安装Hadoop的操作,关于如何在centOS上安装Hadoop可参考 https://blog.csdn.net/hgxiaojiujiu/article/details/120382331 实验一 熟悉常用的Linux操作和Hadoop操作
一、 实验目的
(1)掌握Linu虚拟机的…

Hadoop文件基础操作命令
1.查看进程jps
2.进入配置文件(可能路径不同,具体路径以格式化后通知的文件储存路径为主)
[rootmaster ~]# cd /tmp/hadoop-root/dfs/name/current/ 3.改变文件格式,使之可以查看
hdfs oiv -i fsimage_000000000000000000 -o f…

大数据--hadoop生态13--查漏补缺
目录 一:hdfs组成
二:hdfs存储和高可用原理 三:hdfs读写数据过程
四:MapReduce体系结构和执行流程 五:zookeeper介绍 六:flume总结 七:yarn介绍 八:Kafka介绍 一:hdf…
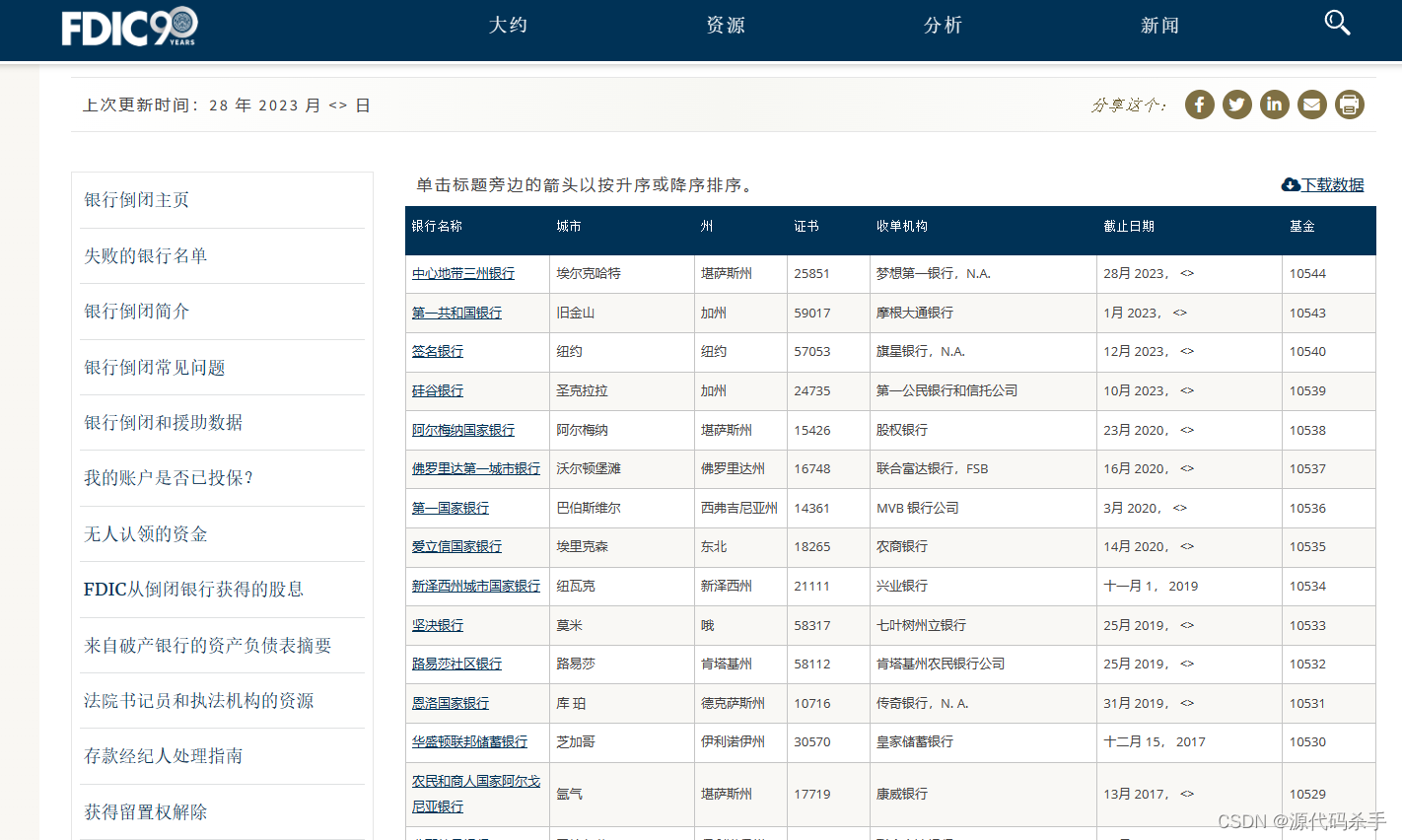
联邦存款保险公司与银行失败和失败银行列表数据集
分享目的:了解M国数据,分析美国银行业和保险行业
美国联邦存款保险公司(FDIC)以及通常与银行失败和失败银行列表相关的一些常见信息。
美国联邦存款保险公司(FDIC):美国联邦存款保险公司是美国…

涛思数据与中天钢铁签署战略合作协议,加速钢铁行业的数字化发展
近日,北京涛思数据科技有限公司(以下简称涛思数据)与中天钢铁集团有限公司(以下简称中天钢铁)正式签署战略合作协议,该协议的签署标志着双方将开启深度合作,共同推动高性能时序数据库 TDengine …


能源管理系统对企业有什么作用?
能源是社会经济发展的命脉,企业是能源消耗主体。随着经济体量的不断增加,能源消耗也是逐年的增加。不可再生资源的存储量日渐的枯竭,可再生资源的占比不是很高并且利用率也是比较低的。所以,节能减排是社会以及企业的的当务之急。…
ElasticSearch range(范围查询)
Range类型设置 Elasticsearch 支持多种范围类型
• 数值类型 • 日期类型 • IP地址类型
1、数字范围
到目前为止,对于数字,只介绍如何处理精确值查询。实际上,对数字范围进行过滤有时会更有用。例如,我们可能想要查找所有价格…
两度冲刺港交所,润歌互动大浪淘沙如何出金?
近期,字节跳动成立抖音集团激起不小的浪花,尤其是该消息出来之后,刺激了不少抖音概念股。据悉A股里的省广集团(002400)、广博股份(002103)、引力传媒(603598)等抖音概念股…
AI正由感知智能时代向认知智能时代迈进
随着科技的高速发展,人工智能时代美好生活的蕴涵人工智能诞生至今,已有几十年的发展历史,经过几十年的发展,人工智能已广泛渗透到人们生活的经济、政治、文化、社会和生态发展的各个领域,人工智能不论对社会的基础设施…
用哲学去思考人工智能需要深度对话和沟通
封面新闻: 不难发现,纵观世界当下各学科,哲学对当代社会出现的各种想象、问题,没有很好地回应,对现代科技进步的发言权和分析能力,影响力也都比较弱,影响力有限。你认可这种观察吗?有人说哲学是…

中文编程最高境界,不用编程,会用excel就会用,香不香?
一直以来,关于中文编程的争议从未消停过。现如今,中文编程发展又是如何? ★为了实现中文编程,从未停下脚步
我们知道,中国人一直以来为了实现中文编程付出了不懈的努力,前前后后研发了几十种中文编程语言。…

高斯单机安装; 磁盘容量不足问题
CentOS7 安装 Gauss DB 200 单节点 - 简书 我安装的时候,将mppdb的目录默认为/srv/BigData/data1,但是该目录又没有分配足够的磁盘,只有50G,数据目录默认也会在该目录下,所以最后磁盘使用率达到了90%,进行磁…

600万用户在用,中国版Access上市,Excel和WPS用户直呼:太棒了
中国版的Access到底有没有?
大家都知道微软的Access功能很强大,作为office里的一款数据库软件,不仅能帮助我们进行数据的分析和处理,而且再深入一点,还可以用VBA实现一些高级的用法。不仅国外有很多用户,就…

QT 连接MySQL数据库的增删改查---云端数据库
在连接数据库前需确保电脑上已装有MySQL数据库,之后添加驱动,确保所写的QT程序能访问到外面的数据库
设置如下 点击添加,你自己创建的数据库信息(ip,端口号等都需对应---注意:这里连接的是云端的数据库&am…

ES 排序,相关度和热度之间的平衡
ES 排序,相关度和热度之间的平衡
算法推荐要达到不错的效果,需要解决好这四类特征:相关性特征、环境特征、热度特征和协同特征。
现在一般使用 ES的 function_score 实现这里的逻辑。 现有的逻辑是先排序 相关度(这里的相关度是经过粗化的结…
SpringBoot配置Kafka的生产者与消费者
SpringBoot配置Kafka的生产者与消费者 1. 配置pom.xml 文件 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> 2. 配置application.properties 文件 #zookeeper连…

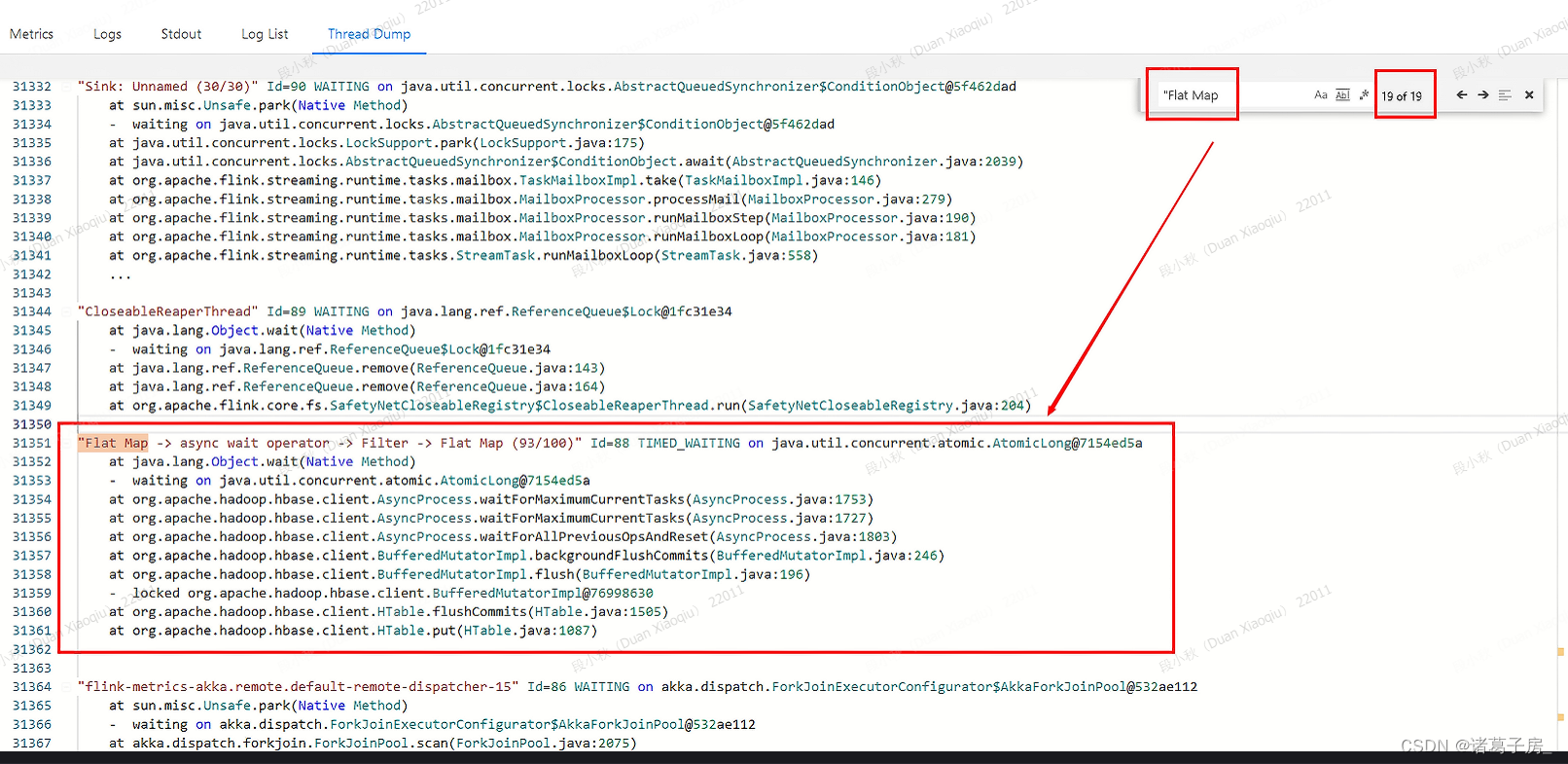
⑦Flink常用核心概念
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存 熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop…

老旧小区改造新思路,捷径物业管理系统打造智慧社区,业主都说好-捷径系统
随着全国上下老旧小区改造如火如荼进行,社区发展迎来新机遇。
共享社区、社区团购等模式不断涌现,社区发展面临多样化、创新化、智慧化,如何把握这些新机遇?
物业作为社区组成的关键部分,在社区发展中发挥着关键作用…
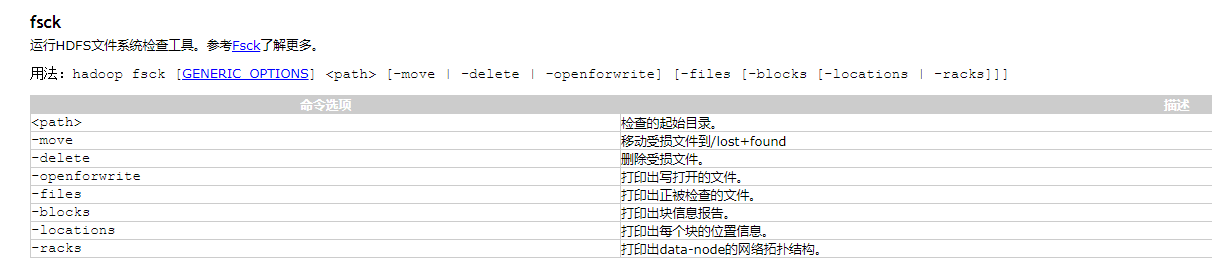
hdfs——简单操作
来记录一些hdfs命令 #将test.txt文件上传到hdfs的根路径下 hdfs dfs -put test.txt / #显示目录内容 hdfs dfs -ls / #显示占用空间 hdfs dfs -du -h / #递归显示目录内容 hdfs dfs -ls -R / #显示文件内容 hdfs dfs -cat /test.txt hdfs dfs -text /test.txt #下载到本地 hd…

数据库原理 第二章 笔记
文章目录二、 关系数据模型关系模型1. 关系数据结构2. 关系操作3.完整性约束二、 关系数据模型 数据库的世界 关系型(MySQL、ORACLE、SQL Server) 表、SQL 非关系型(hadoop、mongoDB、redis、cassandra) noSQL(21世纪特殊需求) …

国企上云新动向,百数可实现“国资云”无缝对接
近期天津市国资委发布《关于加快推进国企上云工作完善国资云体系建设的实施方案》,要求国资企业逐步向国资云平台迁移,受到市场的广泛关注。 国企数据资源属于国有资产,应纳入国资监管和统一管理,保护国有数据资产安全是建设国资云…

用百数,轻松搞定地图数据报表,数据可视化新技能快get
在进行统计分析时,常常会需要分析数据在不同地理区域上的分布情况: 不同区域的客户数、新增客户数分析;
不同区域的销售额分析;
不同区域的门店数量分析;
…
而地图最能直观展示数据的地理位置分布情况。目前的…

百数数据视图——让多表计算变得简单
数据分析汇总渗透到了越来越多的工作环节,无论哪个行业的从业人员,都需要或多或少的具备数据整理分析汇总的能力。传统的表格形式用来汇报或分析都不够直观,通过数据视图功能制作链接各种可视化的数据报表,能够更加清晰明了的展示…

钉钉+百数,为企业解决“控本焦虑”,低成本实现高质量数字化
“每个时代都有特定的生产力工具,不变的是它们始终服务于人。” 因此,数字化转型成为了当下企业拥抱新生产方式的必经之路。在面对客户需求变化、成本结构变化、营销渠道变化、员工素质变化、竞争环境变化的多重压力下,传统企业数字化已经成为…

用户数破5亿,钉钉+百数用低代码的方式践行“两个数字化”战略
今天上午钉钉召开了2021未来组织大会,以“数字生产力,助力组织全链路数字化”为主题,讨论了未来组织的数字化趋势。钉钉总裁叶军在会上宣布钉钉已突破5亿用户,有1900万组织通过钉钉进行日常办公。除此之外,在今年5月官…

百数教培招生管理系统,实现高效数据复盘,提高学员成交率
培训机构市场近年来呈现饱和态势,加上去年“双减”政策出台,大批机构面临转型压力。如何抓住招生先机,需要一套成熟的招生管理系统加持,开展精细化的招生引流工作。 百数低代码平台提供的招生管理系统,能够实现包括学员…

lvs+keepAlived 高效率负载均衡
一、 简介 1. 负载均衡的类型 负载均衡可以采用硬件设备(例如常常听见的 F5),也可以采用软件负载商用硬件负载设备成本通常较高(一台几十万甚至上百万),所以一般 情况下会采用软件负载软件负载解决的两个…
HDFS的NameNode节点信息管理(元数据)
文章目录HDFS的NameNode信息1、NameNode的信息存放地址2、NameNode节点数据查看3、fsimage文件4、edits文件HDFS的NameNode信息
1、NameNode的信息存放地址
NameNode存储DataNode的元数据,NameNode主要是用于维护DataNode信息。它存储在hadoop文件夹下data/dfs/na…
MapReduce之job配置信息介绍
一.job
hadoop中的MapReduce可以使用Java进行MapReduce的逻辑撰写。其中就需要job进行相关配置。job作为MapReduce的配置信息以及启动项直接打包成jar包,hadoop可以运行这个jar包实现mapreduce的功能。本文主要从源码中,将job的配置项信息提取出来&…
利用Java实现HDFS文件上传下载
文章目录利用Java实现HDFS文件上传下载1、pom.xml配置2、创建与删除3、文件上传4、文件下载利用Java实现HDFS文件上传下载
1、pom.xml配置
<!--配置-->
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.c…

物理机重启后ES无法访问
问题:机房断电,重启机器后,Elasticsearch 集群无法访问
集群状态访问如下
可以访问 9200 端口,目测 Elasticsearch 是正常的 但是查看集群状态报错 报错内容
{"error":{"root_cause":[{"type":&…

The Google File System论文理解
原文链接:http://nil.csail.mit.edu/6.824/2020/papers/gfs.pdf
目录
相关背景介绍
框架介绍
设计前提
动作接口
结构
Master作用介绍
ChunkSize设置问题
MetaData介绍
Operation Log和CheckPoint
一致性模型
系统交互
Lease and Mutation Order
Reco…
数据分析上钻,下钻,切片,转轴含义的理解
字面解释
字面意思解释(根本核心是一样的,图表,地图,数据分析BI可能在实际的操作当中有细微的差别,固然暂且说是字面意义): 上钻:从当前数据往上回归到上一层数据。例如:(某数据的分类下面分为品名)从品名列表收拢到分类列表。 下钻:从当前数据往下展开下一层数据…

VRRP的工作原理与理论
VRRP的工作原理与理论
VRRP 概述:也即虚拟路由器冗余协议。利用VRRP-组路由器 (同一个LAN中的接口)协同工作,但只有-个处于Master状态,处于该状态的路由器(的接口)承担实际的数据流量转发任务。在一个VRRP组内的多个路由器接口共用一个虚拟I…

推荐系统 理论笔记 一 (概述 简介 测评)
东西太多了,我们需要推荐系统。 个性化推荐就是你浏览过什么推荐你什么。如果推荐你的是热门内容,那是基于统计的推荐。 电子商务和音乐推荐是不同的,比如过你买了某个物品,短期内你是不想再买的,但是音乐不是&…
【橋本菜菜子】Linux上搭建Hadoop的常见问题
1.1 引言
之前学云计算的时候只是单纯在实验室操作了一下,很多步骤都忘记了,找攻略的时候也很杂,于是记录最近在自己电脑上搭建Hadoop的时候遇到的一些问题以及相关的解决方案。
在安装Hadoop的同时,我发现hadoop-3.x版本中的ha…

近百万条数据、3 秒查询,TDengine 助力北微云平台的搭建
作者:朱永杰 小 T 导读:作为一家聚焦惯性传感技术领域的企业,北微传感致力于让物联世界更美好,其研发的数百种型号的倾角传感器、电子罗盘、航姿参考系统、惯性测量单元、光纤陀螺仪、组合导航等产品,在交通运输、工程…
利用python实现类似数据库中instr功能
#利用python实现数据库中instr的功能.instr(源字符串,目标字符串,起始位置,第n次出现)
#利用instr方法实现对指定字符在指定文本中的位置查找
#二、统计指定字符出现的次数
#三、对出现的字符进行定位
import re
def match_index(str_object,…
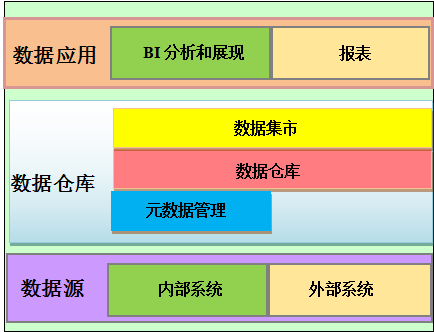
关于数据开发做一些记录
数据开发中,从某种角度而言,主要是对数据的接、管、用。即数据接入,数据管理,数据应用。
在这里主要是先记录一下今天在查询资料时看到的一些理论。 在接入数据时,一般会对数据分为两层来接入。 一、源数据接入&#…
再战港交所的高视医疗,近视小伙伴的福音?
随着经济的高速增长和互联网的快速发展,高强度的工作与快节奏的生活使我们每天都要与手机、电脑一起度过,用眼过度致使人群的眼部问题高发。
目前我国眼科疾病的问题愈发多,眼部疾病患病人数也越发的多。根据2019年第三届中国眼健康大会报告…
头歌Educoder云计算与大数据——实验二 Hadoop单机部署
头歌Educoder云计算与大数据——实验二 Hadoop单机部署答案在下面的链接里 https://blog.csdn.net/qq_20185737/article/details/114677155
实验七 MapReduce编程进阶
实验七 MapReduce编程进阶答案在链接里https://blog.csdn.net/weixin_45818379/article/details/117790528

Excel 电商数据分析实战一
首先我们简单的了解一下源数据结构 该表格包括了美团和饿了么两个平台下不同门店的销售信息,包括下单转换率,门店曝光人数,CPC总费用等。
在拿到数据之后,我们首先确定分析主题,即分析门店CPC总费用与门店下单转化率…
云计算与大数据技术应用前四章知识点整理
第一章云计算概论 1.1什么是云计算 1.1.1云计算的定义: 定义:指按需使用IT资源和应用程序,通过互联网、按使用量付费。 像水电煤(资源性产品)一样利用你的IT资源,计算存储网络资源。 有三个关键词ÿ…
elasticsearch: 查询过滤某个字段值的长度
script字段值过滤
查询indexName索引中,name‘测试’ && fieldName字段值的长度>2的文档 注:如果fieldName字段类型是text,则需要fieldName.keyword
GET /indexName/_search
{"query": {"bool": {"mus…
途牛:一直被唱衰,就是没倒下
比连续多年亏损更让人吃惊的,是途牛仅剩2亿美元市值。当初率先打出1元游的价格战,用高额补贴和巨额营销费用获取市场,当烧掉的钱却没有带来应有的市场规模,途牛没有发展,只是挣扎求生存。
远在2016年,新闻…

spark源码之环境准备
我们使用yarn集群作为研究 spark环境准备yarn环境准备启动Driver启动Executoryarn环境准备
spark的入口类是SparkSubmit,在这里,我们开始提交参数 这里的args就是--class这些的。 解析好这些参数后,我们会返回一个SparkSubmitArguments的一个…

Spark介绍(学习笔记)
夫君子之行,静以修身,俭以养德,非淡泊无以明志,非宁静无以致远。 夫学须静也,才须学也,非学无以广才,非志无以成学。淫慢则不能励精,险躁则不能冶性。 年与时驰,意与日去…

儿童口腔卫生:建立健康微笑的基石
引言
儿童口腔卫生是维护健康的关键部分,它不仅影响口腔健康,还对全身健康产生必然影响。本文将探讨一些儿童口腔卫生的重要性以及儿童的关键注意事项,以帮助家长和监护人确保儿童拥有健康的口腔。 第一部分:儿童口腔卫生的重要性…

云表|低代码开发是否真的靠谱?一试便知
最近,“低代码”这个概念在技术圈里火了起来,引发了广泛的讨论。一些人对其赞不绝口,认为它具有诸多优点,如减少开发周期,提高系统开发效率,降低开发成本,学习成本低等。他们甚至预测࿰…


Kafaka学习总结
kafka简介
kafka是一个应用比较频繁的分布式消息系统,使用scala语言开发,基于zookeeper进行协调,多分区、多副本;
它的特性是高吞吐、可持久化、可水平扩展、支持流数据处理,它具备三大功能:
消息系统&a…


谁说菜鸟不会数据分析大框
目录 第 1 章:确定分析思路 数据方法论 常用的数据分析方法论 第 2 章:数据准备 理解数据 数据来源 第 3 章:数据处理 数据清洗 重复数据的处理 缺失数据处理 检查数据逻辑错误(使用if函数) 数据加工 第 4章ÿ…

电力价格如何推动数据迁移到网络边缘
以下文章来源于康宁光通信,转载自作者康宁光通信 随着数据量的增长,网络需要更多的电力才能高效运行,超大规模数据中心和云数据中心可以在效率和成本效益之间实现平衡,边缘计算技术通过提供低延迟、可靠的数据传输以及成本…
①Flink应用场景和模型构建,核心特性
Flink 自从 2019 年初开源以来,迅速成为大数据实时计算领域炙手可热的技术框架。作为 Flink 的主要贡献者阿里巴巴率先将其在全集团进行推广使用,另外由于 Flink 天然的流式特性,更为领先的架构设计,使得 Flink 一出现便在各大公司掀起了应用的热潮。 阿里巴巴、腾讯、百度…

数据治理开启篇(总结)
有幸参加大型集团级数据治理工作,三年的治理过程中有太多认知和方法上的改变可以总结,但是同时也存在太多不足。治理方法论建立 之前从技术到产品、更多的是管理工具和能力的建设,没有在企业级内部的数据治理经验,针对性的学习了很…
Yt的Hive参数调优(Hive on Spark)
PS:Spark集群会启动Driver和Executor两种JVM进程。Driver为主控进程,负责创建Context,提交Job,并将Job转化成Task,协调Executor间的Task执行。而Executor主要负责执行具体的计算任务,将结果返回Driver
#设置这个spark任务名称
set spark.app.name=fun_seamless_newGP133…

Hadoop相关面试题总结
Hadoop常用端口号:
dfs.namenode.http-address:50070
dfs.datanode.http-address:50075
SecondaryNameNode辅助名称节点端口号:50090
dfs.datanode.address:50010
fs.defaultFS:8020或9000
yarn.resourcemanager.webapp.address:8088
历史服务器w…
MySQL关系型数据库存储引擎、事务、索引、视图、范式等相关总结
MySQL约束包括哪些?
主键约束外键约束不能为空(not null)唯一(unique)
一、存储引擎
1.什么是存储引擎,有什么用
存储引擎是MySQL中特有的一个术语,其他数据库中没有。存储引擎是一个表存储…
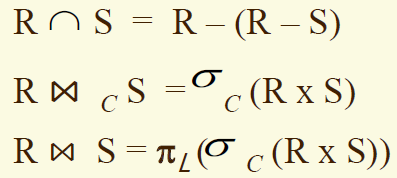
数据库原理 第三章 笔记
文章目录三、关系代数1. 什么是关系代数2. 关系运算符分类传统的集合运算专门的关系运算符辅助专门的关系运算符3. 等价运算4. 关系运算符的优先级三、关系代数
关系数据查询语言
关系代数,关系演算等(Formal,不用于现代商用的DBMS中&#…
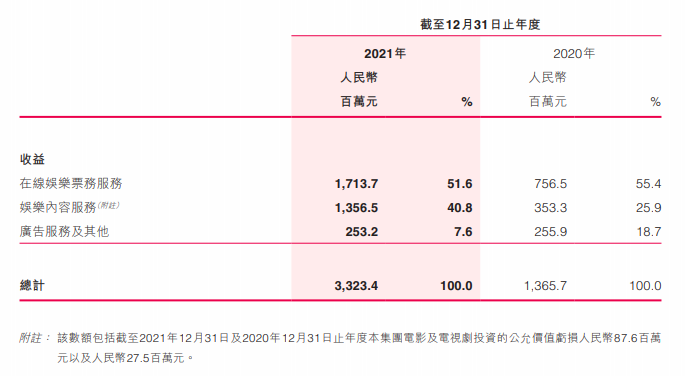
影片相继撤档“520”,在线票务平台等待下一个“黄金档”
今年“520”黄金档爱情电影市场和4月份如出一辙,依旧冷清。
5月13日和5月15日,《可不可以不要离开我》《暗恋橘生淮南》两部影片相继宣布撤档;5月16日,电影《爱犬奇缘》官微发布通知宣布将延迟公映。
客观原因不用多说ÿ…
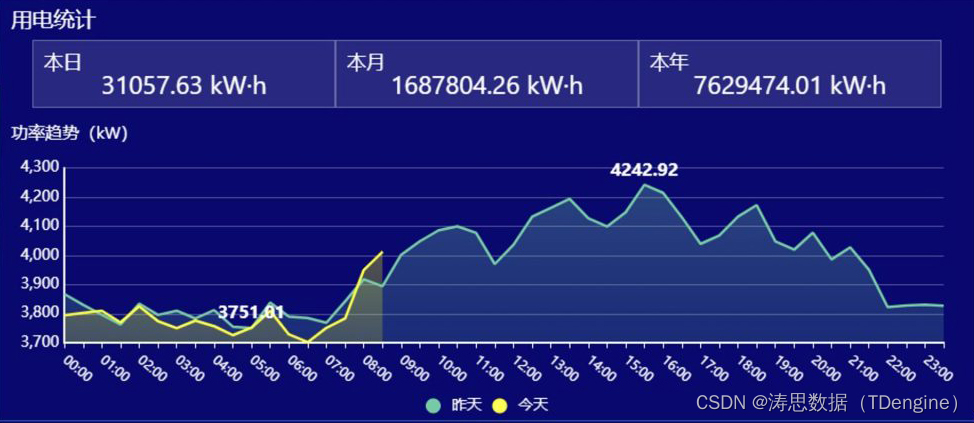
写入速度提升数十倍,TDengine 在拓斯达智能工厂解决方案上的应用
小 T 导读:在拓斯达的智能工厂整体解决方案项目中,传统的关系型数据库已经无法高效处理时序数据,在加载、存储和查询等多个方面都遇到了挑战,最终他们选择了 TDengine 来匹配工业传感器数据的应用分析场景。本文将讲述他们应用 TD…

MapReduce开发流程及示例
文章目录MapReduce开发流程(1)输入数据接口:InputFormat(2)逻辑处理接口:Mapper(3)Partitioner分区(4)Comparable排序(5)Combiner合并…

基于Flink实时数仓——DWM 层-支付宽表(5)
需求分析与思路 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况。 所以本次宽表的核心就是要把支付表的信息与订单宽表关联上。
解决方案有两个:
把订单宽表输出到…

实在智能RPA@香港驻上海办事处:点赞RPA机器人新优势
11月24日,中国香港特别行政区政府驻上海办事处副主任巩连全莅临实在智能。现场,巩副主任对实在智能在RPA技术领域取得的一系列成果给予肯定,双方在数字化转型与升级方面达成共识,并将积极探索IPA合作新方向。 实在IPA数字员工
数…
拼多多为什么要致力于知识普惠?
“书中自有黄金屋,书中自有颜如玉。”自古以来,我国对于读书都极为重视。《周易》《山海经》等著作蕴含着古代先人对万事万物的探索,《三字经》《论语》等著作讲述着先贤关于做人做事的道理总结。得益于从古至今的书籍记录,对知识…
抖音电商:刷短视频一样刷淘宝
一直以来,大厂基因诅咒口口相传,腾讯没有电商基因,阿里没有社交基因,企业优势也成为企业的掣肘。
今日头条之后,字节跳动发力短视频,成功找到流量第二增长极。然而,流量变现之路,最…
平安好医生掉队,是选了更难的那条路
从千团大战、在线旅游,到外卖平台、网约车,互联网的出现,改变了人们的生活方式。
通过补贴来培育用户习惯,通过“烧钱”获得规模效应,经过互联网的点石成金,无数传统行业或者被颠覆,或者焕然一…
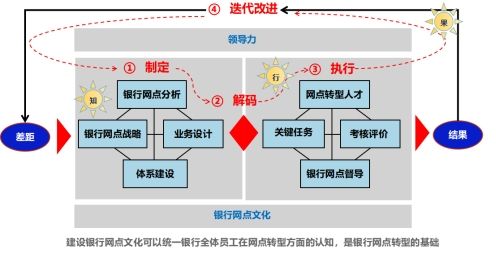
银行数字化转型导师坚鹏:数字化时代BLM银行网点转型解决方案
数字化时代BLM银行网点转型实战解决方案
——以BLM模型为核心,实现知行果合一
课程背景:
很多银行存在以下问题:
不知道银行如何进行网点转型?
不清楚其它银行网点战略是如何制定的?
不知道其它银行网点转型是如何取…
大数据开发的前景和就业如何?该如何去学习它?
学习大数据可以从事很多工作,比如说:hadoop 研发工程师、大数据研发工程师、大数据分析工程师、数据库工程师、hadoop运维工程师、大数据运维工程师、java大数据工程师、spark工程师等等都是我们可以从事的工作岗位!不同的岗位,所…

人工智能Java SDK:人工智能技术如何与大数据技术栈协同工作?
人工智能技术如何与大数据技术栈协同工作?
人工智能模型训练很大程度依赖标注的数据。而需要标注数据量大的话,离不开大数据平台提供技术支持。 训练好的模型,反过来同样可以用于大数据技术栈。
场景1:ToB
在企业内部的大数据平…
生于流量的直播行业,会因为流量的见顶而陷入困局
1、当李佳琦们开始做品牌,是直播带货行业的发展开始逐步走向正规化、专业化的开始。 同样地,它也是直播带货行业的红利开始出清,真正进入到新的竞争阶段的标志。 今年只是一个开始,未来,我们还将会看到更多的网红主播&…
计算机领域中“透明”的意思,以数据库关系模式缺点等为例
计算机中的“透明”与现实理解的透明是反着来的。意思:不可见
如: 关系模型的特点的其中一条特点为:存取路径对用户透明。 其实就是存储路径用户看不见。
还有计算机网络中体系结构知识点: 本层的服务用户只能看见服务而无法看见…

政务RPA:属于你的实在数字员工
数字化时代,新技术带来的复杂变化对基层政务管理水平和综合服务能力提出了更高要求。
长期以来,基层政务服务中涉及大量的系统报表、数据填报等工作严重依赖人工手动操作。对于政务服务窗口工作人员而言,每天大部分时间和精力都花费在了高重…
简单理解parquet文件格式——按列存储和元数据存储
简介
Apache Parquet是一种常见的列式存储文件格式,常用于Pig, Spark, Hive等大数据组件中,其后缀是.parquet。
核心特点有:
跨平台可被各种文件系统识别的格式按列存储数据存储元数据
下面详细介绍第3、4个特点。
列式存储
假设有以下…
人工智能就是更高级的、直接产生价值的智能
通常,人们常把人工智能分为感知智能、分析智能和决策智能。用王明明的话说,从人类发展来看,机器是肢体的延伸,决策智能是大脑的延伸。 新商业学院主编的《数智驱动新增长》一书中这样描述决策智能:基于自动化和设备的智…
AI与教育相遇 努力实现“散播科学的种子
2019年,首都师范大学人工智能教育研究院宣告成立,这是全国高校首家人工智能教育研究院。而首师大附中,成为青少年人工智能活动开展的先行者。 在首师大附中,“青牛创客空间”是学校的标志性建筑,学生可以在此进行智能产…
人工智能需要兼顾科研创新与应用创新
个技术负责人的最大欣慰是看到自己所坚信的技术能够创造出商业价值。王明明是其中的幸运儿。“我们的产品模式选择SaaS、aPaaS模式,从商业上、财务上都证明了我们是正确的。” 萨摩耶云对智能决策科学的探索和运用,并非停留在实验室阶段。其智能决策兼顾…
衍生于电商行业的直播带货竞争开始进入到白热化的主要标志
对于这最后一块热土的透支,成为了网红主播们做品牌的内在驱动力。 从另外一个侧面来看,网红主播们做品牌的背后,真正反映出来的是电商行业的退潮。 这是电商行业的竞争开始进入到白热化的标志,网红主播们为了获得商家和消费者的流…
linux数据库定时备份
1. 查看磁盘空间情况
使用 df -h 目前磁盘空间和使用情况 2. 创建备份目录
尽量选择空间比较充足的目录,这里以/home目录为例保存备份文件; 进入到/home目录下,创建backup目录,并进入到新建的backup目录下
cd /home
mkdir back…
从数字产业化到产业数字化,今天的数字经济已经进入到深水区
封面:有专家认为,元宇宙将成为各国数字经济的竞争高地,您怎么看待数字经济发展和人工智能等技术的关系? 娄超:对于数字经济的发展,我感触最深的是,从数字产业化到产业数字化,今天的数…
Linux安装配置awscli命令行接口工具及其从aws上传下载数据
官网技术文档有全面介绍:安装或更新 AWS CLI 的最新版本 - AWS Command Line Interface在系统上安装 AWS CLI。https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/getting-started-install.html#getting-started-install-instructionsawscli常用命令参考&…
云计算巨头,拒绝只在天上“飘”
如何形容当前的云计算市场?或许是一面红海,一面蓝海。红海是资本市场热捧,云计算的热度、玩家们的身价水涨船高。蓝海是渗透领域和模式不完善,IaaS等基础服务占据了大部分份额,而互联网依然是主要布局阵地。
但无论是…

数字化时代下,制造业企业应该这样做仓库管理
透过现象看本质,在传统的仓储管理中都存在着以下问题: 1.信息化水平较低,以人工为主,以纸张为主,效率低下,容易出现错误; 2.信息流的不对称性,各个过程之间的联系不紧密,…

数字化转型导师坚鹏:银行如何建设行业领先的人才培训管理体系
数字化转型浪潮下银行如何建设行业领先的人才培训管理体系
——以推动银行战略落地为核心,实现知行果合一课程背景:
很多银行都在开展银行人才培训工作,目前存在以下问题急需解决:
缺少针对性的银行人才培训体系
不清楚如何建立…

不打补贴战,快狗打车凭什么冲刺“同城货运第一股”?
同城货运终究跑出了第一股。2月6日,快狗打车率先通过聆讯的消息传来,同城货运行业或许是最为振奋的。因为一家成熟公司的亮相意味着,经过漫长的建设周期,行业正朝着更加规模化、精细化、数字化的方向发展。
新的路途不一定一帆风…
大象转身牵一发动全身,阿里推猫享不仅仅对标京东
十年前,阿里并不认可自营生意。十年后,天猫自营旗舰店来了。
2011 年,阿里创始人马云在淘宝全员沟通会上称阿里跟京东的竞争是两个商业模式的竞争,他不认为京东这样的商业模式会持久发展得很好。
2022年2月16日,据《…

五五规划首年“开门红”,特步离跻身第一梯队还差几个五年?
3月16日,特步发布实施“五五规划”以来的首个年度财报,创下人民币100.13亿元的纪录,集团收入首次破百亿。
财报数据显示,2021年全年,特步主品牌的收入增长强劲,创下88.41亿元的纪录同比增长24.5%。净利润9…

Apache Hive3.1.3 遇到DATE_FORMAT转换2021年12月格式的问题
比如:需要将时间2021-12-28 00:00:00转换成2021-12的格式,用date_format会将2021-12转换成2022-12的问题。
解决方法:
方式一:大写的‘Y’换成‘y’ 方式二:字符串截取,substr
本博主推荐方式一…
未来几年人工智能会迎来哪些激动人心的改变
未来几年人工智能会迎来哪些激动人心的改变? 多样性可能是目标之一。 早在几年之前,关于AI多样性这个概念有过一些解释——报道说韩国人习惯于睡地铺,但扫地机器人按照之前设定好的程序,不小心把一位睡在地上的客户的长头…

QT简易版学生信息管理系统(mysql数据库--增删改查功能)
代码如下
登录界面功能实现:
from1.cpp
#include "form1.h"
#include "ui_form1.h"
#include "widget.h"
#include "ui_widget.h"
#include "newuser.h"
#include "ui_newuser.h"
#include <QMe…
实时数仓中维度数据为什么采用HBase?
为什么不使用Redis? 维度中user用户维度数据量大。 为什么不使用MySQL? 并发压力太大了,因为MySQL中的表本来就和用户打交道,响应用户请求,增删改查,再用它去查维度数据就没必要。 除此之外还可以选择ES,这主要取决于…
【快手备注发货接口】在拼多多上开店需要准备什么?如何开通拼多多店铺
天越来越多的人喜欢在拼多多上面买东西,因为真的很便宜,还能和亲戚朋友们一起砍价,看到拼多多如此迅猛的发展趋势,不少人看准了苗头,开始在上面开店,而无论是在淘宝还是拼多多,货源都是开店最重…

实在智能告诉你RPA技术如何做到“一夫当关,万夫莫开”
RPA即机器人流程自动化,是英文Robotic process automation的缩写,它通过模仿最终用户在电脑的手动操作方式,提供了另一种方式来使最终用户手动操作流程自动化。它的出现不是偶然的,是顺应时代潮流应运而生的,如果说蒸汽…

基于Flink实时数仓——DWS 层的设计访客主题宽表(6)
DWS 层的定位是什么 轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。 DWS 层-访客主题宽表的计算 设计一张 DWS 层的表其实…
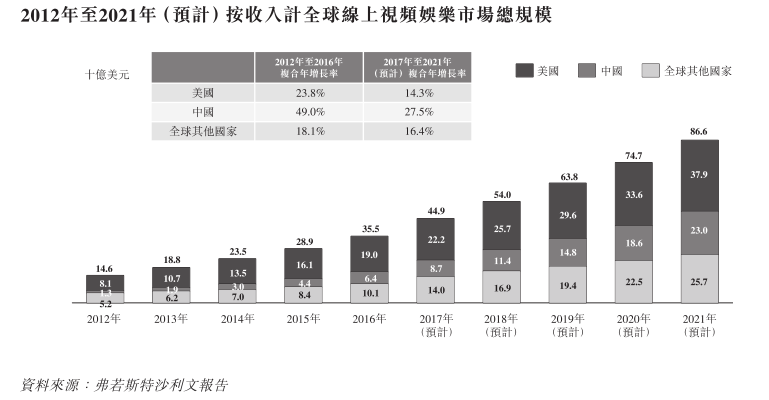
纳入深港通,阜博集团的前程稳了吗?
以一秒拍、小咖秀、美拍为起点,短视频平台逐渐进入人们的视野,这一传播形式开始被大众所接受。而后国内短视频行业中形成抖音、快手双寡头市场,短视频正超越长视频成为新兴主流媒体形式,但伴随而来的侵权问题也一直备受关注。
作…

热评云厂商:青云科技4.29亿元,重研发押注更大发展
全球云观察《云白皮书(2020-2021)》热评云厂商60家之四十七 虽然青云科技在2020年未能上市,但是在2021年3月正式IPO之后,财报数据都可已经公开发布。据财报数据显示,2020年实现营业总收入4.29亿元,同比增长…

ElasticSearch基础之 权威指南笔记(三)
集群内的原理
ElasticSearch 的主旨是随时可用和按需扩容。 而扩容可以通过购买性能更强大( 垂直扩容 ,或 纵向扩容 ) 或者数量更多的服务器( 水平扩容 ,或 横向扩容 )来实现。
虽然 Elasticsearch 可以获…
Azkaban的安装部署
文章目录一、Azkaban二、安装部署1、安装包准备2、安装Azkaban1.解压安装包2.文件重命名3.azkaban脚本导入3、生成密钥对4、相关配置1.修改时区2.Web服务器配置3.增加管理员用户4.执行服务器配置5.启动服务一、Azkaban
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度…
大数据调度工具之Oozie
文章目录一、oozie1、Oozie模块1.Workflow2.Coordinator3.Bundle Job2、Oozie的常用节点1.控制流节点(Control Flow Nodes)2.动作节点(Action Nodes)二、Oozie安装1、配置maven环境1.打开文件2.输入以下内容4、验证maven仓库是否配…
千亿赛道群雄逐鹿,口腔医疗服务商们如何做长远品牌?
消费与投资之间,有着千丝万缕的联系。
尤其是随着人们生活水平的提升,在颜值经济的风口上,年轻人的“整牙自由”,也酝酿出了千亿的风口。而在这个风口下,也跑出了不少上市公司。
通策医疗、时代天使、瑞尔集团、现代…
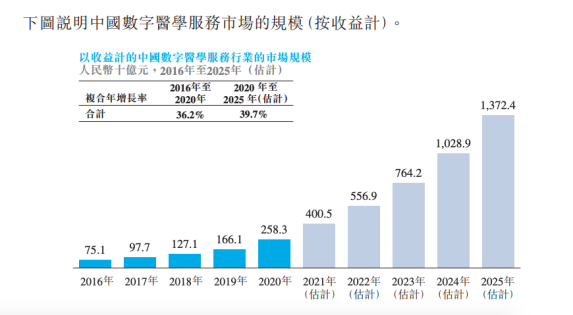
数字医疗“疫”外增长,梅斯健康上市抢跑?
马云曾说:“中国下一个首富,一定在大健康领域。”
如他所判断的,当下医疗健康领域存在的投资机会逐渐清晰。《2021中国大健康趋势发展报告》也称,未来十年,最好的医疗健康产业机会在中国。
与这个论点相对应…

实在智能RPA助你提升电商运营效率,快速起爆店铺
摘要:实在智能RPA致力于电商运营自动化解决方案研究,对于智能电商、自动化运营等领域有着专业、深入的研究。针对淘宝、天猫、京东、拼多多以及亚马逊、速卖通、虾皮等国内外主流电商平台,实在智能RPA推出了对应的解决方案,能够在…


Hbase使用CopyTable进行数据复制和迁移
最近有一个需求,是将Hbase表中的数据复制到另一张表中,因为Hbase的数据比较多,通过java程序读出来然后再向数据库中插入的话,是不太现实了,只能寻找另外的工具,搜了一下原来Hbase自身就提供了相应的组件&am…
人工智能行业作为冲击全球科技创新前沿的重要着力点,开启了行业发展的新图景
2021年是“十四五”规划的开局之年,人工智能行业作为驱动数字中国与科技强国创新发展、冲击全球科技创新前沿的重要着力点,开启了行业发展的新图景。 与互联网大厂打工人所经历的腊月隆冬不同,2021年,人工智能行业在政策与资本…

金融RPA:你工作中的RPA机器人王器
目前随着金融行业的不断创新与发展,基金业务处理程度也越来越复杂。使得目前许多的基金行业业务量和工作量强度持续升高。造成人工的巨大压力。在此背景情况下,我们必须采取先进的金融科技手段,将员工从这些繁琐的工作量里面释放出来…
数据湖:Hudi构建中台
Hudi和DaltaLake对spark强绑定,建议使用Saprk。用Flink的话可能要改源码
三个开源数据湖技术:
都支持多数据格式,流批一体,acid语义保证,支持table schema delta:绑定了spark(一家公司&#x…
Hive中常出现的错误(不定时更新)
1.加载数据失败 hive> load data local inpath /home/user/hive.txt into table studentl> ;
FAILED: SemanticException [Error 10001]: Line 1:56 Table not found studentl
hive> load data local inpath /home/user/hive.txt into table student;
Loading data to…
拼多多店铺爆单小技巧,拒绝没有店铺没有流量的烦恼
当前入驻拼多多的商家是越来越多,很多新手商家第一次接触电商行业,当遇到店铺没生意时会比较的迷茫,不知道该怎么办?下面就来讲解一下店铺没流量、没销量时该如何处理: 一、提升店铺新产品: a、标题&#x…
【订单旗帜接口、备注接口】拼多多商家运营小技巧,新店必看小技巧
一、商家如何选款 拼多多开店最重要的就是选款,并且选款一定要选上升空间大的产品,温馨地提醒一下商家,切记不要看别人哪款商品卖得火爆就选哪款商品,要知道别的商家已经卖得很好的爆款你再拿来买,那么店铺流量会少很多…
“对立论”主要着眼于人工智能技术与人类权利和福祉之间的对立冲突
国外在大力推动人工智能技术和产业发展的同时,高度重视人工智能的安全、健康发展,并将伦理治理纳入其人工智能战略,体现了发展与伦理安全并重的基本原则。 国家高度重视科技创新领域的法治建设问题,强调“要积极推进国家安全、…
实在智能签约美妆爆款品牌「逐本」,数字员工助力电商华丽升级
“每卖出2.4瓶卸妆油,就有1瓶是逐本。” 2021年双十一,逐本同时登顶天猫、抖音双平台卸妆类目TOP1,高基数、高增长的态势,成为了美妆TOP新品牌。 近日,实在智能签约逐本,助力国潮新势力实现数智化全面升级。…

实在智能牵手「国货之光」纳爱斯,为中国智造插上数字化翅膀
十四五规划以来,数字化逐渐从行业头部企业的“可选项”转变为“必选项”。近日,实在智能签约日化行业巨头纳爱斯,实力推动制造业龙头企业智造升级。 纳爱斯集团是中国日化行业的领军企业,是“大国品牌”先行者。一直以来ÿ…
任何一种思维能力的形成都离不开实践和练习,编程作为一种语言工具更注重实践操作
聚焦行业尖峰论坛,启迪人工智能未来发展。2021新一代人工智能院士高峰论坛暨启智开发者大会在深圳隆重开幕。作为行业高水平的压轴学术盛会,本届大会聚焦AI开源开放平台、云际互联、智能应用等前沿技术动态,集中讨论国家新一代人工智能开放创…
音乐人工智能的研究领域非常广泛,全世界没有专门研究人工智能的学校
未来,音乐机器人、虚拟机器人对于我们音乐表演、交互、音乐娱乐将会有重要的好处,我们目前正在做一个音乐教育方面的音乐机器人。大家知道,全世界的音乐教育师资缺乏,特别是偏远地区专业的音乐老师非常缺乏,甚至有些地…
无代码人工智能可以在几分钟内分析多年的数据并提供关键的见解或预测
无代码AI方法 当整个组织中的个人开始在日常职位中使用数据时,就会出现一个称为“数据民主化”的术语。这些人不是统计学家、数学家、数据工程师或数据科学家。事实上,他们对数据根本不感兴趣;他们只对数据能告诉他们什么感兴趣。 技…
Java和Java大数据有哪些区别?
单独提起Java或者大数据,很多人对此都略知一二,但对于Java大数据这样一个名词,多少有些疑惑。那Java和Java大数据学习的内容是一样的吗?两者有什么区别呢?今天就从Java和Java大数据的以下方面谈谈两者的区别。
Java和…
基于人工智能的观察力可用于提高产品质量并更好地满足客户需求
人工智能技术为人类带来了很多福利,但与此同时,许多人认为这项技术所带来的风险可能会超过它所具有的好处。 当然,问题并不在于人工智能本身,而在于我们使用它的方式。这就是达伦阿西莫格鲁教授所持的观点。他在2013年出版的著…
AI的溯因推理和未来道路 终将克服自身限制并取得新的突破
包括强化学习的先驱理查德萨顿(Richard Sutton)在内的一些科学家认为,我们应该坚持使用能够随着数据和计算的可用性而扩展的方法,即学习和搜索。例如,随着神经网络变得更大,接受更多数据的训练,…
人工智能在各个应用领域有很广拓展 促进科研范式和业态重塑
“现在前沿科技将给人类生活带来巨大的收益和便利,但科技发展同时还要有人文关怀,去主动解决新兴技术研发与应用带来的风险与挑战。”11月28日,清华大学苏世民书院院长薛澜在第十九届《财经》(博客,微博)年会“《财经》年会2022:预…
促使人工智能的研究路径从专家系统研究向深度学习研究转变
虽然贝叶斯网络在因果关系分析中能够发挥重要作用,但它无法准确解释因果关系,为了提升对因果关系描述的精准度,珀尔提出了因果关系的数理框架——结构因果模型。利用结构因果模型可以检验复杂因果关系,结构因果模型的主要组成部分…
概率和因果性推理演算法,改变了人工智能最初基于规则和逻辑的发展方向
“贝叶斯网络之父”、美国计算机科学家和哲学家朱迪亚珀尔(Judea Pearl)以在人工智能领域的基础性贡献而知名。他提出概率和因果性推理演算法,改变了人工智能最初基于规则和逻辑的发展方向,并因“研发与概率和因果推理有关的算法而…
AI研发作为科技前沿技术,AI创新备受关注
中国AI研发作为科技前沿技术,AI创新备受关注。国家工业信息安全发展研究中心、工业和信息化部电子知识产权中心从2018年开始,每年都会发布人工智能专利分析报告。2021年报告的主题为《中国人工智能高价值专利及创新驱动力分析报告》(以下简称…
人工智能是人类创造的工具 缺乏能够构建高效系统的天才专业人员
公司必须从商业角度来考虑问题。自问一下问题: 你想解决什么商业问题? 界定成功的衡量标准是什么? 回答完这些问题后,再决定用哪种技术来解决问题。请记住,人工智能包含了很多技术,比如机器学习…
人工智能正驱动汽车行业种种变革 挑战也随之而来
打造差异化设计实现可持续性发展 尽管人工智能正驱动汽车行业种种变革,但随着技术难度不断攀升,挑战也随之而来。据了解,市场对于智能驾驶的期望与技术创新之间的鸿沟,已经成为自动驾驶企业发展面临的最大挑战之一。因此&…
汽车行业如今成为了人工智能发展的重点方向之一
人工智能技术来势汹汹,与各行各业进行着种种结合,汽车行业如今成为了人工智能发展的重点方向之一,各大高科技公司纷纷入局智能汽车产业。随着人工智能技术的不断发展,在汽车领域掀起了一场场技术革命,这也给汽车厂商们…
人类是否真的能控制人工智能仍然是一个未知数
许多思想家声称人工智能永远也不能自主完成任务,因为它必须由人类编程。因此,人类将永远控制着人工智能。但事实真的如此吗?我们不妨简单地回想一下当前最常见的人工智能形式,即深度学习神经网络。这种人工智能已经被视为一个“黑…
人工智能的研究经历了多次潮起潮落 但目标依然明确
“此次获奖不仅是对我个人的肯定,更是对我们整个科研团队的肯定。我们将继续攻坚克难,让人工智能领域的中国声音愈发响亮!”2020年度陕西省最高科学技术奖获得者、中国工程院院士、西安交通大学教授郑南宁说。 郑南宁是我国人工智能领域发…
蝴蝶能够承载的信息够多在消耗算力上也很合理及优秀
关于《虚拟蝴蝶》系列,您强调的是计算机的学习能力和虚拟演化,它们能够创作出比自然界还要多的物种,并且只要愿意,便可以持续不断地生成。艺术家在这个过程中,扮演了仿佛“上帝之手”的选择的角色(自然选择…
文本基因计划涉及人工智能相关的一些技术跟理念
能否简单聊一下这次展览与策展人的合作过程?策展人是如何从您的众多作品中选择《文本基因计划》( 2018~2021)和《虚拟蝴蝶》(2019~2021)的? 跟艾厂的策展人合作是很顺利的,因为上面说到的两个项目都有涉及…
为什么现在的淘宝搜索流量越来越难做
在过去,搜索流量是刚需,到店的流量数绝大多数取决于店铺搜索是否精准,而当下千人千面的推荐算法给每个人都匹配到不同的内容,随着用户需求的弹性升级,产品变得日渐多元。传统的搜索流量获取已经无法满足店铺增长的需求…
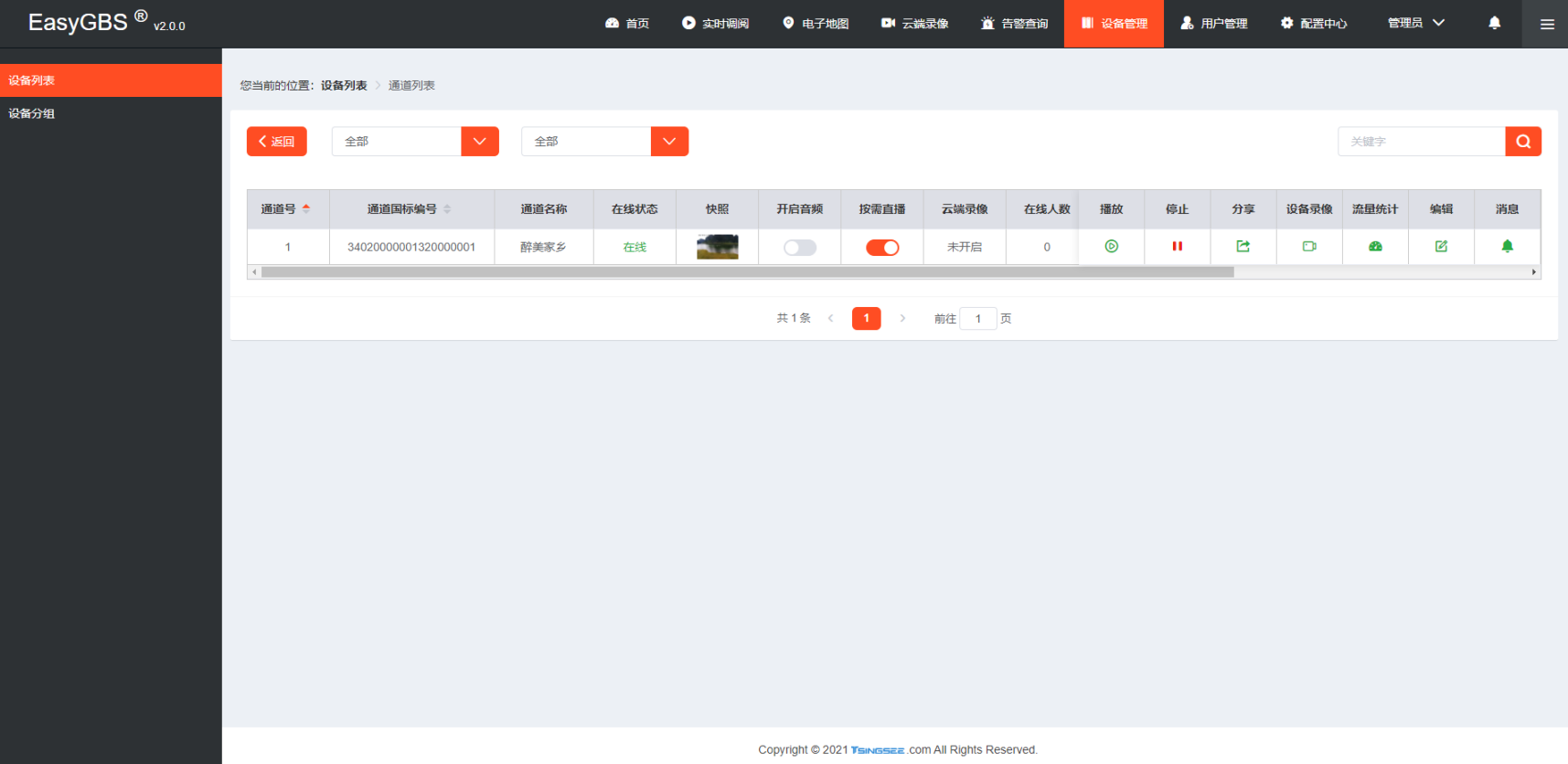
新版EasyGBS更新快照后刷新出现快照数据库内容丢失问题调整
我们的视频流媒体服务器诸如支持国标协议的EasyGBS、支持RTSP协议的EasyNVR流媒体平台,这些平台在做研发的时候,我们都做了快照界面,让用户观看的界面更加直观。
由于最近EasyGBS更新了新版内核,我们在对新版EasyGBS做通道测试时…
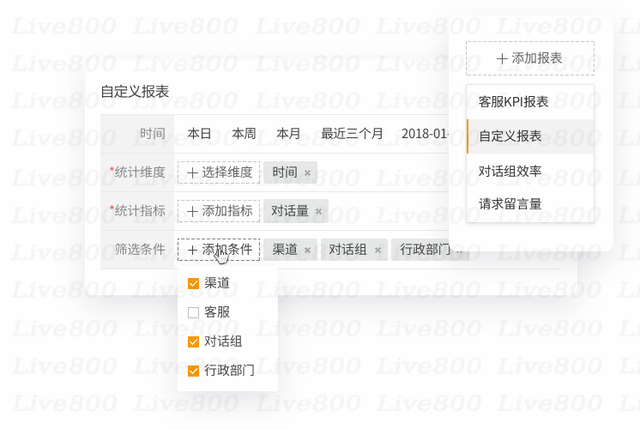
Live800:在线服务,如何解决从流量到销量难题?
随着中国互联网行业发展进入下半场,企业采买流量的成本较此前出现了明显的增长,流量越来越贵已是众多企业的共识。同时,互联网飞跃性的发展正一步步地改造消费者的购买习惯,网络无限的开放性和交互性,让消费者面临更多…
文艺产业在人工智能赋能之下,催生出了新的样貌
科技的飞速发展,影响着社会经济与文化事业的演进模式。文艺产业在人工智能赋能之下,催生出了新的样貌、新的业态、新的场域,“人工智能文化产业”的新格局已成雏形。网络文学、网络音乐、网络动漫、网络戏剧、网络影视、网络游戏、短视频、弹…

Mac IntelliJ IDEA连接和操作MySQL数据库
想要IntelliJ IDEA后台开发,数据库的连接时必不可少的,这里我们选择开源的,同时也是使用人数比较多的一种数据库MySQL。
第一步:MySQL的下载安装
到MySQL官网下载,找到MySQL Community Edition (GPL),这个…
企业使用网页智能在线客服的好处
人工智能的发展史已有十几年,在发展早期一直到七八十年代,都未能达到于商业的结合。其中主要原因就是,当时的发展水平较低,功能不完善,人们的认知也是比较低,接入企业面临着比较困难的问题,再者…
区块链技术助力医学技术领域下一战略布局
本项研究成果有效解决了数据样本量小和数据浪费等问题,但仍对标注数量及质量有很高要求。为了建立可跨专科自动分割识别医学图像的结构化技术,有必要纳入更多疾病学科医学数据,从而实现医学人工智能“乐高”计划在其他疾病学科的推广应用。然…
除了工业机器视觉外,“3D机器视觉”也受到了越来越多的关注
结合智慧城市、智能安防、人脸识别等场景的发展情况,机器视觉的应用广度与深度不断推进,本土机器视觉企业新贵在这一领域的竞争力持续提升,作为3D机器视觉引导行业的领跑企业,通过自主研发的机器人3D视觉引导系统、深度学习分类与…

人工智能技术发展呈现高科技化和数字化发展 成为重要推动力
人工智能作为引领科技革命的重要驱动力,已经越来越成为国家战略规划和行业瞩目的热点,并且基于现代的科技发展,众多智能科技新兴产物应运而生,数字虚拟学生清华华智冰就是一个很好的例子,它的出色表现也成功的引起了众…
人工智能助力科学家倾听鲸鱼的声音、社会生活和行为
记录:从各种传感器收集鲸鱼通信和行为数据的大型纵向的多模态的数据信息; 过程:协调和处理多传感器的数据; 解码:借助 ML 技术,构建鲸鱼的交流模型并描述其结构,将其与行为紧密联系起来…

计算机毕业设计之Spark+Flink餐饮大数据 外卖大数据 订餐推荐系统 外卖推荐系统 美食推荐系统 外卖数据分析 大数据毕业设计(大屏+支付+推荐算法)
开发技术
Spark
Flink
SpringBoot
Vue.js
支付宝沙箱支付
运行截图
大数据分析(暂存草稿)
Spark是一种快速、通用、可扩展的大数据分析引擎:
spark的分析模式:
Spark Local模式
Spark Standalone模式
Spark Mesos模式
Spark on YARN模式
执行HDFS中的sync()方法,可以保证数据中心断电后数据不会丢失。
Hadoop核心架构中&…

时间序列化数据库选型?时序数据库的选择?
根据 2022 年最新 DB-engines排名,主流时序数据库依然是 InfluxDB、Prometheus 等。但从排行上升趋势不难看出,近一年新的时序数据库崭露头角,这也说明企业技术选型的方向也越来越多。 如何做好时序数据库的选择,也是困扰众多企业…
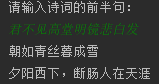
java中的switch
1.switch语法格式 switch (表达式) {case 1:语句体1;break;case 2:语句体2;break;...default:语句体n1;break;}
执行流程:
1.首先计算出表达式的值 2.和case依次比较,一旦有对应的值,就会执行相应的语句,在执行的过程中…
人工智能正成为推动教育高质量发展步入“快车道”的有效支撑手段
2019年《中国教育现代化2035》指出,以人才培养为核心,通过提升校园智能化水平、探索新型教学形式、创新教育服务业态、推进教育治理方式变革,智能驱动教育创新发展;2021年教育部等六部门发布《关于推进教育新型基础设施建设构建高…

Delta Lake底层技术详解
一、前言
Spark是大数据分析领域基础软件之一,拥有相当大比例的用户群。Spark的作者之一 Michael Armbrust同时也是Delta Lake的作者。Michael Armbrust从实际工作经验中发现了Parquet(Spark的默认数据格式)的缺点,开发出了Delta…

银行数字化转型导师坚鹏:金融大数据分析与应用能力提升实战
金融大数据分析与应用能力提升实战课程背景:
数字化背景下,很多机构存在以下问题:
不清楚大数据思维如何建立?
不清楚金融大数据分析方法?
不了解大数据应用成功案例?
课程特色:
有实战案例…
利用人工智能技术普及教学应用、拓展教师研训应用、增强教育系统监测能力
2019年《中国教育现代化2035》指出,以人才培养为核心,通过提升校园智能化水平、探索新型教学形式、创新教育服务业态、推进教育治理方式变革,智能驱动教育创新发展;2021年教育部等六部门发布《关于推进教育新型基础设施建设构建高…


MPO跳线中公头与母头的区别
我们平常用的比较多的光模块普遍为LC接口或者MPO接口,不同接口的光模块要用相对应接口的跳线去连接,LC接口在所有速率的光模块中都有其身影,而MPO接口通常存在于高速率的光模块。 MPO跳线的类型很多,可以通过纤芯数量、公…

发射光功率和接收灵敏度对光模块的实际使用有什么影响?
在光模块的DDM(数字诊断信息)中,可以看出五个参数信息,分别是工作温度、工作电压、偏置电流、发射光功率和接收灵敏度。工作温度、工作电压和偏置电流相对来说趋于稳定,客户在选购时特别看重的就是发射光功率和接收灵敏度。这两个…

【直播预告】用Greenplum技术生态构建智慧城市
随着大数据时代的数据积累,越来越多的智慧分析需求应运而生。人工智能、大数据、云计算技术已广泛应用于智慧城市场景。Greenplum技术生态将数据与智能结合,提供了一套既能实现大数据又能实现算法引擎的底座工具。 5月26日,Greenplum将举办今…
虹科云课堂|3月1日,数据管理与可视化解决方案免费直播课程开讲
迎春三月,虹科云课堂免费直播课程开讲啦! 本期虹科云课堂为您带来虹科数据管理与可视化解决方案。本期虹科云课堂共5期直播课程,全程免费! 从3月1日起,虹科与您相约直播间,精彩干货课程不容错过!…
数字经济浪潮汹涌而来,互联网的终极奥义愈发清晰
当数字经济的浪潮汹涌而来,互联网的终极奥义,正在变得清晰。承载着庞大的流量,孕育着海量的新技术,数字经济正在成为互联网的代名词。无论是腾讯的产业互联网,还是阿里的数字经济体,我们都可以看到…
人工智能的落地对行业针对性以及实际运用成本提出更高要求
同时,萨摩耶云在科技创新及技术应用方面获得多项核心专利,从而奠定了其“AI决策”的核心优势。例如萨摩耶云《互联网造数方法及系统》率先通过算法和模型实现互联网自动造数功能,企业可基于对数据库ER分析模型进行拓展,并根据不同…
AI大模型相当于“超级大脑”,正成为人工智能“新高地”
AI大模型有望实现人工智能从感知到认知的跃迁,重新定义人工智能产业模式和产业标准,给部分产业带来重大变革。我国有较大的AI大模型应用市场,但发展过程中面临部分技术薄弱、人才稀缺、成本高昂等多重挑战,亟须对相关技术研发和产…
人工智能的发展能够对我们人类的生活造成巨大改变
我们大家都知道,现在来到了21世纪信息科技的时代,加上第四次工业革命的推进,每个国家都在卯足了劲,发展本国的科技实力。我们大家能很明显的感受到,随着科技的进步,它能够让我们平时的生活都发生巨大改变。…
Sqoop--Hadoop和关系型数据库中的数据相互转移的工具
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 Sqoop官方版本&a…
Sqoop安装过程详解
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 Sqoop官方版本&a…
AI已被视作赋能实体经济的重要驱动技术,其应用场景需求也逐渐从单点走向规模化
场景需求不断涌现、创新应用层出不穷,AI正迎来蓬勃发展期。然而,当传统行业纷纷应用AI推进数字化转型、智能化升级时,AI行业自身却还处于手工作坊式的阶段。以上游AI企业专项定制进行算法开发的传统模式,已难以满足规模化的应用需求。越来越多的企业都希望具备自主的AI模型开发…
HBase Shell命令行操作实验
1 HBase的访问方式和HBase Shell
1.1 HBase Shell命令行终端
1.进入HBase Shell终端环境
HBase Shell是由Apache HBase官方提供的Shell命令行操作接口,是一个基于Ruby脚本语言的终端环境。利用HBase Shell用户可以方便地执行终端命令来操作HBase,进行…
提前超额完成战略目标:京东物流2021年营收超千亿,外部客户收入占比56.5%
3月10日,京东物流股份有限公司(股票简称“京东物流”,2618.HK)发布上市后首份年度业绩报告。2021年京东物流总收入达1047亿元,同比增长42.7%,其中来自外部客户收入达591亿元,同比增长72.7%&…
通过改进技术而降低伦理风险,是人工智能伦理治理的重要维度
为更好地支撑人工智能发展和治理,应从 4 个方面进行完善: 1. 普及人工智能等前沿技术知识,提高公众认知,使公众理性对待人工智能; 2. 在科技工作者中加强人工智能伦理教育和职业伦理培训; 3. 为…
人工智能冬去春来 从技术导向向应用导向转变的自然结果
今年人工智能赛道冬去春来的景象,则是行业洗去浮躁,从技术导向向应用导向转变的自然结果。 王海峰谈到的“融合创新”和“降低门槛”,明显体现出应用导向的理念,技术越来越需要与产业专有知识融合创新,越来越需要跨…
电子表格的武侠江湖里,有VBA加持的Excel,也只能算一把菜刀
Excel,都用过吧?
没用过肯定也听说过。
这可是Windows里颇具传奇色彩的软件,堪称一把九天陨铁淬炼而成的菜刀。 普通人,用它做表格,
进行简单的数据汇总。 职场人,继续用它做表格,
开始求和…

35年前,金山WPS上的当终于找补回来,没想到,钉钉也深度参与
我们当年上了微软的当!
近日,雷军在武汉科技大学毕业典礼致辞,登上了热搜。 关于“小米汽车”的话题再次被推上了舆论的风口。这是54岁雷军的最后一搏,距离2024年量产,时间也所剩不多了。
从软件到电商,到…

GP数据库-Creenplum
GP数据库与Oracle数据库区别为:侧重不同、数据库类型不同、查询不同。
一、侧重不同
1、GP数据库:GP数据库重计算的,对大数据集进行统计分析的OLAP类型。
2、Oracle数据库:Oracle数据库面向前台应用,重吞吐和高并发…
人工智能高潮下,工业自动化存在哪些新的增长点和落地空间
我国自动化在工业系统中的应用,仍存在高能耗问题,需要人工智能促进其从“有没有”向“好不好”的转变。 吴澄认为:在人工智能的推动下,工业自动化正与人工智能紧密结合,逐步走向智能制造的方向,智能制造…
【淘宝打单发货接口、进销存软件】拼多多引流小技巧介绍,店铺引流方法
不管是拼多多新店还是老店,一定要避免一个误区,那就是店铺流量与店铺销量、信誉有关,其实并不完全对,低销量、低信誉的店铺,也有机会出现在首页,那么拼多多店铺获取流量的方法有哪些呢?一、确定…

京东零售CEO徐雷升京东集团总裁,刘强东将重点关注长期战略设计
港股研究社获悉,9月6日消息,京东集团对外发布公告宣布,京东零售CEO徐雷升任京东集团总裁,将负责各业务板块的日常运营和协同发展,向京东集团董事局主席兼CEO刘强东汇报;京东健康CEO辛利军出任京东零售CEO&a…
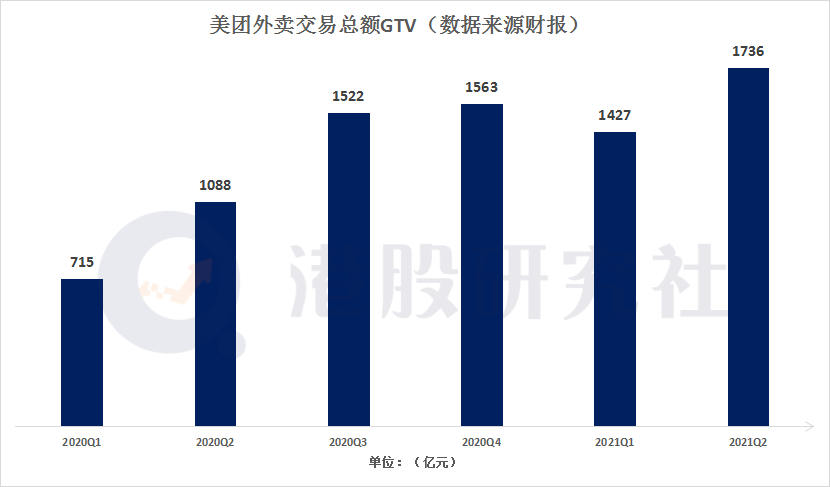
透过Q2财报看美团的变与不变
“只要我们有勇气去追求,所有梦想都能变为现实 ”。
这是迪士尼创始人华特•伊利亚斯•迪士尼给自己的鞭策。
如今在逐梦路上一路狂奔的美团,套用这句话显得颇为合适。
8月30日,国内本地生活巨头美团对外发布了2021年Q2季度及中期业绩报…
充分发挥人工智能益处的同时,需要在全球范围内进行更好的引导与合作
世界需要怎样的人工智能?12月4日至5日在北京举行的2021人工智能合作与治理国际论坛上,全球人工智能领域的思想领袖和实践者线上线下“云”集一堂,共商人工智能发展大计。论坛开幕式上,国际组织、政府部门和学术界代表就对人工智能…
快速突破流量瓶颈的方法,需从如下五点数据分析
流量瓶颈,这也是众多卖家最为苦恼的事情,更关键的是很多商家遭遇到瓶颈时,不知道是哪里出了问题?需要做哪些分析? 下面就来讲解下 一、基础数据: 首先产品质量必须好,这是基础,即便价…
人工智能指示未来方向 科学普及需要全民化
InfoQ:在科研的角度来看,目前电影里哪些场景实际已经实现了,而哪些场景可能会在未来现实生活中实现? 王元卓:以《阿凡达》为例说一下,在电影中,我想大家还记得那棵灵魂树,它可以…
目前人工智能处在什么阶段以及有哪些应用场景
第二个科幻电影是《阿凡达》。我们通过它来讲解脑机接口、异体控制、群体智能等科学知识; 第三个科幻电影是《头号玩家》。如果对科技关注很多朋友们会发现现在元宇宙在网上非常多的热评,什么是元宇宙? 其实《头号玩家》中通过技术游戏化的手…
科学幻想其实是对科学研究的发展方向起到很好的引领作用
InfoQ:首先请王老师分享下您为什么会尤为关注科幻电影? 王元卓:我相信很多的网友朋友们都非常喜欢看电影,尤其是一些画面宏大、故事情节吸引人、大开脑洞的场景,往往是这样的一些科幻电影特别能够吸引我们的关注&#…
2021年金属非金属矿山(地下矿山)安全管理人员考试题及金属非金属矿山(地下矿山)安全管理人员复审模拟考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:金属非金属矿山(地下矿山)安全管理人员考试题是安全生产模拟考试一点通总题库中生成的一套金属非金属矿山(地下矿山)安全管理人员复…
四个参数秒懂巴菲特价值投资
目录
1 巴菲特价值投资三规则... 1
2 四项参数指标对应三条规则... 1
3 价值投资选股软件... 2
1 巴菲特价值投资三规则 要说炒股,那必须得说说炒股界的扛把子巴菲特,他的选股理论是价值投资。价值投资属于长期投资策略。价值投资理论是用一个便宜的…
了解数据从哪里来以及如何使用数据做出良好的预测和决策至关重要
而通过多年人工智能的教育与实践,金珊杉发现,基于项目的学习十分有助于学生对知识的理解。因此,《一杯柠檬水的启蒙》这本书也配套制定了一份设立柠檬水摊项目的教学大纲,可以在通过实际操作,激发孩子们的创造力、合作…
助力打造全球人工智能科学发展和创新应用高地
他是一位德国顶尖人工智能专家,自2014年起受邀来到同济大学工作。6年多来,他以深厚的学术造诣和对中国的热爱,推动中德两国人工智能领域的高端合作,助力中国打造全球人工智能科学发展和创新应用高地。 他就是新当选中国工程院外籍…

数据仓库系列文章整理
声明:此系列文章来自http://webdataanalysis.net/category/web-data-warehouse/ 数据仓库的价值 相信大家都了解数据仓库的4个基本特征:面向主题的、集成的、相对稳定的、记录历史的,而数据仓库的价值正是基于这4个特征体现的:
1…
基于MapReduce的WordCount
MapReduce是一种编程模型,将任务分为两个阶段:Map和Reduce,用户只需编写map()和reduce()两个函数就可以完成简单的分布式程序的设计。 MapReduce能够解决的问题有一个共同特点:任务可以被分解成多个子问题,且这些子问题…
3款强大且实用的电脑软件,颠覆你的认知,值得一试
闲话少说,直上狠货。
1、一个木函
一个木函仅一张照片的体积,却提供了与日常、图片、设备、文件、文字处理等等相关的80多种工具,相当实用,更牛的是,完全免费,无任何弹屏广告。一个木函体积小,简…

WMS仓库管理系统解决方案,实现仓库管理一体化
仓库是企业的核心环节,若没有对库存的合理控制和送货,将会造成成本的上升,服务品质的难以得到保证,进而降低企业的竞争能力。WMS仓库管理系统包括基本信息,标签,入库,上架,领料&…
干货|一文告诉你MES管理系统如何搭建数字化车间
MES管理系统强调的是生产车间信息的监控、集成和控制,以及合理配置资源,满足信息化需求,提高对突发状况的快速响应和处理能力,促进企业数字化进程向生产车间扩展。
MES体系的数字化车间什么是数字化车间?数字化车间就是…
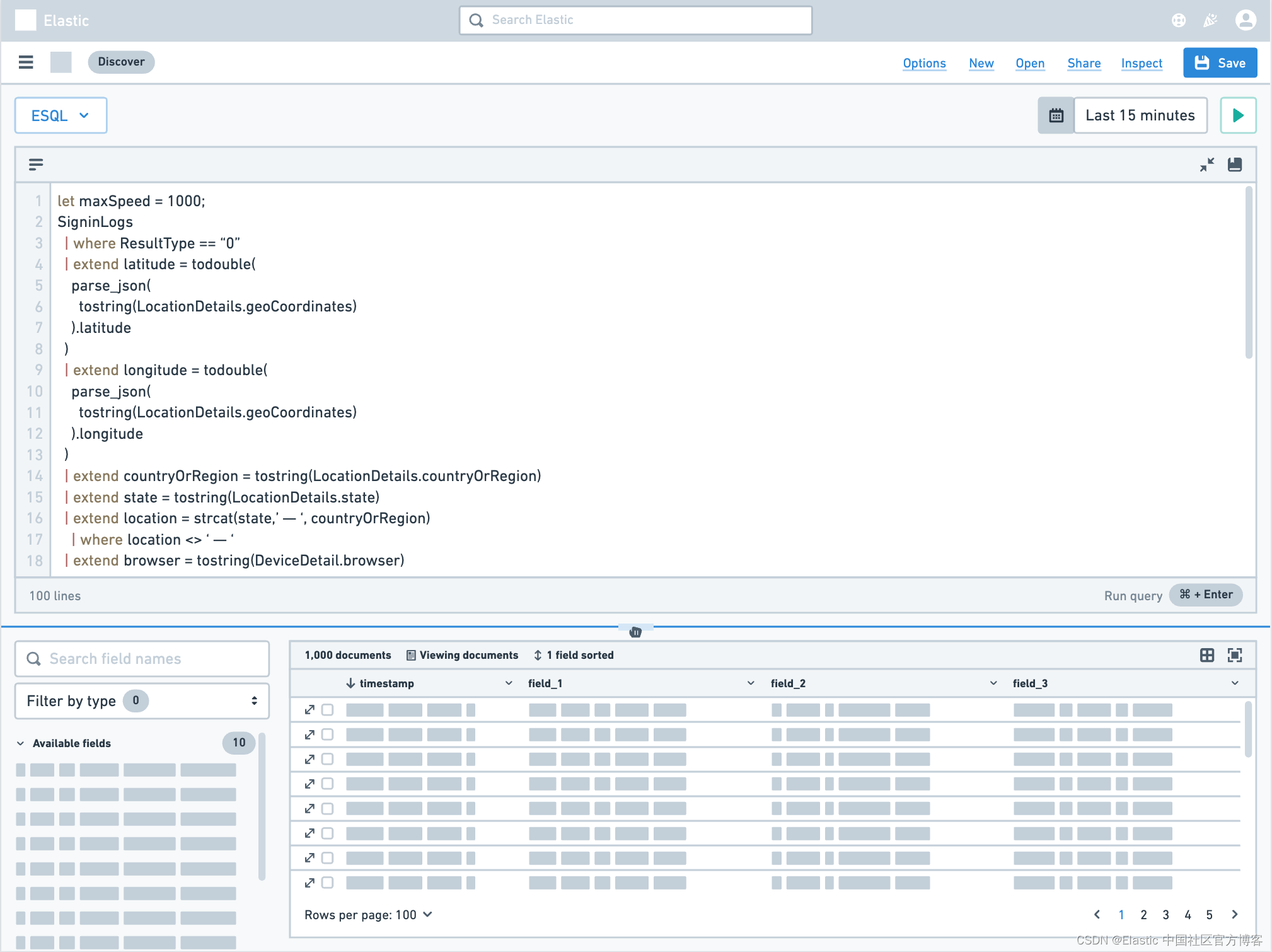
Elasticsearch:ESQL 简介 — 一种用于灵活、迭代分析的新查询语言
作者:Seth Payne 特别声明:截止撰写该博文,在目前的公开发行版中,该功能还不能公开测试。这个功能将在未来的发行版中发布。
长期以来,Elastic Platform 一直被视为搜索用例和机器生成数据的分析系统。 分析专注于处理…

华为搅局ERP,北用友南金蝶格局改变?用户:NO,我们另有选择
华为搅局ERP市场
近期,关于“华为进军ERP”的解读可谓是铺天盖地,一系列的连锁反应直接导致了用友金蝶开盘跳水。很多专业的人士认为,华为的MateERP是仅仅供内部使用,进军高端ERP完全是误读。这次的乌龙事件,华为确实凭…

倒计时组件:可视化如何自定义目标时间 / 数字倒数
倒计时组件支持通过自定义目标时间或倒数数字,在报表和大屏中展示时间倒数和数字倒数。
下面以Sugar BI为例,为大家展示
倒计时展示模式
倒计时组件提供「时间倒数」和「数字倒数」两种展示模式,效果如下: 默认为「时间倒数」模…

Elasticsearch:如何在 Elasticsearch 中存储复杂的关系数据
在传统的数据库中,对数据关系的描述无外乎三种:一对一、一对多和多对多关系。 如果有关系相关的数据,我们一般在建表的时候加上主外键。 建立数据链接,然后在查询或者统计中通过 join 恢复或者补全数据,最后得到我们需…
Flink从入门到放弃(十二)-企业实战之事件驱动型场景踩坑(一)
需求背景
某日,小明早上10点打卡到公司,先来一杯热水润润嗓子,打开音乐播放器带上心爱的降噪耳机看看新闻,静静等待11点半吃午饭。突然消息框亮了起来,这个时候小明心想要么来需求了,要么数据就有问题了。…

Delphi日薄西山?不仅用户300万,还大佬无数,转身就风靡全球
主人公名叫David Vacanti,是Delphi的长期开发人员,已有接近30年以上的编程经验。
我之所以注意到他,一是因为Delphi属实一波回忆杀。
二是不可思议:他在1983年,便开启了自己的副业。
开了一家叫做“Vacanti Yacht D…

Excel高手与普通人之间的差距,全在这个比Access还简单的工具
用“Excel”还是用“Python”?
很多职场人,在工作的大部分时间都会和“Excel”打交道,普通人,我们用“Excel”的录入和统计等,很多功能是不会用的。
只有一部分人群,会“Excel”的高级操作,比…
创建ElasticSearch索引和修改Mapping及字段类型
Elasticsearch怎么修改索引字段类型?
由于ElasticSearch没有像mysql一样可以直接字段数据类型的方法,因此需要通过创建中间索引:data_index_1,备份数据到中间索引:data_index_1,然后删除原索引: data_index,重新创建正…
计算机专业如何进大厂实习拿offer?计算机专业就业方向
导语:2022年互联网行业迎来很多大的变革,双减政策下,很多互联网教育公司砍掉了很多业务,也有一批程序员们面临着再次就业的需求,而对于计算机专业在校生而言,2022年计算机专业就业方向有哪些呢?如何在毕业…
集合类在并发情况下如何保证线程安全
在正常单线程的情况下不会出现问题,当多线程的时候,List会出现 java.util.ConcurrentModificationException 这种异常
一、List
public class ContainerNotSafeDemo {public static void main(String[] args) {/**//第一种写法List<String> lis…

为什么说 MongoDB 和 HBase 不适用于汽车行业的时序数据处理?
近年来,在能源和环保的压力下,新能源汽车成为了未来汽车发展的新方向。为支持其快速发展,我国出台了一系列扶持政策,在《新能源汽车产业发展规划(2021-2035年)》中就有提出,到 2025 年新能源汽车…
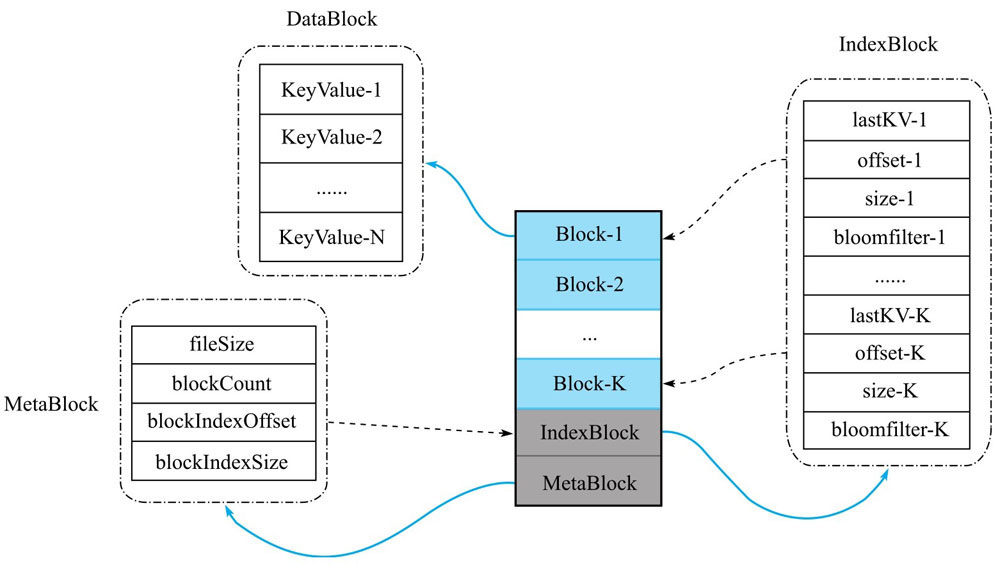
《HBase原理与实践》笔记
《HBase原理与实践》
HBase
概念
HBase是一个稀疏的、分布式的、多维排序的Map。
特征
多维:这个特征是相对于普通Map而言,HBase的Map中的Key是多维(四元组)的,(<rowkey, column family: qualifier, type, tim…
Hbase——简单操作
创建表 create 表名,列族1,列族2 统计数据条数 hbase org.apache.hadoop.hbase.mapreduce.RowCounter 表名 清空表 truncate 表名 删除表,需要两步 disable 表名 drop 表名 查询某一行 get 表名,行

波兰电商平台Allegro店铺批量采集上传
波兰电商平台Allegro是东欧最大拍卖网站,于1999年成立,随后于2000年3月在线拍卖网站QXL Ricardo plc购买,后来适应当地群众的需求转变成为在线市场。Allegro也为卖家和零售商创造了大量业务的机会。
软件支持采集批量采集波兰allegro店铺产品…
NADDOD纳多德完成数千万元Pre-A轮融资
日前,NADDOD纳多德完成数千万元Pre-A轮融资,本轮融资由数字元景领投,原股东北京博云领创科技中心、北京数迅永合科技中心联合跟投。本轮融资后,纳多德将保持极致聚焦,在光网络产品技术创新和光连接整体解决方案上持续投…

2020.08.18【转载】丨叶绿体基因组二代测序组装经验分享
叶绿体基因组二代测序组装(个人经验分享) 前段时间,有老师咨询我关于叶绿体基因组组装的问题,虽然本人不才,但也很热心地帮了个忙。虽说中间出了一些小意外,唉唉算了还是不提了。在这里顺便就个人常用的叶绿…

Hadoop之计算框架Tez的基本使用
Hadoop之计算框架Tez的基本使用Tez概述Tez编译下载Tez源码修改pom.xml开始编译Tez与Hadoop上传Tez到HDFS创建配置文件tez-site.xml配置环境变量Tez和Hadoop的兼容作业测试Tez与Hive整合拷贝Jar修改hive-site.xml配置文件重启HiveTez参数设置Tez优化内存大小设置JVM参数设置Hive…
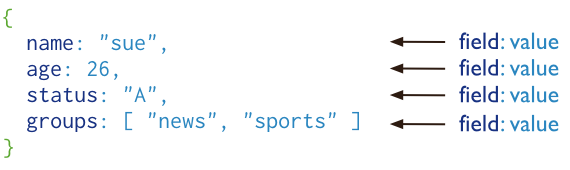
MongoDB数据库快速上手
MongoDB数据库
一、NoSQL 简介
NoSQL(NoSQL Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd’s提出的…

计算机三级数据库技术
1、数据库基本概念
1、数据
数据(Data)是数据库中存储的基本对象。 定义:描述事物的符号序列 数据的种类:数字、文字、图形、图像声音及其他特殊符号。
计算机中数据分为两部分: 临时性数据 持久性数据 数据…

《人工智能与大数据技术导论》适合用来深度了解AI和BD技术
#好书推荐##好书速递##好书奇遇季#《人工智能与大数据技术导论》京东当当天猫都有发售。
本书已被几十所高等院校、研究生院选为教材,适合好学的开发人员用来深度了解AI和BD技术。 2017年是人工智能(Artificial Intelligence,AI)…

《Python大数据处理库PySpark实战》用Python操作Spark
#好书推荐##好书奇遇季#《Python大数据处理库PySpark实战》京东当当天猫都有发售。
Apache Spark为Python开发人员提供的编程API接口,以便开发人员用Python语言对大数据进行分布式处理,可降低大数据处理的门槛。Python语言是大数据、人工智能的通用编程…
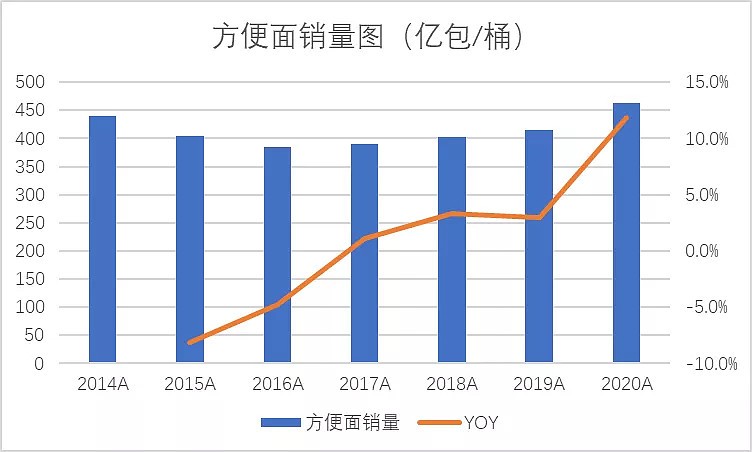
度过不完美的2021年,港股食品股如何修复市场信心?
民以食为天,因此,食品股在消费行业股票中一直占据着特殊的地位。然而,并非所有食品股都能像A股炒作预制菜概念股一样,在二级市场迎来春天。刚刚过去的2021年,港股食品股经受了一波不大不小的产业链压力,也因…
中国最大直营中式快餐集团赴港上市,乡村基对资本的“胃口”了?
就餐文化及快节奏生活方式渐趋普及,快餐市场逐渐掀起波澜,越来越多的快餐品牌处在候车上市的路上。
据IPO早知道消息,乡村基快餐连锁控股有限公司(以下简称“乡村基”)于1月25日正式向港交所递交招股说明书࿰…

隐藏在宝尊电商Q3财报里的“价值锚点”
随着科技的快速发展,技术创新正全面引爆商业变革。数字化转型已成为当下企业的迫切需求,与此同时,企业对于品牌推广和销售形式也提出了更高的要求。
特别是,当线上线下消费逐渐融合的趋势加强,线上品牌推广、多形式销…

透过小鹏三季度财报看新势力造车的“交付量之争”
11月初,多家媒体公布了10月新势力车企交付量排名。
其中,最引人注目的莫过于“蔚小理”三者的名次变动。小鹏、蔚来、理想三者中,小鹏再度位列国内新势力车企排名第一,理想位居第二,蔚来则排在第三。
11月23日晚间&a…
ES单机版安装步骤详解
本篇博客的主要目的是介绍ES单机版的安装方式。elasticsearch-5.4.3.tar.gz 百度云地址链接:https://pan.baidu.com/s/1z9yA2Ai34ZqiteMMifgx-A 提取码:y2zn
官网地址:https://www.elastic.co/cn/downloads/?elektrahome&stormhero
a.…
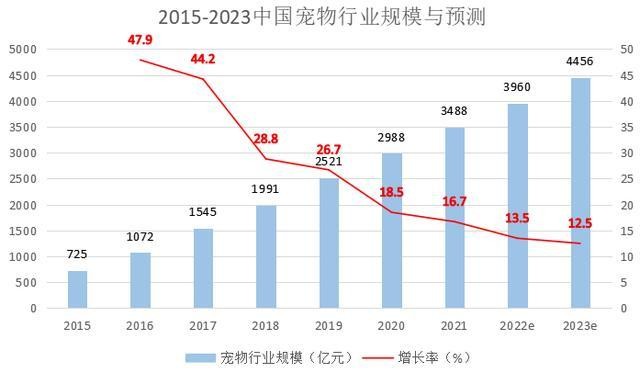
千亿级宠物赛道,卖蚊香的朝云能“掘金”多少?
单身化和老龄化的社会趋势加剧了大众在宠物身上的情感寄托,推动了“它经济”的快速发展。近年来,与宠物相关的产品和企业发展得如火如荼。
不少互联网大厂也纷纷涌入,今年6月,百度App上线“私人宠物医生”服务;腾讯入…
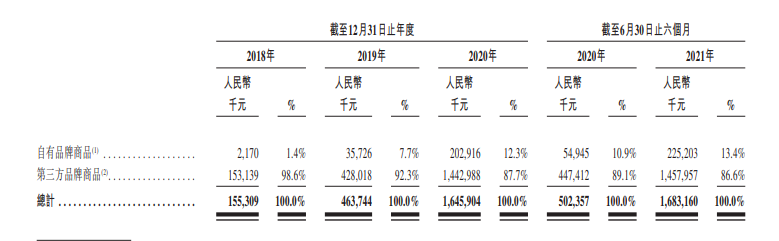
叩响港交所大门,KK集团能否成为“中国版秋叶原”?
近年来,随着消费群体逐渐发生转变,新零售市场迎来了新的消费趋势,90后、00后等成为了新的消费主力。
有数据显示:我国Z世代的开支达4万亿元,Z世代的开销占全国家庭总开支的13%,已经成为炙手可热的下一代“…
扒开圆心科技招股书,除了“卖药”还剩下多少“科技”?
近两年,随着疫情的爆发,大众健康意识逐渐增强,与之相对的是,医疗行业正在成为融资、上市的热门领域。不管是眼科、口腔还是互联网医疗领域,在资本的加持下,纷纷摩拳擦掌,也催生了不少上市欲望。…


从“化学家”到开发者,从甲骨文到TDengine,我人生的两次重要抉择
作者 | 尔悦 采访嘉宾 | 张玮绚(Wade) 小T导读:在去年 11 月,曾在甲骨文北京研发中心核心开发团队任职的张玮绚(Wade)转身成为了涛思数据的一员,负责 TDengine 的研发管理工作。在即将进入 45 岁…
TDengine 离线升级流程
注意事项:
强烈建议有升级需求的用户直接升级至各个版本分支的最新版本( 所有下载链接 - TDengine | 涛思数据 );TDengine 在升级后不可以做版本回退。因此,请务必根据正文的升级流程,提前做好备份&#x…
5 年前他的一个设计思路,让 TDengine 时间压缩提升近 50 倍
作者 | 尔悦
采访嘉宾 | 廖浩均
小 T 导读:作为创始团队成员之一,廖浩均在 2017 年就正式加入了涛思数据,彼时整个团队才不过寥寥五个人,TDengine 也才诞生不久。作为一位毕业于中科院计算所的计算机应用技术专业博士࿰…
TDengine 2.6 正式发布,新增大量计算函数
小 T 导读:作为一款典型的时序数据库(Time-Series Database)产品,TDengine 被广泛运用于物联网、工业互联网、车联网、IT 运维、能源、金融等领域。TDengine 本身提供了大量的计算函数,在很多场景下,用户都…
yarn集群下启动spark错误WARN:66 - Neither spark.yarn.jars nor spark.yarn.archive is set
yarn集群下启动spark错误如下:
WARN Client:66 - Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
解决办法 在hdfs上创建目录:
hdfs dfs -mkdir -p /home/hadoop/spark_jars
上…

TDengine 在 TCL 空调能源管理平台的实践
作者:许海军 小 T 导读:格创东智科技有限公司成立于 2018 年,孵化于中国 500 强企业 TCL,是我国知名的工业互联网平台服务商。公司依托 TCL 集团 40 年工业场景和制造基因沉淀,基于“面向工业现场”的研发方向和“连接…
从四种时序数据库选型中脱颖而出,TDengine在工控领域边缘侧的应用
作者:冰茹 小 T 导读:和利时始创于 1993 年,业务集中在工业自动化、交通自动化和医疗大健康三大领域,结合自动化与信息化两方面的技术优势,提出了“智能控制、智慧管理、自主可控、安全可信”的战略指导方针。围绕集团…

服务器数量从 21 台降至 3 台,TDengine 在跨越速运集团的落地实践
作者: 叶秋,李海峰,周美华 —— 跨越新科技 vms 车管技术团队 小 T 导读:跨越速运集团有限公司创建于 2007 年。拥有“国家 AAAAA 级物流企业”、“国家级高新技术企业”、“中国物流行业 30 强优秀品牌”、“中国电商物流行业知名品牌”、“…
小区文化建设成居民困扰,捷径智慧物业系统提出解题方案
小区文化建设成居民困扰,捷径智慧物业系统提出解题方案
截至至今,西安地区的社区图书阅览室仍然处于较尴尬的地位。
社区图书阅览室借阅图书不方便,来看书的居民很难查找到自己想阅读的图书,图书摆放无序化,社区居民…

大数据复习(第五六章)
第五章
1.HBase HBase是 Apache基金会的一个项目。简单来说,它是一个分布式可扩展的 NoSQL数据库,提供了对结构化、半结构化、甚至非结构化大数据的实时读写和随机访问能力。(P123) HBase数据存储逻辑模型与 Google BigTable类似,但实现上有一些不同之处…

MySQL通过frm和idb恢复数据库的方法
基于本地MySQL操作
原因:比较方便
这个方法比较繁琐 有一步到位的大佬可以留言指教
一、安装PHPstudy、Navicat(MySQL连接工具)
二、本地数据库创建数据库
三、执行恢复(重点)
1、创建要恢复的表 2、执行解除…
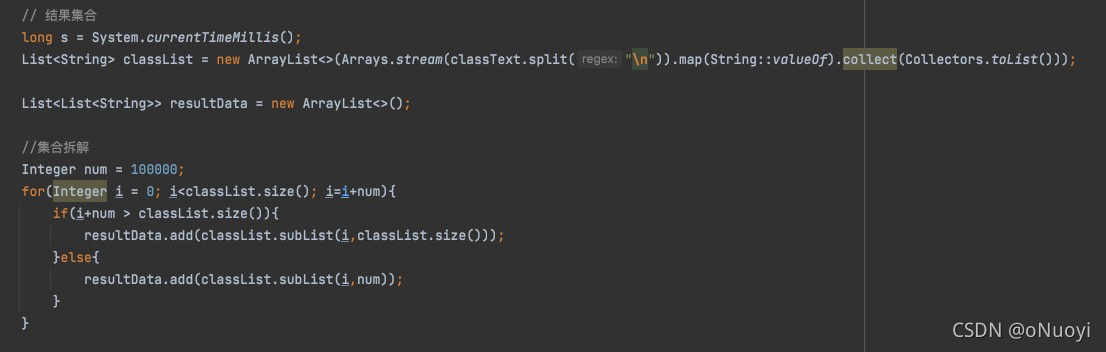
List集合按指定长度拆解多个集合sublist()处理大数据集
关于集合按指定长度拆解成多个集合的起因是因为一个阿里云的代码挑战赛的一道题目而有感的, 题目有一道提示是 在没有处理大数据集的情况下,这道题提交时提示的是超时异常, 然后各种百度处理大数据集后无所获,发现集合的一个subli…
蓝格赛(中国)用 TDengine 落地聚合查询场景,效果如何?
作者:曲春辉,负责工业数字化平台架构 小 T 导读:作为全球性的电气产品和服务经销商,蓝格赛于 2000 年进驻中国市场,一直致力于帮助中国更有效地使用能源。经过 20 年的不断壮大,如今蓝格赛在中国国内电气产…
10倍性能优势!TDengine在云洋物联智慧农业业务中替代MongoDB
作者介绍
叶红伟,北京云洋物联技术有限公司软件研发经理,主要从事智慧农业平台开发及应用,负责平台的架构设计以及主要业务代码开发工作。
关于云洋物联
作为国内领先的数字农业产品与解决方案服务商,云洋物联自成立以来便始终…
Hadoop_MapReduce_WordCount案例错误:Shuffle$ShuffleError: error in shuffle in localfetcher#1
参考map100% reduce0%&error in shuffle in localfetcher#1_闲人编程的博客-CSDN博客
错误原因是电脑用户名有个空格,采用更改电脑用户名的方法有效解决 ,或者在代码里设置(没尝试)

为什么免费OA不能深入应用于企业?
免费OA(如钉钉)很大的存在价值在于:可以让用户熟悉OA软件,帮助企业积累信息化的经验,降低企业信息化过程中的风险和成本。在企业中实施协同办公OA不仅需要购买软件,而且更需要所有员工共同使用,…

关于大数据的两个大分支
Cloudera
引自 New Features in CDH 6.0.0 See below for new features in CDH 6.0.0, grouped by component:
Apache AccumuloApache AvroApache CrunchApache FlumeApache HadoopApache HBaseApache Hive / Hive on Spark / HCatalogHueApache ImpalaApache KafkaApache Ku…

《推荐系统实践》 第七章 推荐系统实例 读书笔记
从上面的结构可以看到,推荐系统要发挥强大的作用,除了推荐系统本身,主要还依赖于两个条件界 面展示和用户行为数据。关于如何设计推荐系统的界面,笔者没有太多的发言权。不过,如果我们看看目前流行的推荐系统界面&…

hadoop构建数据仓库实践 数据仓库简介和数据仓库设计基础章节 读书笔记
1.数据仓库简介
1.0演变 1.1什么是数据仓库
本质:数据仓库试图提供一种从操作型系统到决策支持环境的数据流架构模型。
要解决的问题:多重数据复制带来的高成本问题(在没有数据仓库的时代,需要大量的冗余数据来支撑多个决策支持…

基于ElasticSearch+文本相似度模型的检索式智能对话方案
目录
背景
为什么只用ES相似度匹配不行
解决同一意图不同表达的问题 “粗筛”“精选”的意图匹配方案
另外一种思路: 背景
在对话系统领域,检索式对话系统一直是工业界的偏爱。而如何“检索”,或者说如何对用户query(输入的问题)进行意图…

Elasticsearch修改mapping
参考链接: elasticsearch 修改mapping映射字段_a275870703的博客-CSDN博客 思路:elasticsearch 不支持修改mapping映射,无法直接修改,需要曲线救国来实现——新增一个索引,再把原索引的数据搬过去。分为仅修改字段类型…
【ES实战】磁盘存储优化
文章目录磁盘存储优化准备知识元数据字段_all索引字段的映射参数indexnormdoc_valuesstore优化措施磁盘存储优化
准备知识
元数据字段
_all
_all 字段是一个特殊的 catch-all 字段,它将所有其他字段的值连接成一个大字符串,使用空格作为分隔符&#…
【ES实战】索引翻滚 Rollover Index使用说明
文章目录Rollover Index使用前提功能说明翻滚场景翻滚条件自定义翻滚试运行模式举例说明Rollover Index
翻滚索引指的就是 对满足特定条件的拥有别名的索引,进行采用旧索引的配置创建新索引,并对将新索引别名下的is_write_index设为true。
使用前提
索…
【ES实战】Split Index使用说明
文章目录Split Index使用说明使用前提主要功能实现举例说明分裂过程监控问题总结Split Index使用说明
将源索引按照特定的规则分裂成一个比源索引拥有更多主分片的新索引。
使用前提
配置index.number_of_routing_shards。这个参数的值,应该要比主分片的个数多&a…
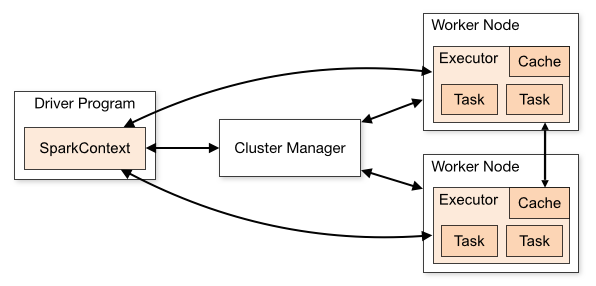
Spark 集群部署模式概述
文章目录Cluster Mode OverviewComponentsCluster Manager TypesSubmitting ApplicationsMonitoringJob SchedulingGlossaryCluster Mode Overview http://spark.apache.org/docs/latest/cluster-overview.html 本文档简要概述了 Spark 如何在集群上运行,以便更容易…

数据库显示 too many connection
show variables like %max_connections%;
set GLOBAL max_connections1000;
canal同步MySQL数据到Elasticsearch
canal同步数据详解前言canal下载工作原理开启mysql数据同步功能安装配置详情配置 canal-deployer配置 canal-adapter测试数据库准备创建es索引增删改admin前言
上篇文章讲了es同步数据的方案和使用logstash同步的讲解(es数据同步方案),本文详…

银行数字化转型导师坚鹏:银行数字化运营所必须采取的五大措施
银行数字化运营已经成为提升市场竞争力和客户满意度的重要战略。以下是银行数字化运营所必须采取的五大措施:
1) 建立强大的数字化基础设施:银行需要投资建立可靠的数字化基础设施,以支持数字化运营的各个方面。这包括更新和升级银行的IT系统…

flume对接kafka测试
Flume对接Kafka测试
配置文件
# example.conf: A single-node Flume configuration# Name the components on this agent
a1.sources r1
a1.sinks k1
a1.channels c1# Describe/configure the source
a1.sources.r1.type netcat
a1.sources.r1.bind localhost
a1.source…
数据库的备份恢复和SQL语句
1. 数据库的备份与恢复
1.1 数据库常用备份方案
数据库备份方案:
全量备份增量备份差异备份
备份方案特点全量备份全量备份就是指对某一个时间点上的所有数据或应用进行的一个完全拷贝。数据恢复快。备份时间长增量备份增量备份是指在一次全备份或上一次增量备份…


头歌Educoder云计算与大数据——实验三 分布式文件系统HDFS
实验三 分布式文件系统HDFS第1关:HDFS的基本操作任务描述相关知识HDFS的设计分布式文件系统NameNode与DataNodeHDFS的常用命令编程要求测试说明代码实现第2关:HDFS-JAVA接口之读取文件任务描述相关知识FileSystem对象FSDataInputStream对象编程要求测试说…
一册在手,走遍天下(大数据技术架构手册之上篇十四万字问世)
开头
该公众号从19年开始注册,荒废了一年,大概从20年年底开始正式运营,早期定位是个人总结复盘,没有萌生以此作为副业的念头,开始的文章大多偏向于技术底层。 21年看着身边的朋友搞公众号有了不错的收入后࿰…
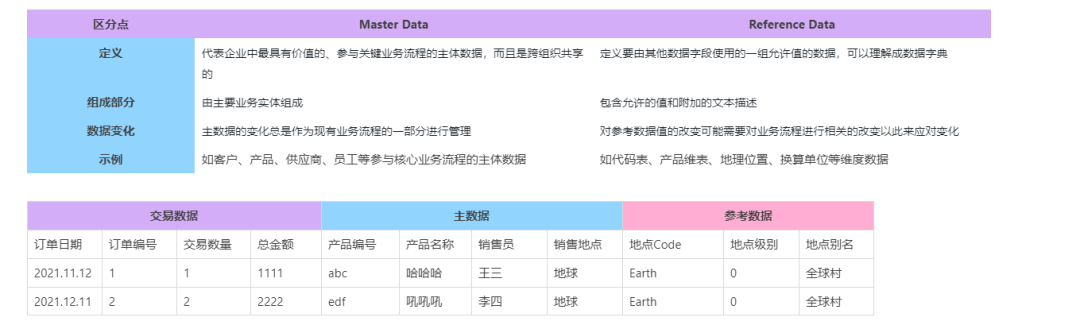
一文理解主数据和参考数据
如果你准备要开展推动数据治理或者是数据质量的项目,那么你就有可能会听说到几个词:主数据和参考数据。一开始听到主数据这一词听起来就很高大上,而且非专业人士肯定不理解(即便是从事数据行业的朋友也很难参透)。这一…
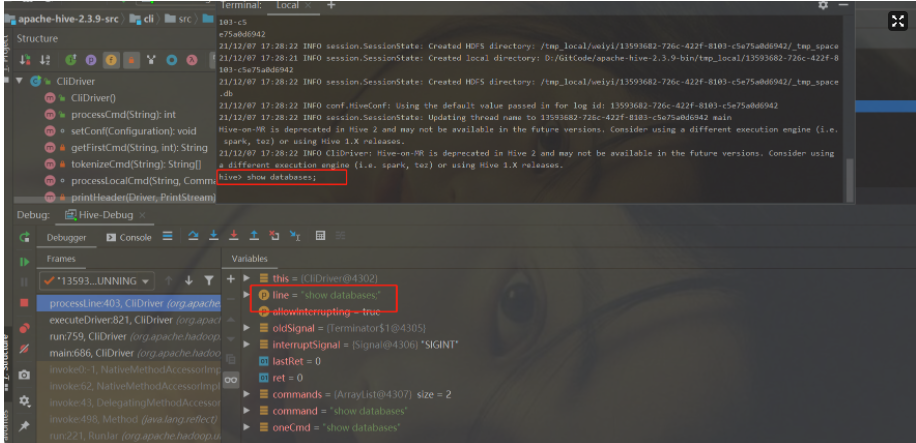
十分钟带你走进Hive世界(每走一步都是为了离你更近些)
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
该文基于Hive专题-从SQL聊Hive底层执行原理进一步的深入学习Hive,相信大多数童鞋对于Hive底层的执行流程只是局限于理论层面。那么本篇将带大家花半个小时左右的时间在自己…

【从零开始学爬虫】通过新浪财经采集上市公司高管信息
l 采集网站
【场景描述】采集新浪财经所有行业板块中上市公司的高管信息。
【源网站介绍】
新浪财经,提供7X24小时财经资讯及全球金融市场报价,覆盖股票、债券、基金、期货、信托、理财、管理等多种面向个人和企业的服务。
【使用工具】前嗅ForeSpider数据采集系…
面试官把我问懵了....
感谢兄弟们的关注与支持,如果觉得有帮助的话,还请来个点赞、收藏、转发三操作
该文章已更新到语雀中,后台回复“语雀”可获取公众号:进击吧大数据整个职业生涯持续更新的所有资料
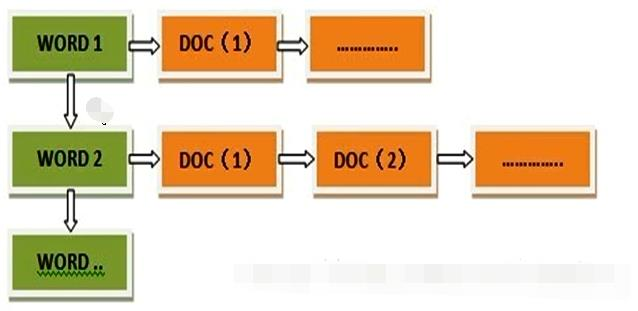
在前面介绍了Hadoop三部曲搞起~,简单…

面试官问:UDF是在Map端执行还是Reduce端执行?
感谢兄弟们的关注与支持,如果觉得有帮助的话,还请来个点赞、收藏、转发三操作
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
感谢
首先感谢linxiang同学提供的文章素材,linxiang在…

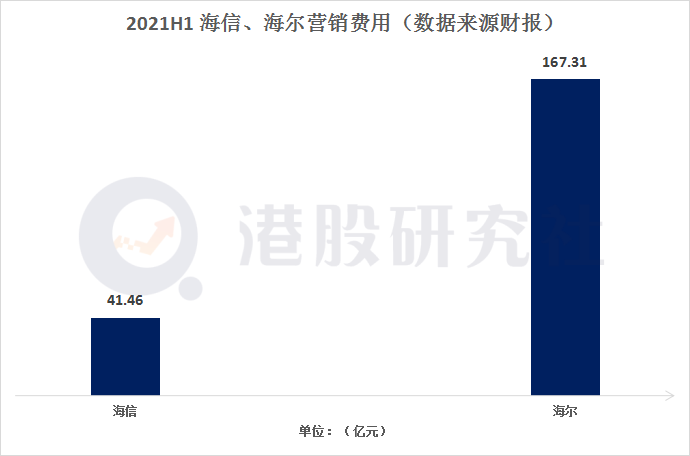
透过海信、海尔年中财报:看家电行业“下半场”之变
近日,国内家电行业头部玩家,海尔、海信在同一天公布了今年上半年中期业绩报告。
单从财报数据的基本面来看,2021年上半年,两家企业营收、净利均实现了新增长,符合市场及分析师的预期。
资本市场也给出了反应…
消息队列【四】分布式消息中间件Kafka
从面试角度一文学完 KafkaKafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信。对分布式消息系统的https://mp.weixin.qq.com/s/h2NT67i-xy4Hr3MqGjGk5QKafka性能篇:为何Kafka这么"快"?『码哥』的 Redis…
【学习笔记】ElasticSearch(ES)基本概念和语句学习笔记
一、ES概念
1. ES
ElasticSearch又称ES,是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。Elasticsearch是面向文档型数据库&am…
谈谈谈zookeeper
数据结构和存储 ZK采用树形结构,这棵树由节点组成,每个节点称为ZNode。ZNode引用方式是路径引用,比如/app1/p1,这样的层级结构让每个ZNode都有唯一的路径。每个ZNode兼具文件和目录的特点,既像文件一样维护着数据、元信…

ElasticSearch基础之 权威指南笔记(二)
数据输入和输出
创建新文档
当我们索引一个文档,怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
请记住, _index 、 _type 和 _id 的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是…
Hive_开窗函数实验注意点
1.数据 numid123356
2.用开窗函数累加第一行至当前行
select sum(id) over(order by id) from num
3.结果
1 3 9 9 14 20
两个9的原因:id为3的有两个,到第一个id为3的时候和第二个id为3的时候都是开窗到第二个id为3的地方。

union union all
相同点:两者作用都是结合两表
区别:union去重,union all不去重
(1)如果需求需要去重,只能选择union
(2)如果需求不需要去重,选择union all
(3)…

Nebula图数据库安装
1. Nebula单机性能测试
1.1 节点相关参数
节点名称:java@10-135-45-1
节点cpu逻辑核数:32
节点cpu物理核数:16
节点内存情况: 节点存储: 1.2 批量导入csv数据
配置yaml文件(部分yaml文件):

直播内容精华:Greenplum在运营商领域的HTAP实践
4月29日,和示说社区合作,我们举办了今年的第二场线上活动。在活动中,社区专家苑泽福(阿福)为大家详细介绍了Greenplum在运营商领域的HTAP实践,活动获得了大家的一致好评。现在让我们通过这篇文章来回顾一下…

Hadoop数据压缩
目录
1.压缩的好处和坏处及原则
2.MR支持的压缩编码
3.压缩位置选择
4.压缩参数配置
5.压缩实操案例
(1)Map输出端采用压缩
(2)Reduce输出端采用压缩 1.压缩的好处和坏处及原则
压缩的优点:以减少磁盘IO、减少…
MySQL 中 You can‘t specify target table ‘表名‘ for update in FROM clause错误解决办法
MySQL 中 You can’t specify target table ‘表名’ for update in FROM clause错误解决办法
//将SELECT出的结果再通过中间表SELECT一遍,解决问题
UPDATE banner_manager
SET STATUS 1
WHEREid IN (SELECTa.id FROM( SELECT id FROM banner_manager bm WHERE …
hutool- 数组工具
//数组工具-ArrayUtilTestpublic void arrayUtil(){//判空int[] a {1,2};if (ArrayUtil.isNotEmpty(a)) {System.out.println("very good");}//数组克隆Integer[] b {1,2,3,4,5,6};Integer[] cloneB ArrayUtil.clone(b);Assert.assertArrayEquals(b, cloneB);//有…

Hadoop_MapReduce_Combiner合并
目录
1.自定义Combiner实现步骤
2.Combiner合并案例实操
1)需求
2)需求分析
3)案例实操-方案一
4)案例实操-方案二 1.自定义Combiner实现步骤
(a)自定义一个Combiner继承Reducer,重写Re…
hutool- 数字计算
//数字计算Testpublic void test14(){//会将double转为BigDecimal后计算double te1123456.123456;double te2123456.128456;//加减乘除 add sub div mulConsole.log(NumberUtil.add(11));//选择保留小数位数 ,可以选择四舍五入或者全部舍弃等模式Console.log(NumberUtil.rou…
spark/work爆满如何清理
spark-env.sh中添加自动清理配置
export SPARK_WORKER_OPTS"-Dspark.worker.cleanup.enabledtrue -Dspark.worker.cleanup.interval60 -Dspark.worker.cleanup.appDataTtl120"

Hadoop_MapReduce_Partition分区
shuffle是通过分区partitioner 分配给Reduce,一个partition对应一个Reduce,Partitioner是shuffle的一部分。 1.默认Partition分区 默认分区是根据key的hashCode对ReduceTasks个数取模得到的,用户没法控制哪个key存储到哪个分区。
2.自定义Pa…

Hadoop序列化案例实操
目录 1.需求
2.需求分析
3.自定义对象和三个类的程序
(1)编写流量统计的Bean对象
(2)编写Mapper类
(3)编写Reducer类
(4)编写Driver驱动类
3.结果 1.需求
统计每一个手机号耗…
数据库原理 第四章 笔记
文章目录四、SQL1. SQL简介1.1 SQL特点1.2 SQL 3大类11个命令词1.3 SQL支持数据库的三级模式结构1.4 SQL语言的基本概念2. SQL数据定义2.1 SQL数据定义功能2.2 SQL数据定义语句2.3 定义、删除与修改基本表3. SQL——SELECT3.1 查询语句格式3.2 数据查询3.2.1.单表查询3.2.2 连接…

Hadoop_MapReduce_WordCount案例
目录
1、需求
(1)输入数据
(2)期望输出数据
2、实现(本地测试)
(1)环境准备 1)创建maven工程,MapReduceDemo(maven官网下载maven,…
Hive2.3.9部署
Hive2.3.9部署
解压安装改名
tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /opt
cd /opt/
mv apache-hive-2.3.9-bin/ hive
cd hive
cd conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh添加以下内容
export HADOOP_HOME/opt/hadoop
export HIVE_CONF_DIR/opt/hiv…
Hadoop HA部署
Hadoop2.7.2 HA部署 文章目录Hadoop2.7.2 HA部署解压改名配置环境变量配置 hadoop-env.sh配置yarn-env.sh配置mapred-env.sh配置slaves配置 core-site.xml配置 hdfs-site.xml配置yarn-site.xml初始化解压
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/改名
cd /optmv hadoop-2.7.2…
Iceberg构建数据湖
Iceberg核心思想 在时间轴上根据快照跟踪表数据的修改
特性: 优化数据入库流程可以merge 与上层引擎解耦,不绑定spark 统一数据存储,灵活文件组织 增量读取能力 实现细节: 快照设计: 每次读写更新生成快照,写会生成新…

P4 数据库系统概论——常用的数据模型
文章目录常用的数据模型层次模型表示方法层次模型的定义层次模型的数据结构常用的数据模型 层次模型
用树形结构来表示各类实体及其实体间的联系
表示方法
实体型:用记录类型描述每个结点表示一个记录类型属性:用字段描述每个记录类型可包含若干个字段…

头歌Educoder云计算与大数据——实验一 Linux操作系统
实验一 Linux操作系统第1关:Linux初体验任务描述相关知识Linux目录结构介绍Linux用户介绍Linux 常用命令介绍pwd命令cd命令ls命令编程要求评测说明代码实现第2关:Linux常用命令任务描述相关知识Linux文件操作创建文件删除文件Linux文件夹操作创建文件夹删…

bi平台怎么选,一文详解
bi平台怎么选?选bi平台不是一个照搬照抄的事情,企业在选bi的时候要考虑的不止是bi平台本身,企业的所属行业、具体业务、发展和管理水平、信息化水平、人员技术背景等都会影响到最后选择,没有最对的bi平台,只有最合适的…

突破数据展示限制,自由切换分析维度,百数分析报表真的够炫
可视化数据分析已经成为当前各个行业的日常需求,用于辅助企业的重大商业决策。对使用者来说,操作体验和智能分析功能、可视化分析效果一样重要。因此,选择一款便捷的数据可视化工具,能够起到事半功倍的效果。 采用低代码操作的数据…

为什么它可以和可视化工具tableau相提并论?
数据可视化是数据分析的最后一里路,它借助于图形化手段,清晰有效地传达与沟通信息。能够有效地传达思想概念,美学形式与功能需要齐头并进,通过直观地传达关键的方面与特征,从而实现对于相当稀疏而又复杂的数据集的深入…
ES index生命周期配置
一、前言
PUT _ilm/policy/AAAAAA_policy
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"rollover": {"max_size": "100mb"},"set_priority": {"…
ms sqlserver 数据库附加与分离脚本
1.数据库分离:
use master
--分离数据库
if exists(select 1 from sys.databases where nameNtestDB)
begin
ALTER DATABASE testDB SET OFFLINE
EXEC sp_detach_db NtestDB
end2.数据库附加:
use master
--分离数据库
if exists(selec…
spark优化之编程方式汇总
spark优化有两个方向,一是写好的代码,二是合理配置资源。本文讲述的是第一种思路,内容来源于Spark Performance Tuning & Best Practices,sparkbyexample是个很好的网站,除了是全英文,没有缺点。
以下…
Sqoop安装及案例导入导出数据(基于Hadoop环境)
Sqoop安装及案例导入导出数据(基于Hadoop环境)
Sqoop主要用于在Hadoop(Hive)与传统的数据库MySQL间进行数据的传递可以将一个关系型数据库(如:MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也…
Datax与Sqoop的对比
Sqoop主要特点
1、可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
2、sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduc…
Mysql学习日记:L28-数据库设计三范式
目录
一、数据库设计三范式
二、第一范式
三、第二范式
四、第三范式
五、总结表的设计 什么是数据库设计范式
设计库表的设计依据,教你怎么进行数据库表的设计。
一、数据库设计三范式
数据库设计范式有3个
第一范式:要求任何一张表必须有主键…

phpMyAdmin将CSV文件导入数据库+PHP数组转JS数组
文章目录一、背景二、步骤1.CSV文件导入数据库2.SQL语言查询数据三、PHP数组转JS数组1.json_encode()2.decodeURIComponent()3.应用总结一、背景
开发中,经常将csv文件中的数据导入数据库,这样就可以在使用…
对“科学无禁区,技术应慎重”的认知与理解
对“科学无禁区,技术应慎重”的认知与理解曾由人民网报道,深圳南方科技大学的科学家贺建奎宣布,一对名为露露和娜娜的基因编辑婴儿于2018年11月在中国健康诞生。这对双胞胎的CCR5基因经过修改,使她们出生后即能天然抵抗艾滋病&…
Kibana:Kibana 入门 (一)
在我之前的文章 “如何开始使用 Kibana”,我对 Kibana 做了一个简单的介绍。从那篇文章中,我们可以对 Kibana 有一个初步的了解。在今天的文章中,我来通过一个实操来展示如何使用 Kibana。希望针对那些还没有使用过 Kibana 的开发者来说有所启迪。
这是一个共有三篇文章的系…
实在智能签约乳胶寝具龙头企业JACE:实在RPA机器人邀你筑梦
近日,实在智能签约乳胶寝具头部品牌JACE,双方将携手拥抱数字化新时代。实在RPA作为电商数字化转型标配,将通过深度结合AI技术的电商数字员工,为JACE提供一站式的电商自动化与智能化解决方案,全方位助力JACE实现精细化运…
电商RPA:直播行业必不可少的工具
一场突如其来的疫情让大部分企业措手不及,经济增速放缓,各种风险和不确定性因素增多,但仍有行业在其中发现新的机遇,电商行业便是其中之一。 目前,线上消费增速同比趋缓,而直播电商依旧保持高速增长。数据显…
2021 大数据应用开发Java 1+x中级实操题答案汇总--含3篇
2021 大数据应用开发Java 1x中级实操题答案汇总–含3篇
2021实操题答案 20211030 1X 中级实操考试样题20211127 1X 中级实操考试样题20210620 1X 中级实操考试样题 结语
2021实操题答案
食用须知: 答案是我自己试过运行了的,不能说是最正确的答案&a…
Spark: py4j.protocol.Py4JJavaError: An error occurred while calling o91.showString.
创建于:2022.06.15 修改于:2022.06.15
利用Spark的yarn模式(把.py文件上传到hadoop平台),执行过程中发现了下面的问题。py4j.protocol.Py4JJavaError: An error occurred while calling o91.showString.
代码段如下&…

为什么说饿了么全能超市藏着阿里零售的未来
出品 | 何玺 排版 | 叶媛
近日,饿了么在上海、北京、杭州、广州等地上线了“全能超市”业务, 这是继去年7月阿里巴巴调整组织架构以来,饿了么在本地生活服务领域的又一次进击。
01
进击本地生活,饿了么新业务全能超市上线
早在…
Day_04 传智健康项目-预约管理-套餐管理
第4章 预约管理-套餐管理
1. 图片存储方案
1.1 介绍
在实际开发中,我们会有很多处理不同功能的服务器。例如:
应用服务器:负责部署我们的应用
数据库服务器:运行我们的数据库
文件服务器:负责存储用户上传文件的…

抖音集团要做“一站式信息服务商”不容易
字节跳动有大动作!
据多家媒体日前报道,字节跳动(香港)有限公司已更名为抖音集团(香港)有限公司。此外,字节跳动旗下其他数个公司也陆续更名为“抖音”。
01
字节跳动成立抖音集团大概率是在…

实在智能RPA快来领奖啦
11月16日,“WRE营销创新与科技峰会2021”在上海举行。来自零售消费品行业的营销与数字化负责人、以“全洞察、全渠道、全触点、全链路”为主题展开讨论。实在智能联合创始人、CMO张俊九作为出席嘉宾进行主题分享。 会上,张俊九作主题为《“数智赋能&…

海尔智家三翼鸟的“场景定制”为什么能俘获用户?
出品 | 何玺 排版 | 叶媛
经过一年的多的狂奔发展后,海尔智家旗下场景品牌三翼鸟再次提速。
01
三翼鸟与居然之家、红星美凯龙达成进一步深化合作协议
2021年5月,海尔大家居经营体正式成立不久,团队就拜访了居然之家表露合作意向。经过高…

快手在按自己的理念和节奏前行
8月25日,快手发布2021年第二季度财报及半年度财报。新财报有什么看点?又藏着怎样的信息,我们一起来看看。 01
快手新财报看点一:在线营销、电商营收增长强劲
财报显示,2021年上半年,快手收入为361.58亿元…
elasticsearch的索引(增删改查)管理
1. 创建索引
# 语法
PUT /索引名/[类型名]/文档id
{请求体
}可以通过 postman 发送请求,也可以通过 kibana 发送请求,由于 kibana 有提示,所以我们选择kibana
索引名不能有大写字母
PUT Book{"error" : {"root_cause"…
大数据组件之Hive(Hive学习一篇就够了)
文章目录一、Hive安装1、解压环境2、环境变量配置3、配置文件信息1.打开编辑文件2.输入以下内容4、拷贝mysql驱动5、更新guava包和hadoop一致6、mysql授权7、初始化8、hive启动模式9、Hadoop的core-site.xml配置二、Hive1、Hive的文件结构2、MySQL上Hive的元数据3、hadoop文件授…

SparkShell操作Hudi
使用环境 cdh 6.3.2 spark 2.4.0 hudi 0.9
使用sparkShell连接hudi
/opt/cloudera/parcels/CDH/lib/spark/bin/spark-shell \
--jars ./hudi-spark-bundle_2.11-0.9.0.jar \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer 创建表
import org.a…
Qt 常用的数据库语句(使用数据库用到)
-- 创建一个名称为info的数据库。
create database info;-- 删除数据库info
-- drop database info;-- 使用数据库 info
use info;-- 创建表
-- create table student(id int primary key auto_increment, name varchar(255), age int, score int);
create table student(id in…
17:StructuredStraming-流动的wordcount开始
这个模块中,按照惯例,我们还是从一个可以迅速上手的实例开始,带你初步认识 Spark 的流处理框架 Structured Streaming。然后,我们再从框架所提供的能力、特性出发,深入介绍 Structured Streaming 工作原理、最佳实践以及开发注意事项,等等。在专栏的第一个模块,我们一直…
MySQL数据库的知识点
数据库MySQL 适用于中小型企业,MySQL数据库适合搭集群,单独拿一台MyCat出来管理许多子数据库 通俗地讲,数据库就是把一些数据整合到一起,其实质还只存在硬盘里
SQL语句(Structured Query Language;结构化查…
以数据分析为导向的运营体系搭建+LTV
目录
一.市场体系数据化
1.销量波动与趋势分析(使用线性回归预测未来业绩趋势)
2.日/周/月销量权重对比(销量波动周趋势分析指标-周权重指数)
3.市场占有率计算
二.运营体系数据化 1.关键词优化
2.转化率分析用户访问深度分…

密集的动作暴露了海尔智家发力生活家电的决心
随着居民生活水平的提高,在刚需家电的基础上,消费者对生活家电的需求不断提高。在这样的市场背景下,各大企业纷纷加码布局生活家电业务,海尔智家也不例外。
通过梳理发现,海尔智家近3个月来在生活家电领域动作频频&am…

Spark基础之:rdd的特性,DAG,Stage的理解
rdd的特性,DAG,Stage的理解RDD结构化理解RDD的数据集与PartitionsPartitionerDependencies与LineageNarrowDependency与ShuffleDependency为什么区分窄依赖和宽依赖?StageCheckpointIterator和ComputeStorageLevelPreferredLocationSparkcont…
MapReduce基础之:MapReduce过程中的排序
mapreduce为什么要排序
是为了通过外排(外部排序)降低内存的使用量:因为reduce阶段需要分组,将key相同的放在一起进行规约,使用了两种算法:hashmap和sort,如果在reduce阶段sort排序(内部排序),太消耗内存&…

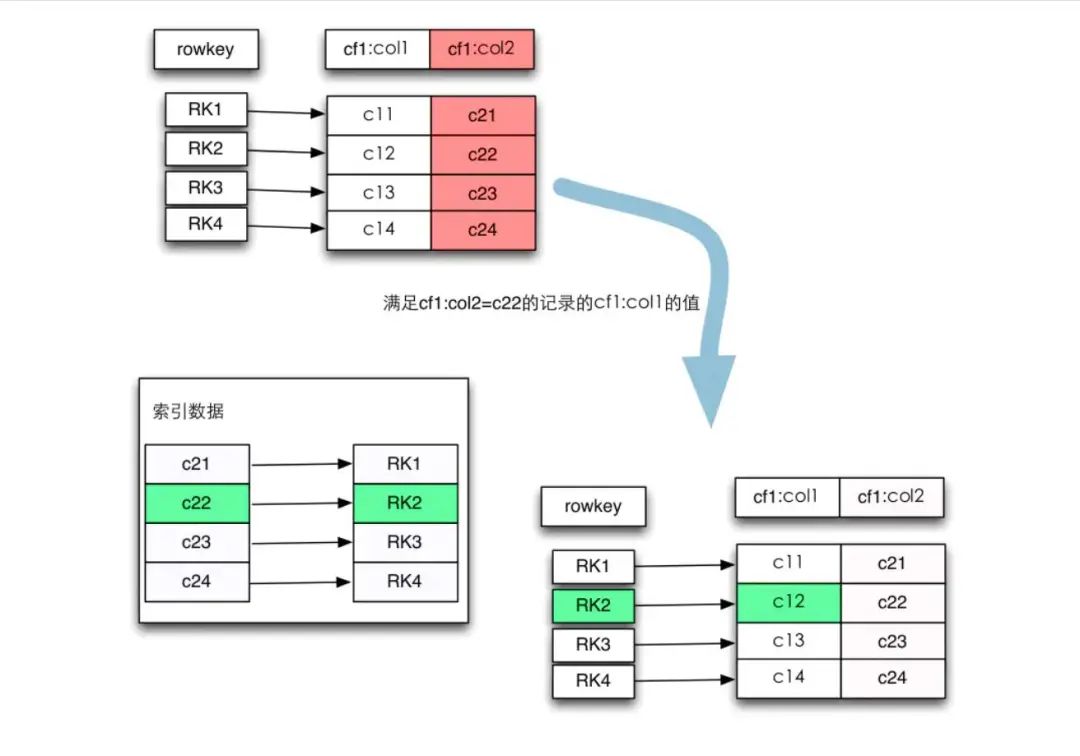
Hbase的二级索引和RowKey的设计
Hbase查询简介 Hbase查询的时候,有以下几种方式: • 通过 rowkey方式,指定 获取唯一记录 • 通过 scan方式,设置satrtRow 和stopRow 参数进行范围匹配(模糊查询) • 全表扫描,即直接扫描整张表中所有行记录 HBase里面只有rowkey作为一级索引
Hbase的scan,不走主键索引,…

为什么放弃Java后,没有使用Kotlin,新的开发语言正在席卷而来
放弃Java后,没有使用Kotlin
从 Java 到Kotlin,Kotlin作为Android官方支持语言,获得了更多的关注和采用! 这几年,Kotlin的发展势头很猛,可以说由 Java 转 Kotlin 早已势不可挡。
那么Kotlin有哪些优势可以…

实在智能RPA新机遇:亮相华南CIO大会、大湾区第一届RPA峰会
粤港澳大湾区,作为中国开放程度最高、经济活力最强的区域之一,数字化产业起步早,发展快,数字经济蓬勃发展,以数字技术为代表的前沿科技飞速发展及应用,为三地融合发展创造便利条件。
近期,多场…

实在智能电商RPA,一款广泛应用于电商行业的RPA机器人
受疫情影响,线上对线下渠道的替代逐渐加剧。随着大量实体店涌向电商赛道,越来越多的零售商开始转向线上,电商行业竞争可以说是越来越激烈。2021年传统电商可以将就着过,但随着新兴电商不断崛起,传统电商被层层压制&…

对象存储、文件存储、块存储区别介绍
简单总结: 1. 块存储 设备一般是磁盘、暴露直接访问SCSI和网络访问FC等标准协议、支撑直接的磁盘操作,适合场景一遍是对读写有非常高的性能要求,如数据库 2. 文件存储 以文件和文件夹方式、通过IP协议、实现对同类型数据的存储、分层管理和检…

电商RPA | 董明珠接班人带货引争议,达人资源有多难得?
摘要:面对日益紧俏的达人资源,传统电商在向直播电商的转型过程中,无疑要付出更多的人力物力以寻找调性匹配的达人资源,实在RPA无疑是这个过程的得力助手。
因为被董明珠公开宣称将被培养成为下一个自己,22岁的孟羽童成…
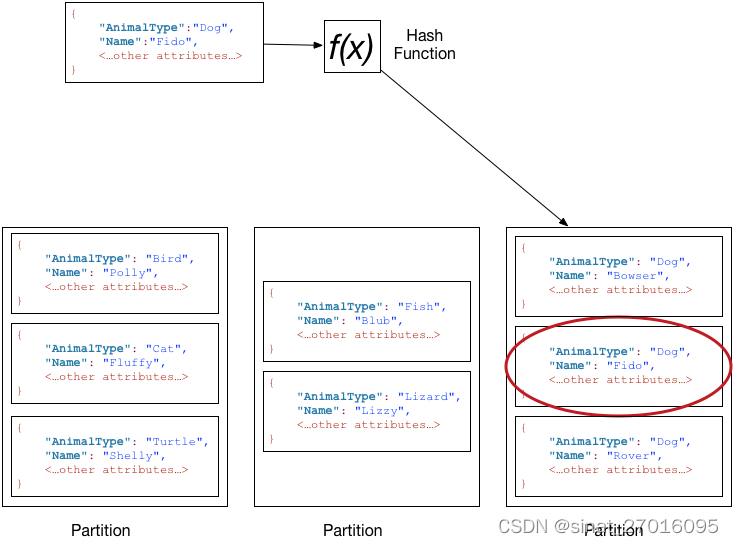
aws DynamoDB 分区和数据分布
亚马逊DynamoDB在分区中存储数据。分区是一个表的存储分配,由固态驱动器(SSD)支持,并在AWS区域内的多个可用区自动复制。分区管理完全由DynamoDB处理,你永远不需要自己管理分区。
当你创建一个表时,该表的…
大数据实验一 关联规则实验题目:蔬菜价格相关性分析
学习来源
实验目的:在掌握关联规则算法的原理的基础上,能够应用关联规则算法解决实际问题。
实验内容:根据实验数据,采用Apriori等关联规则发现算法,给出相关关联规则。
实验要求:给出数据预处理过程、关…
数据库常用sql总结
本篇博客是对一些比较常见的数据库知识的汇总,并会持续更新。
Postgres
如何获取postgres所有的表里的记录条数?
SELECT nspname AS schemaname,relname,reltuples
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid C.relnamespace)
WHERE nspna…

无代码低代码平台测评:挑选最适合您的开发工具
导语:在当今数字化时代,无代码和低代码平台成为了企业快速开发应用程序的热门选择。本篇测评文章将为您介绍几个知名的无代码和低代码平台,并对其进行评比,帮助您挑选最适合您的开发工具。
一、云表平台
云表平台,是…
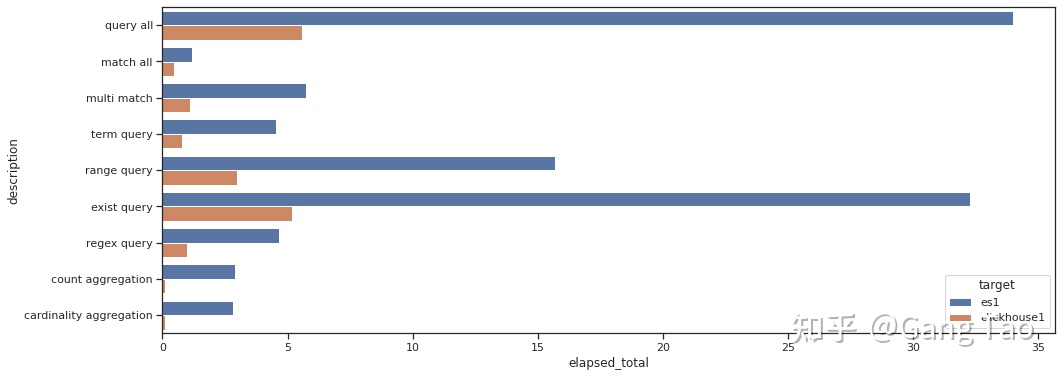
Clickhouse和es
转自:Elasticsearch和Clickhouse基本查询对比 - 知乎
Elasticsearch 是一个实时的分布式搜索分析引擎,它的底层是构建在Lucene之上的。简单来说是通过扩展Lucene的搜索能力,使其具有分布式的功能。ES通常会和其它两个开源组件logstash&#…
三十一:Flink 和 Kafka 整合时间窗口设计
在计算 PV 和 UV 等指标前,用 Flink 将原始数据进行了清洗,清洗完毕的数据被发送到另外的 Kafka Topic 中,接下来我们只需要消费指定 Topic 的数据,然后就可以进行指标计算了。
Flink 消费 Kafka 数据反序列化
上一课时定义了用户的行为信息的 Java 对象,我们现在需要消…
Spark读Hive和写Hive-实例
导入Maven
<properties><spark.version>2.1.1</spark.version><scala.version>2.11.8</scala.version>
</properties>
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-…

百数教育培训领域能力展示——培训机构
后疫情时代,对于线下培训机构而言,数字化转型已然势不可挡。招生难、师资培训难、人才管理难等问题,在很大程度上都源于缺乏数据信息的科学管理与运用。搭建教培管理系统,能够帮助机构从招生、报课、排课再到学校日常管理实现全场…

百数疫情防控行业领域能力展示——返乡登记
为了防范人员流动带来的风险,减少交叉感染,各大节假日临近时各地都会出台相应的返乡政策。借助线上的数字化平台进行返乡信息的登记既方便方向人员操作,同时也利于工作人员进行统一的信息收集管理。 百数疫情防控管理系统能够帮助企业、社区、…

百数低代码工具干货式安利——透视图篇
透视图的主要作用就是分类汇总,把表里面的原始数据进行归类,得到你想要的数据。科技引领业务发展,各行各业都需要敏捷高效地对业务情况进行探索分析,从而形成各种主题的业务报表来洞察更多业务价值。 然而,许多企业集团…

Pandas数据分析—使用stack和pivot实现数据透视
15.Pandas使用stack和pivot实现数据透视 文章目录15.Pandas使用stack和pivot实现数据透视前言一、经过统计得到多维度指标数据二、使用unstack实现数据的二维透视三、使用pivot简化透视四、stack、unstack、pivot的语法1.stack2.unstack3.pivot总结前言
不知道怎么搞的&#x…
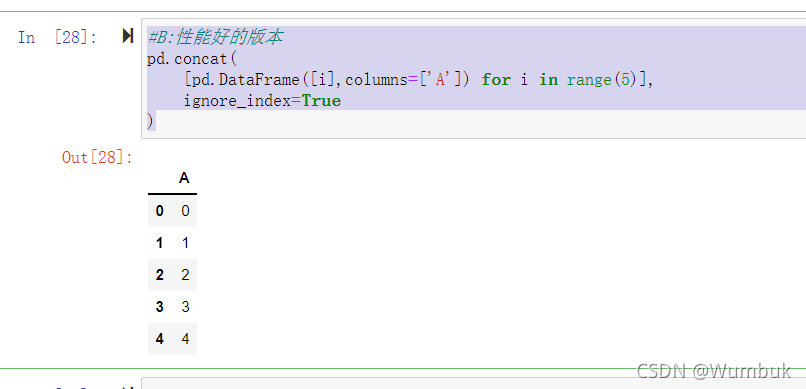
Pandas数据分析—实现数据的合并(concat和append)
11.Pandas实现数据的合并(concat和append) 文章目录11.Pandas实现数据的合并(concat和append)前言一、假造数据二、程序演示1、使用pandas.concat合并数据2、使用DataFrame.append按行合并数据总结前言
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系…
Sqoop的安装、配置与使用
本文目录如下:Sqoop的安装、配置与使用1.虚拟机环境准备2.Linux环境下安装Sqoop环境2.1 安装Sqoop3.使用Sqoop进行数据导入导出3.1 Sqoop 与 HDFS 之间的导入导出3.2 Sqoop 与 Hive 导入导出Sqoop的安装、配置与使用
1.虚拟机环境准备 (1) 虚拟机准备 虚拟机的创建…

☀️☀️大数据分析—大数据分析实例与文章汇总
本文目录如下:大数据分析文章汇总1. 大数据分析案例2. 四大经典大数据应用案例解析3. 淘宝双11大数据分析大数据分析文章汇总
1. 大数据分析案例
点击跳转至该博客页面 注: 改文章中包括大数据分析应用场景、大数据分析种类、大数据分析一般过程、大数据分析工具、…
2.Spark Streaming基础—DStream 创建—RDD 队列、自定义数据源、Kafka 数据源
本文目录如下:第3章 DStream 创建3.1 RDD 队列3.1.1 用法及说明3.1.2 案例实操3.2 自定义数据源3.2.1 用法及说明3.2.2 案例实操3.3 Kafka 数据源(面试、开发重点)3.3.1 版本选型3.3.2 Kafka 0-10 Direct 模式第3章 DStream 创建
3.1 RDD 队…

“数据”到底是资产还是负债?
伴随着大数据时代支撑数据交换共享和数据服务应用的技术发展,不断积淀的数据开始逐渐发挥它的价值,因此,业界提出可以将数据作为一项资产,“盘活”数据以充分释放其附加价值。但是事实上,如果缺乏恰当有效的管理手段&a…
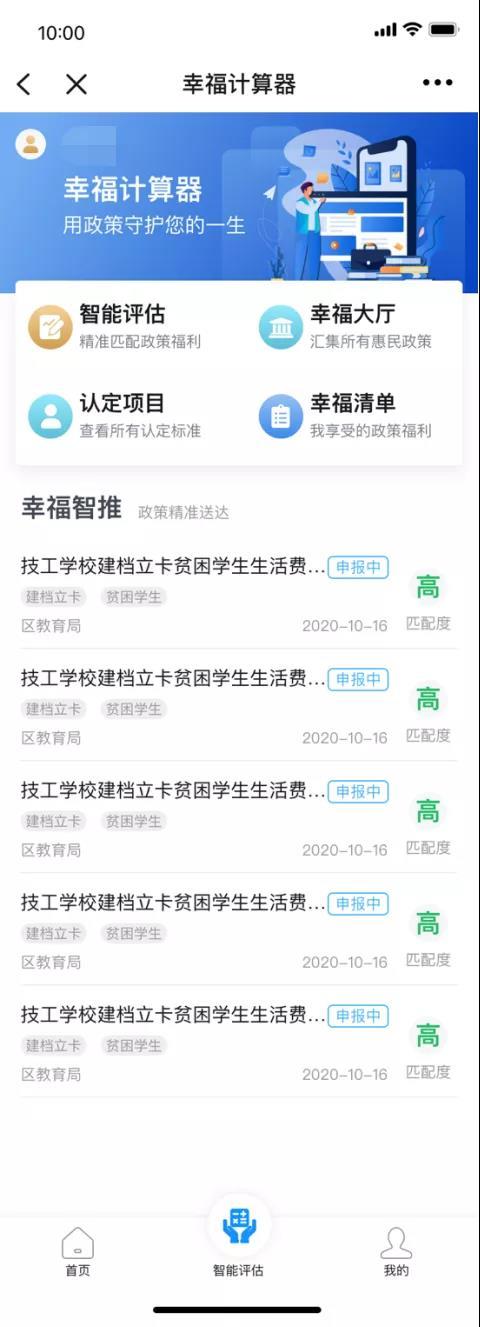
实在RPA幸福计算器,让惠民政策“找上门”
在杭州这片创新创业的热土,每年吸引许多新就业大学毕业生和创业人员。人才队伍建设离不开人才政策的保障,而政策申报也是众多来杭打拼者关注的民生热点。对此,各地政府持续推出许多便民政策造福于民。
近期,实在智能助力余杭区发…
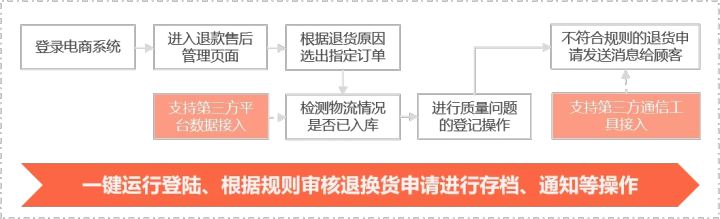
实在RPA专家课:AI+RPA如何赋能电商的数智化升级
近些年来,人口红利消失,流量红利衰退,我国电商行业渗透步入高位,增长趋势放缓。同时电商企业开始由劳动力密集型向技术密集型转变,这对电商企业的精细化运营提出了更高要求。如何真正实现数智化升级,也就成…
文章一直被拒,没有送审,也没给出拒稿原因和建议原因不过这几点
文章投稿后被拒,这是很正常的事情。
通常,期刊编辑会给出一些意见,但若遇到“文章反复投稿了多次,但是一直被拒,也不给什么审稿意见…”,小编相信,应该有不少老师的心态都崩了…… 没有收到审稿…
实在智能|电商RPA与电商人并肩作战
摘要:实在智能电商RPA与你并肩作战,生意参谋、活动报名、差评监控、自动发货、自动退款、广告检测、会场排名、千牛消息群发、抖音达人邀约……各种智能化、自动化机器人应有尽有,减轻电商人工作压力,助力店铺效率大增!…

财务RPA——企业首席财政官们的必选项
在后疫情时代,对于多数行业来说,数字化转型和保持业绩增长是必做的选项,尤其是对于金融、财税领域,这两件事更是重中之重。
美国知名IT研究与顾问咨询公司Gartner发布了报告《金融未来数字化转型,CFO必做的10件事情》…

电商RPA@直播,匹配最优达人资源
摘要:实在智能RPA数字员工可以帮助传统电商寻找符合产品调性、效益最大化的达人资源,助力传统电商乘上直播电商的东风。
直播电商,是如今的电商圈子里最常被提及的一个概念,,从2016年淘宝、京东等传统电商探索“直播电…
实在智能RPA为直播经济注入新力量,电商数智化转型在路上
互联网时代飞速发展,直播经济异军突起,闯入了大众的视野中。而受到疫情的影响,更是让直播经济驶入了“快车道”。目前,直播经济正在成为新常态下中国经济的一抹亮色。
据iiMedia Research《2020-2021中国在线直播行业年度研究报告…
为什么人资部门会选择实在智能RPA?提质降本增效
摘要:实在智能RPA能帮助人资部门在招聘环节能够实现自动化操作,简化繁杂流程,提高部门运营效率,从而节省时间、资源聚焦于战略性任务!
据一家全球化集团企业的HR团队计算出一系列重要岗位招错人的损失数额显示&#x…
实在智能RPA微观:电商应该如何告别单身
“电商”一词为人们所熟知似乎是近一二十年的事情,倘若追溯其源头可就有点久远了。早在1839年,当电报刚出现的时候,人们就开始了对运用电子手段进行商务活动的讨论。不过电商的发展很是缓慢,直到上个世纪末和本世纪初才得到快速的…

实在智能RPA告诉你,拥有一个客服机器人的好处
大家有没有这样的经历,当你在网上选购了一件商品,并且在对话框询问商家关于商品的信息,可是等了半天等不来回复,你只好就此作罢,继续在商场中寻找自己所需的商品。也可能是这种情况,当你在网上挑选了一件商…
实在智能RPA教你如何处理财务工作
随着人工智能的发展,财务工作者迎来了自己的春天。
面对繁杂的财务数据,传统财税模式往往需要靠人力来完成,存在众多痛点。所以众多企业将本土RPA服务商——实在智能RPA作为数字化转型合作首选,其研发的RPA财务机器人能够快速有效…

双十一最大的收获,就是提前准备实在RPA机器人
11月11日,双十一的战火重燃并且达到高峰;截至0点45分,382个品牌成交额破1亿元,本次双十一可以说是火力全开。
而在这次的双十一中,许多电商商家都感觉到了一些力不从心,面对海量涌入的订单,大量…

RPA进阶:IPA数字员工开启人机协作新时代
2021年,RPA赛道依旧保持强劲增势。 ▲数字员工5.8.0产品发布 就在7月的末尾,国内RPA第一梯队厂商实在智能迎来了旗下产品5.8.0大版本更新,此番更新后,其Z-Factory机器人工厂、Z-Bot数字员工及Z-Commander管理中枢近200个功能组件做…

Atlas2.1.0实战:安装、配置、导入hive元数据、编译排坑
背景 随着公司数据仓库的建设,数仓hive表愈来愈多,如何管理这些表? 经调研,Atlas成为了我们的选择对象,本文是Atlas实战记录,感谢尚硅谷的学习视频 1.Atlas概述
1.1 Apache Atlas 的主要功能
元数据管理和…
Hadoop硬件合理配置及raid方面的调研
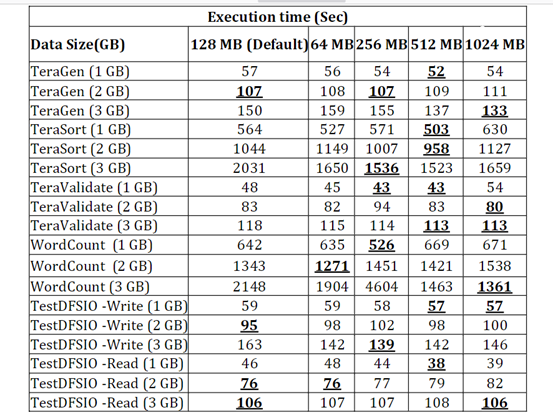
文章目录前言一、Hadoop硬件合理配置HDFSMapReduceHBase二、Hadoop架构配置建议1.管理节点NameNode2.数据节点DataNode3.JBOD vs. RAID4. SSD与Hadoop3.raid方面总结前言
最近公司在Hadoop服务器未来规划,所以调研了各个方面,有点杂乱,这里记…

Chapter5 MapReduce
5.1概述
5.1.1分布式并行编程
MapReduce是一种分布式并行编程框架。 在计算机发展史上的"摩尔定律":CPU的性能每隔18个月就可以翻一番。然而,从2005年起,摩尔定律逐渐失效,因为CPU制作工艺存在上限、性能不可能无限提…

Chapter4 分布式数据库HBase
4.1概述
4.1.1从BigTable说起
HBase是BigTable的开源实现。 BigTable是一个分布式存储系统,它最初是用于解决谷歌公司内部的大规模网页所搜问题。
网页搜索可以分为两个阶段: 1.第一阶段:建立整个网页的索引。 通过爬虫不断的抓取各个网站…

Chapter3 分布式文件系统HDFS
3.1分布式文件系统
计算机集群结构:
分布式文件系统把文件分布存储导多个计算机节点上,成千上万的计算机节点构成计算机集群。与之前使用多个处理器和专业高级硬件的并行化处理装置不同的是,目前的分布式文件系统采用的计算机集群都是由普通…

低代码平台排名及评析一览:谁是最具潜力的Top5?
在数字化时代,低代码平台已经逐渐成为企业快速开发应用的首选工具。众多低代码平台涌现市场,但谁才是最具潜力的Top 5呢?本文将为您揭示并评析这些领先的平台。 云表平台:能开发复杂管理系统的企业级低代码平台 一、平台背景 云表…
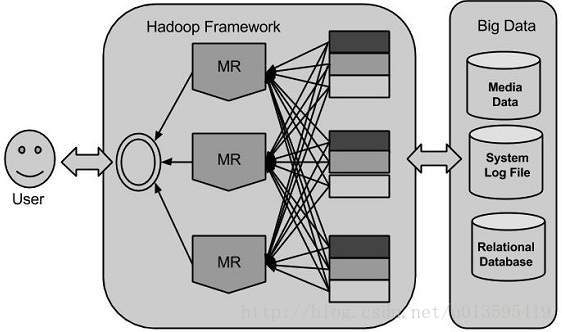
Big Data 及 Hadoop
什么是hadoop Hadoop是一款开源框架,可以在多台具有基本计算节点组成的集群构成的分布式环境上处理大数据。它既可以在单服务节点,也可以在多服务节点上运行,每个节点都会提供局部计算和存储功能。 本部分主要会介绍大数据
Big Data
什么是…
搭建spark集群以及spark HA部署
Spark集群安装(StandAlone)
下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html
这里我们使用 spark-2.0.2-bin-hadoop2.7版本. 规划安装目录
/export/servers
解压安装包
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /export/servers
重命名…
ES java 根据条件查询总数
public long countSearch(String index,String fuzzySearchStr) throws IOException {CountRequest countRequest new CountRequest(index);SearchSourceBuilder builder new SearchSourceBuilder();BoolQueryBuilder boolQueryBuilder QueryBuilders.boolQuery();//等于条件…

mysql-5.5.20-win32.msi安装教程详解
系列文章目录 文章目录系列文章目录前言一、打开任务管理器,其中三种方式如下:1.找到下方任务栏,在空白处点击鼠标右键,找到"任务管理器",点击打开,即可开启任务管理器2.使用快捷键,先按“CtrlAl…

Spark----RDD(弹性分布式数据集)
RDD 文章目录 RDDRDD是什么?为什么需要RDD?RDD的五大属性WordCount中的RDD的五大属性如何创建RDD?RDD的操作两种基本算子/操作/方法/API分区操作重分区操作聚合操作四个有key函数的区别 关联操作排序操作 RDD的缓存/持久化cache和persistchec…

智慧养老——让夕阳更美好
一、智慧养老背景
2012年,全国老龄办首先提出“智能化养老”的理念,鼓励支持开展智慧养老的实践探索。2015年,国务院印发《关于积极推进“互联网”行动的指导意见》,明确提出要“促进智慧健康养老产业发展”。2017年2月ÿ…

智慧社区——让居民生活更美好
什么是智慧社区?
社区是城市的细胞,每一个社区都是城市的一个缩影。
智慧社区通过利用多种智能技术和方式,整合社区现有的各类服务资源,为社区群众提供政务、商务、娱乐、教育、医护及生活互助等多种便捷服务的模式。从应用方向…

数据智能、数字孪生 助力智慧城市创新发展
“智慧城市”在国内经过数年发展,2021 年是“十四五”开篇布局之年,也是新基建重点发力之年。5G、物联网、工业互联网等新一代信息技术的广泛应用,正引领相关综合解决方案朝着走深向实、协同布局、社会与生态共赢的方向发展。核音智言在行业内…

智慧环卫-让城市更“干净”
随着社会发展的需要,城乡环卫逐渐一体化,垃圾围城以及城市环卫人员和作业全过程的智能化管理急需破解,目前城市中环卫作业的问题从两方面显示出来:一是现在社会现状:垃圾乱倒,垃圾焚烧,餐厨垃圾…

如何做好企业数据治理?
过去两年,国家各部委纷纷出台针对全行业的数字化转型、数据要素等方面的政策。2019年,工信部提出:“将加强数据治理,扎实推进国家大数据发展战略”,将数据治理重要性上升到新的高度。作为数字化建设的基石,…

智慧警务——大数据时代的警务模式
自2011年以来,我国公安机关在“金盾工程”一、二期建设取得巨大成效以及公安信息化水平得到广泛提高的基础上,以运用新一轮信息技术深化公安大数据应用和警务云计算辅助公安决策为核心,开始提出“智慧警务”的理念,一些省市公安机…

智慧交通,让出行更便捷
1 智慧交通概念
智慧交通是指一个基于现代电子信息技术面向交通运输的服务系统。它的突出特点是以信息的收集、处理、发布、交换、分析、利用为主线,为交通参与者提供多样性的服务;是在智能交通(简称ITS)的基础上,利用…
持久层优化-大数据保存数据库优化案例 2021-10-11
Java组件总目录 数据库优化案例Java组件总目录一、 功能与需求说明1.1 第一版:基础实现1.2 第二版:使用批处理1.2.1 批处理方式1 (JDBC中使用Batch)1.2.1在springboot中使用Mybatis的batch模式二、内存泄漏分析2.1 JVM中的安全点1…
leecode 数据库:585. 2016年的投资
数据导入:
Create Table If Not Exists Insurance (pid int, tiv_2015 float, tiv_2016 float, lat float, lon float);
Truncate table Insurance;
insert into Insurance (pid, tiv_2015, tiv_2016, lat, lon) values (1, 10, 5, 10, 10);
insert into Insurance…

如何写好英文论文中的句子?(下)
1 前情提要 大家先看完上一篇文章如何写好英文论文中的句子?(上),再接着往下翻。
10 先说名词,再用代词(it、they)指代该名词 11 否定词放在句子开头附近 12 否定词的正确位置:助动…

FLINK 学习随笔一
Flink 如何支持事件驱动的应用程序?
事件驱动应用程序的限制取决于流处理器处理时间和状态的能力。Flink 的许多出色功能都围绕这些概念展开。Flink 提供了一组丰富的状态原语,可以管理非常大的数据量(高达数 TB),并保…
数据采集平台项目(四)
1. DataX中null值的输出
mysql经过dataX的传输后,默认会将null转换为空字符串"",而hive中默认的null值存储格式为\N.
解决方案:
修改datax底层源码修改hive默认null值为空字符串
2. Hive的安装
解压安装,修改文件名…

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…

云表|低代码开发崛起:重新定义企业级应用开发
低代码开发这个概念在近年来越来越受到人们的关注,市场对于低代码的需求也日益增长。据Gartner预测,到2025年,75%的大型企业将使用至少四种低代码/无代码开发工具,用于IT应用开发和公民开发计划。 那么,为什…
云表低代码:数字化转型的新风口,你了解多少?
自2019年起,低代码开发平台骤然引发热议,成为了科技领域的新宠。关于其定义和影响力,众说纷纭。有人将它誉为第四代编程语言,有人视它为开发模式的颠覆者,更有人认为它引领了企业管理模式的变革。这股热潮在社区内引发…

企业级低代码开发,科技赋能让企业具备“驾驭软件的能力”
科技作为第一生产力,其强大的影响力在各个领域中都有所体现。数字技术,作为科技领域中的一股重要力量,正在对传统的商业模式进行深度的变革,为各行业注入新的生命力。随着数字技术的不断发展和应用,企业数字化转型的趋…

新生儿低烧:原因、科普和注意事项
引言:
新生儿低烧是一个常见的现象,许多新父母在宝宝的早期生活中会经历。虽然低烧通常不是严重的健康问题,但它可能引起父母的担忧。本文将科普新生儿低烧的原因,提供相关信息,并为父母和监护人提供注意事项…
youtube的深度学习推荐系统模型
首先:本文来自于王喆老师的《深度学习推荐系统》一书,很不错,推荐大家去看看
一:推荐系统的应用场景
作为全球最大的视频分享网站,youtube平台中几乎所有的视频都来自于ugc,这样的内容产生模式有两个特点…
Windows下Linkis1.5DSS1.1.2本地调试
1 Linkis:
参考:
单机部署 | Apache Linkis技术分享 | 在本地开发调试Linkis的源码 (qq.com)DataSphere Studio1.0本地调试开发指南 - 掘金 (juejin.cn)
1.1 后端编译
参考【后端编译 | Apache Linkis】】
修改linkis模块下pom.xml,将mysql.connetor.scope修改…
Elasticsearch:Top metrics 聚合
top_metrics 聚合从文档中选择具有最大或最小排序值的 metrics。 例如,这会获取文档中 s 字段的最大值所对应的 m 字段的值:
POST /test/_bulk?refresh
{"index":{}}
{"s":1,"m":3.1415}
{"index":{}}
{"…
Elasticsearch:在 Elasticsearch 中计算摄取延迟并存储摄取时间以提高可观察性
使用 Elasticsearch 查看和分析数据时,经常会看到使用在远程/受监控系统上生成的时间戳的可视化、监控和警报解决方案。 但是,使用远程生成的时间戳可能存在风险。
如果远程事件的发生与事件到达 Elasticsearch 之间存在延迟,或者如果远程系…

球馆的坪效和人效是什么?
球馆盈利的两大核心你知道吗?球馆想要赚钱,就要注意这两个指标坪效和人效。那什么是坪效呢?就是每平面积上可以产出的营业额。坪效的核心是场地利用率和客单价。对于坪效,小编给大家三个建议:第一,重视散客收入。以篮…
python连接数据库进行各种操作
以PG数据库的使用为例:
1、定义PostGreSQL类
定义了一个PG数据类,里面包含对数据库的各种操作,连接、增删改查等。
import psycopg2
import pandas as pd
import matplotlib as mpl
#解决中文显示问题
mpl.rcParams[font.sans-serif] [uS…

Apache DophinScheduler 定时调度Python脚本
前言
本文通过定时调度Python的例子演示了Apache DophinScheduler 的基本操作:
创建租户指定用户的租户创建Python环境创建项目创建工作流上线项目设置调度时间上线定时管理查看日志
1.创建租户
安全中心 -> 租户管理 -> 创建租户 这一步是将操作系统的账…

疫情结束,数字化还在继续,“无代码”趋势下谁是受益者?
“低代码”与“无代码”“无代码”与“低代码”的概念往往是关联出现。通常意义上的“无代码”,是一种不需要任何代码的、适用于所有人的数字开发平台。这使得不懂编程的人,能够像组装“积木”那样,轻松地开发出一个新的应用。“低代码”这个…
Python快速入门
文章目录Python快速入门前言1、Python基本介绍2、Python安装&卸载2.1 安装2.2 卸载3、使用PyCharm编写Python程序4、Python基础语法4.1 基础概念4.2 数据类型4.3 运算符4.4 字符串相关操作4.5 input函数4.6 流程控制5、函数5.1 函数基本概念5.2 函数的参数5.3 匿名函数6、数…

银行数字化转型导师坚鹏:数字化时代客户体验管理与卓越厅堂服务
数字化时代客户体验管理与卓越厅堂服务课程背景:
数字化浪潮下,很多网点存在以下问题:
不清楚如何提升网点数字化客户体验?
不清楚网点数字化客户体验应用案例?
不积善成德如何打造网点卓越厅堂服务?
课…

中国制造业连续13年全球第一,MES管理系统,打造竞争新优势
根据工业和信息化部最近发布的数据,在2022年,中国的制造业增加值在全球的占比接近30%,制造业规模已连续13年位居世界第一。根据国家统计局的最新数字,一到二月份,我国的生产值与去年同期相比上升了2.1&…
Apache Doris 系列: 自动分桶(Auto Bucket)
1. 分桶数不规范带来的问题
1.1 分桶数太多
Tablet是Apache Doris的最小物理存储单元,集群中的Tablet数量 分区数 * 分桶数 * 副本数。 分桶数过多会造成FE元数据信息负载过高,从而影响导入和查询性能。一般发生在Apache Doris上线运行一段时间之后&a…

低代码开发入局,同飞股份应用云表自主开发MES管理系统
近日,为了贯彻落实《“十四五”智能制造发展规划》,推动中国从制造大国向制造强国转变,工业和信息化部发布了2023年度“智能制造优秀场景”名单。经过省级有关部门和中央企业的推荐、专家评审、网上公示等程序,同飞股份凭借其“先…
Flink1.17实战教程(第五篇:状态管理)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…

WPS两次变身:超级会员+超级表格,完美逆袭,这次再也不输office
WPS会员变“超级会员”
WPS宣布会员服务升级,将原有的“WPS会员”、“稻壳会员”及“超级会员”进行合并,推出“WPS超级会员”,提供了Pro和基础两个版本套餐。 过去被吐槽的“套娃式”收费被整合,你可以根据日常办公和专业办公的…
PiflowX-JdbcCatalog组件
JdbcCatalog组件
组件说明
通过JDBC协议将Flink连接到关系数据库,目前支持Postgres Catalog和MySQL Catalog。
计算引擎
flink
组件分组
Catalog
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子c…
PiflowX组件-FileRead
FileRead组件
组件说明
从文件系统读取。
计算引擎
flink
组件分组
file
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子pathpath“”无是文件路径。hdfs://server1:8020/flink/test/text.txtfor…

热评云厂商:品高云4.62亿元,发力行业云,掘金实属不易
全球云观察《云白皮书(2020-2021)》热评云厂商60家之四十六 2020年6月29日广州市品高软件股份有限公司由民生证券作为保荐机构提交了上交所科创板的IPO注册,目前为止还没有正式公开发行。
那么从招股书可以看到其近年来的营收与利润表现。20…

全球最具创新力科技公司排名,华为力压三星排第一是真的吗?
到底哪些科技公司最有创新力,消费者心目中都可能有一些名字。最近网站Capital on Tap就公布了2021年度最具创新力的25家科技公司排名,华为再一次压过三星电子夺得冠军,不过仔细分析排行榜,却发现三星其实更胜一筹。
Capital on T…
微软Office Plus吊打WPS Office?不一定,WPS未来被它“拿捏”了
微软Office Plus吊打WPS Office?
微软的Office是一款非常强大的软件。不仅仅在办公领域中能给我们带来便利,在娱乐和生活的各个方面的管理也能带来很多便利。
当然,作为国产办公软件的排头兵WPS与微软Office的抗衡已经有长达30多年…
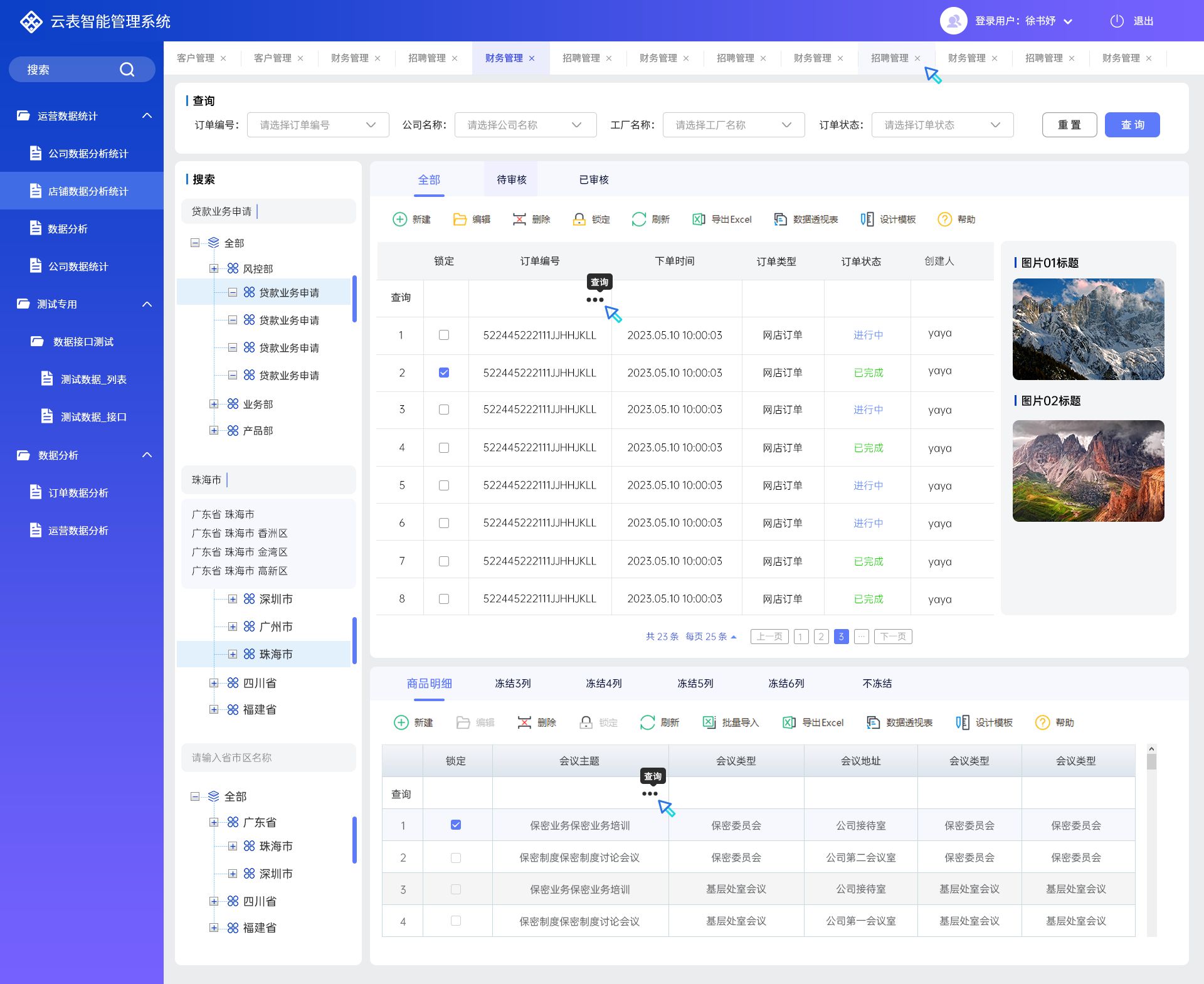
中国芯片天才惊艳全球,三年破欧美封锁,缔造业界神话
有一位杰出的中国人,她凭借自身的才华与毅力终结了欧美国家在芯片技术领域长达十年之久的垄断地位,成为业界瞩目、值得国人热烈追捧的科技巨星。那么,这位令欧美芯片行业为之震撼的人物究竟是谁?她又是如何成功打破这一高壁垒的技…
虚拟人,会成为品牌下一次逆势的解药吗?
如果说2021年是虚拟偶像的崛起元年,那2022可以称得上是爆发期了,一方面,定位国风、时尚博主、模特、歌手的虚拟偶像数量激增,被冠以“首位”、“行业第一”等称号的新面孔轮番出道;其次,虚拟人与品牌的商业…

WMS系统解决方案,数据从“人工采集”转为“自动采集”
今年以来,新冠疫情危机促使国内企业重新审视自我发展,加速了行业转型的步伐。很多制造企业放慢了规模扩张的脚步,应需而变,从规模速度型向质量效率型转型升级。纵观市场现状,很多制造企业面临产能过剩、成本上升、库存…

mtb10_Presentations_tableau Animation(pages) to pdf to png or Animation
All Tableau authors are essentially storytellers. Analyzing data is more than just puzzle- solving; it is a search for a story that will make a difference. Topics can range from Airbnb爱彼迎(美国短租平台) to the Zika virus[ˈziːkə ˈvaɪrəs]寨卡病毒, an…

购买WMS系统前,有搞清楚与ERP仓库模块的区别吗
经常有朋友在后台询问我们关于WMS系统的问题,他们自己也有ERP系统,但是总觉得好像还差了点什么,不知道是什么。今天,我想通过本文,来向您简要地阐述ERP与WMS系统在仓储管理上的不同之处。
ERP仓库是以财务为导向的&…

互联网+无代码组合拳,实现企业效率“狂飙”
公司成立至今,一直秉承“稳定价格、保证供给”的经营宗旨,大力倡导“责任大于能力、意志造就奇迹”的经营理念。要把国企制度与市场机制结合起来,创新创新模式,努力打造优质高效、价廉物美的物资采购与供给平台。公司坚持以结构调…

新一代MES管理系统核心要素,实现中国制造2025弯道超车
随着MES管理系统在制造业中的应用的快速发展,更多的制造业企业已经采购或自行研发出了适用于自身的MES管理系统,并且都是以实现智能工厂(车间)为目标。我国的MES行业中,大大小小的有几百个,国外的也有不少&…

大数据5V特点 --- 5Vs of Big Data
IBM提出了大数据”5V”特点: 一、Volume:数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
二、Variety…

如何申请国家自然科学基金报告学习体会
报告简单背景描述
3位专家: 报告一:自科基金申请与创新人才成长
报告时间:2021年12月5日(星期日)09:00-10:00
报 告 人:高新波 教授
报告人简介:
高新波,博士,教授&…

赞叹不已,精选三款好用的宝藏级软件,还可以白嫖,资源都给你
直接上干货!尤其是第三款软件,绝对称得上的是干货里的干货,你要不花一分钟去看,错过了要扼腕叹息。
软件一:Pot Player
Pot Player是一款简单实用的视频播放器。
发现不愧是良心软件,大小只有20M࿰…

我们要被淘汰了?从科技变革看"ChatGPT"与"无代码开发"
现在只要一上网,就能看见GPT都在说“好厉害”、“太牛了”、“新技术要诞生了”、“我们人类要被淘汰了”之类的话题。但是这伟大的技术变革到底给我们带来了什么呢?答案好像又比较模糊。现在ChatGPT的代写、问答,以及开始做的搜索、办公是目…

MES系统是什么?它如何帮助企业提高生产效率?
随着制造业的发展,越来越多的企业开始使用全面的制造执行系统(MES)来管理其生产过程。那么,MES系统到底是什么呢?它又是如何帮助企业提高生产效率的呢?本文将为大家详细介绍。 一、MES系统的概念 MES系统是…

Flink1.17实战教程(第四篇:处理函数)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…

Flink1.17实战教程(第二篇:DataStream API)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…
PiflowX组件-FileWrite
FileWrite组件
组件说明
往文件系统写入。
计算引擎
flink
组件分组
file
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子pathpath“”无是文件路径。hdfs://server1:8020/flink/test/text.txtfo…
Hadoop2.9.2+Spark2.4.8安装
版本如下: Hadoop2.9.2 spark2.4.8 Scala2.11.12 Linux:CentOS7.4 四台机器hostname设置如下: ambari.master.hadoop ambari.node1.hadoop ambari.node2.hadoop ambari.node3.hadoop spark作为主节点,其它三个是计算节点。 环境…
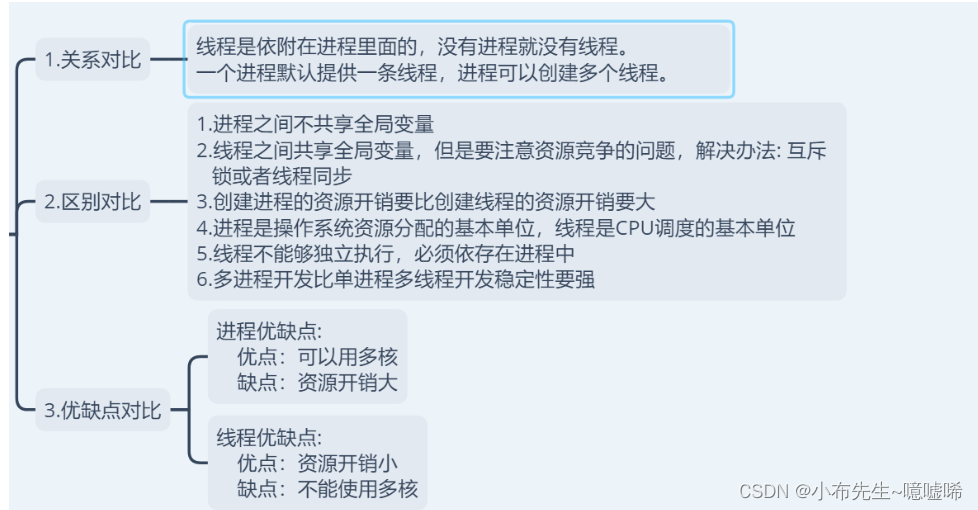
Python 闭包装饰器和多任务--闭包,装饰器,进程,线程
1.闭包案例 在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包.
外层函数: config_name(),外层函数中的变量是 name
内层函数: inner(),inner()使用了外层函数的变…

MySQL3--数据库优化:索引、主从复制、集群、锁
一、数据库优化思想 1、SQL性能下降原因 查询语句不好索引失效:单值,复合关联查询太多(jion)服务器各个参数设置待调优(缓冲、线程数等)执行时间长,等待时间长
2、数据库调优
(1&a…
大数据应用——Linux常用的命令
帮助命令1.基本语法 help 命令 (功能描述:获得shell内置命令的帮助信息)2.案例实操(1)查看cd命令的帮助信息[roothadoop01 ~]# help cd常用快捷键 常用快捷键功能ctrl c停止进程ctrll清屏&…

无纸化、自动化、智能化|WMS系统升级你的仓储管理模式
随着物流行业的不断发展,现代仓储管理已经从传统的手工操作逐渐转向无纸化、自动化、智能化管理。WMS系统作为一种全新的仓储管理模式,正在逐步被企业所接受和运用。 什么是WMS系统? WMS系统全称为Warehouse Management System,即…

乱象频现|如何在选用“低/无代码平台”时避坑?
在2023新年伊始,原本因为疫情而略微沉寂的低/无代码市场,突然之间变得异常活跃。大家对“低/无代码”有了新的期望! 近年来,随着数字化转型的深入推进,越来越多的企业开始探索采用低/无代码平台进行应用开发࿰…

探究MES系统:工业生产数字化转型的必需品
随着时代的发展,工业生产数字化转型已经成为不可避免的趋势。而MES系统作为工业生产运营管理领域中的一种重要软件系统,更是在数字化转型过程中扮演着重要的角色。
什么是MES系统
MES系统全称为制造执行系统(Manufacturing Execution Syste…
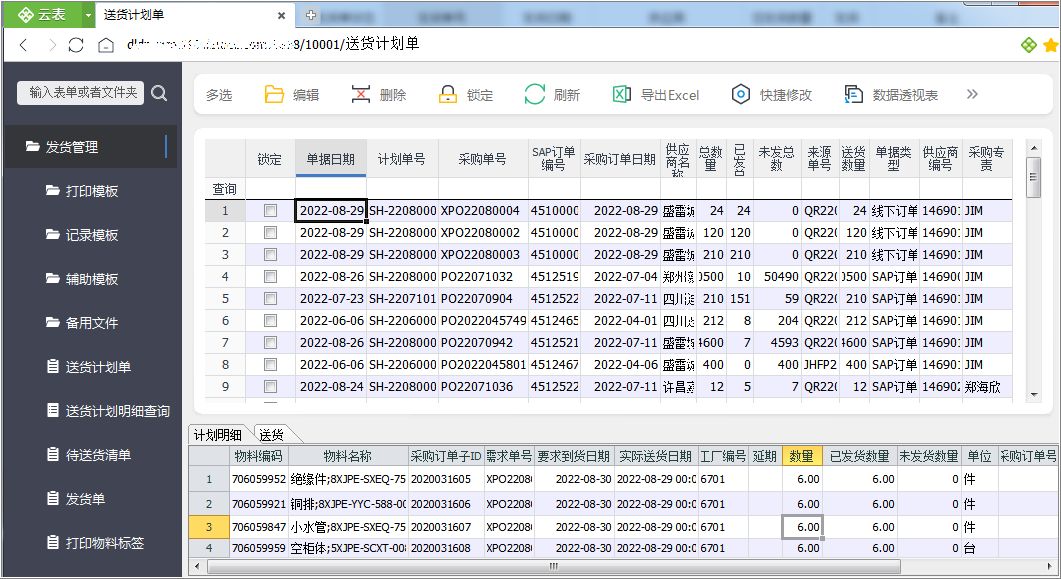
金山衍生新软件,wps,excel用户已在用,Access用户:以后就它了
我们常会用到微软的办公软件Word、Excel、PPT、Outlook,但在数据处理方面还是得看Access。Access用简短的表述来说就是微软开发的一个关系数据库管理系统。★好用,可门槛高,够不着
为啥说数据处理得看Access呢?举个例子࿰…
发展人工智能必须要考虑安全问题,这已是现实问题
但是从长远来看,必须得走人类智能这条路,为什么?因为我们最终是要发展人机协同,人类和机器和谐共处的世界。我们不是说将来什么事情都让机器去管去做,人类在一边享受。我们要走人机共生这条路,这样机器的智…
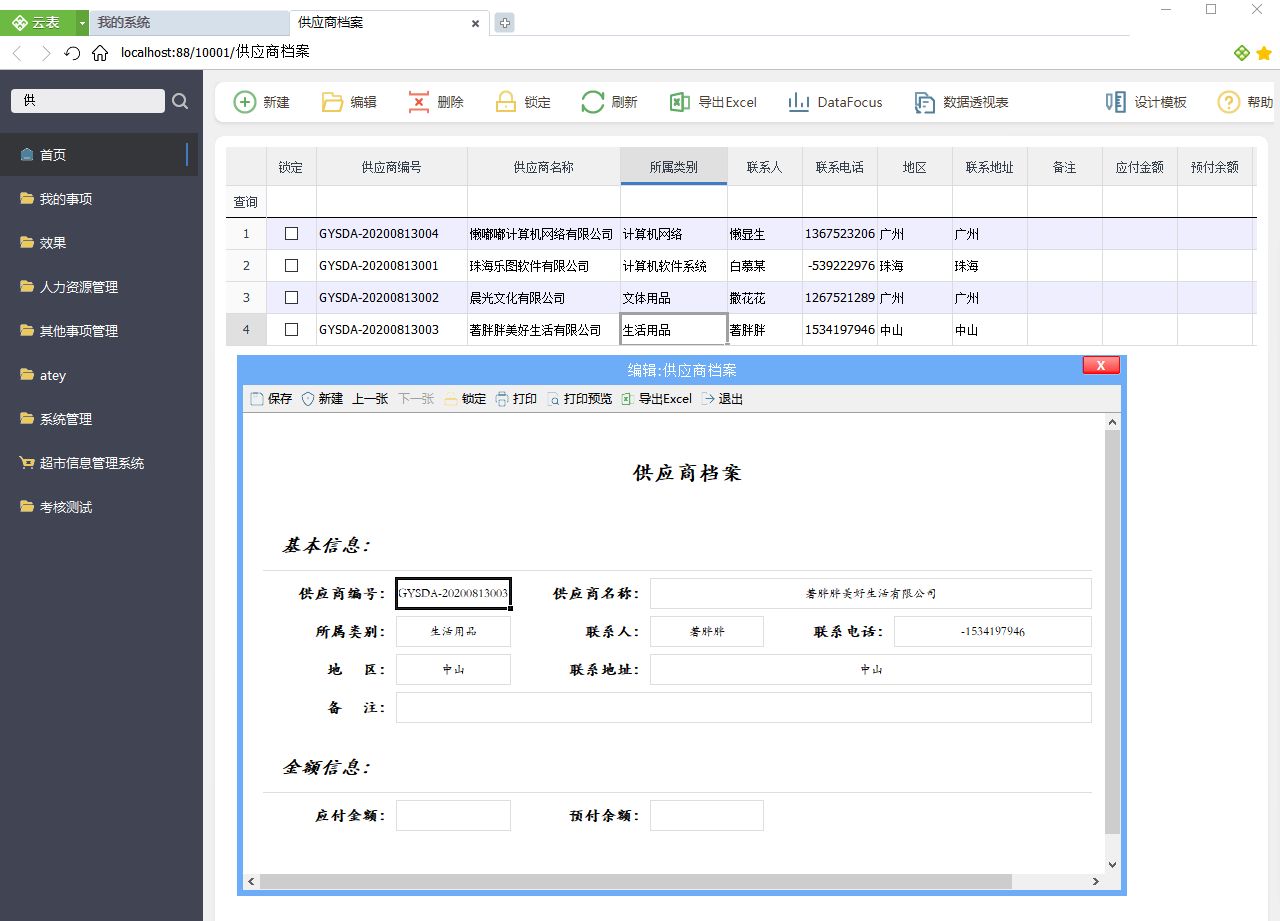
接连三预测成真,75%的参与率,华为、阿里、腾讯纷纷介入
Cartner预测:75%参与率
去年,Cartner预测,75%的大型企业将使用至少四种低代码/无代码开发工具,用于IT应用开发! 可以感受的到,这几年低代码以突飞猛进的速度在各领域中得到应用。可以预见的是,…
通过数字零售的蜕变来找到推倒烟囱的方式和方法
深耕留量时代,仅仅只是依靠新零售和数字零售式的赋能与改造是不行的。我们需要的是对于传统零售的内在元素、既定流程、固定形态进行一场深度而又全面的变革,才能真正激活留量,让留量持续复购,从而达成「纵向」上的发展。 同流…
Impala事故处理手册
Impala事故处理手册
本文不是事故原因汇总,只介绍当Impala集群出现事故时的处理流程,以最大限度保留现场信息,方便事后调查。第一节介绍故障表现和对应的操作建议,第二节介绍每个操作的具体执行流程。本文将不定期更新࿰…

突然优化500多项软件功能,科技巨头戴尔为何加快存储革新?
一直以来企业存储都处于大家关注的焦点中,毕竟这是关乎用户数据价值的基石。
当然,大家熟知的事实是,企业存储的全球市场格局早已形成,存储巨头各自在既定的计划与战略中不断前行。就全球存储市场总体而言,近年来的发…
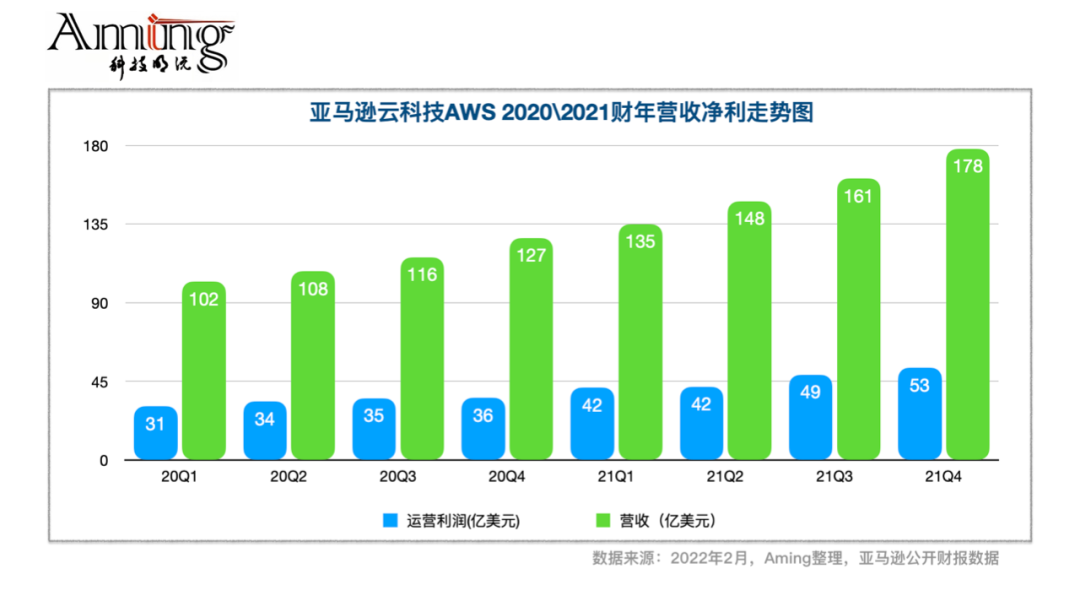
多亏了云业务的持续爆发增长,亚马逊整体营收净利表现惊人
【科技明说 | 每日看点】对于亚马逊公司而言,云业务战略的成功带来了整体营收与净利润的持续惊人表现。最新财报数据显示2021财年亚马逊公司整体营收为4698亿美元,与2020财年的3861亿美元相比增长22%;净利润达到334亿美元…
付费内推实习是“割韭菜”吗?超级实习生计划也在割韭菜?
近期知名企业发布的2021年反舞弊通报中,有员工利用职权招收实习生并安排虚假远程实,从中获得了实习费用,虽然相关人员已受到想用处罚,但是去一些平台搜索“付费内推实习”,价位从100元-1000元不等,商家仍然…

怎样才能成为一朵不人云亦云的云?
有人问我,目前市场上到底有多少云?
从全球云观察历年的统计与总结来看,市面上可以看到与云相关的品牌名字不会低于100家。
然而,做云,最怕人云亦云。云这么多,怎样才能成为一朵不人云亦云的云?
事实上&…

儿童生长发育迟缓的鉴别和干预
(英国)国家临床医学研究所(NICE)2017年发布关于婴儿/儿童生长发育迟缓的鉴别、评估和监测的指南,该指南确定了生长发育的界值,指出了诱因及危险因素,并提出了干预的方案。
▼Part1:…

热评云厂商:中科曙光4.68亿元,坚守城市云扩展政务云
全球云观察《云白皮书(2020-2021)》热评云厂商60家之四十五 据财报显示,中科曙光2020年营收为101.61亿元,同比增长6.66%。归属于上市公司股东的净利润为8.22亿元,同比增长38.53%。那么在云计算方面的发展情况如何呢&am…

云表无代码开发平台,助力制造业练就数字化转型"硬功"
制造业作为国民经济的基础,也是我国的支柱产业,对我国经济发展具有重要意义。但随着近年来我国制造业转型升级步伐的加快,我国制造业在发展过程中也面临着许多困难和挑战。比如:企业生产设备老化、生产过程自动化程度低、产品质量…
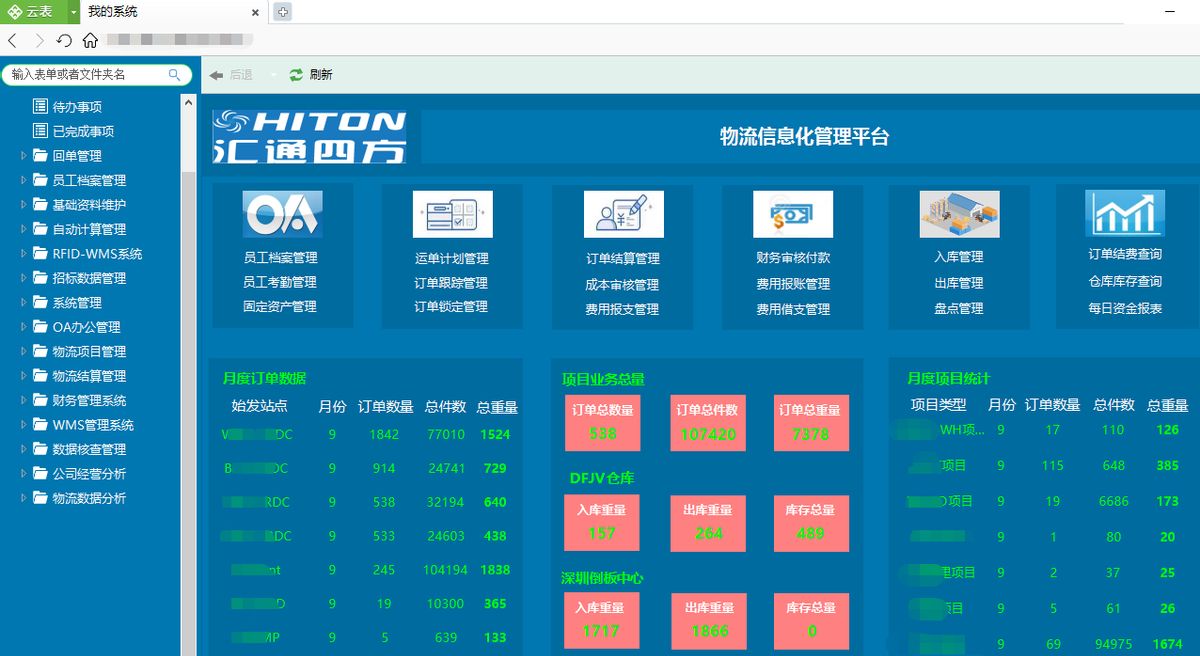
对不起,我们不招还在用Excel的人,和金山系新秀比起差太远了
相信点进来的朋友曾经也深受Excel荼毒。
的确,现如今在网上随便一搜,关于Excel的学习资料和答疑解惑的帖子不胜枚举,盖因为Excel有时太过热心,当然,是帮倒忙的那种热心。 自动把天数转换为日期,还替你把身…

时至今日,Pascal系列Turbo Pascal 5.0依旧是我心中永远的神
从DOS时代到Windows时代,从桌面应用到Web应用,每一个时代都有它特定的编程工具 在我看来,DOS时代的编程语言,Pascal必占一席之地。
尤其是Turbo Pascal系列的最后一个版本——Turbo Pascal 5.0,更是我心目中永不褪色的…

从NAND到SSD,坚信闪存“革命”,英特尔闪存创新加速
9月15-16日,2021开放数据中心峰会在北京国际会议中心顺利举办。为进一步加快数据中心绿色低碳发展,提高数据中心算力算效水平,优化数据中心智能化运营能力,增强数据中心可靠性和服务能力,大会公布了DC-Tech数据中心低碳…

Flink从入门到放弃(十二)-企业实战之事件循环驱动型场景(二)
上文Flink从入门到放弃(十二)-企业实战之事件驱动型场景踩坑(一)为大家介绍了Flink基于事件驱动场景下的渠道流量分析实时需求以及遇到的坑。 本文继续讲解基于事件驱动场景来讲解下关于响应时效、服务质量类的需求方案设计以及遇到的坑 (关于Flink主题的所有文章已…
人们越来越担心MogaFX外汇储备的减少
10月,韩国银行(BOK)出售美元储备,作为防止本币对美元大幅贬值的努力的一部分,韩国外汇储备再次扩大了损失。尽管政府表示该国仍有充足的外汇储备,但专家们敦促政府采取先发制人的措施,因为在外部…
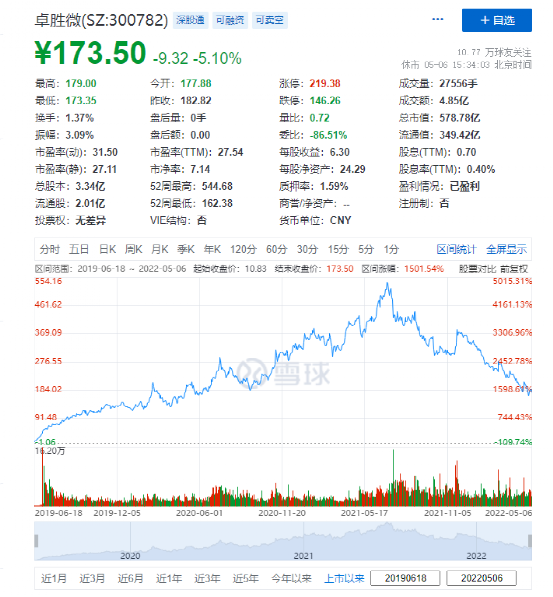
卓胜微:国产替代泡沫破灭
A股射频芯片企业卓胜微,自2019年6月18日上市至2021年上半年,公司股价一路飙涨。卓胜微上市初每股发行价35.29元,股价在2021年6月30日达到544.68元/股的顶峰,涨幅达1443.44%。
但在近期最低价却低至162.38元/股,当下股…

新能源汽车,不需要“共享充电宝”
新能源趋势是不争的事实,从储能到补能,电池技术停滞不前,补能方式也同样迭代缓慢。
1月18日,宁德时代全资子公司时代电服推出换电品牌EVOGO。
困扰换电模式发展的标准化难题,看似有了新的解法。市占率第一的宁德时代…

淘特,阿里在下沉市场的一把好刀
阿里在下沉市场有了一把好刀。
10月9日,刚成为阿里合伙人的陶特事业部总经理汪海(花名:七公)做了一场题为“创业500天”的演讲。他在演讲中谈到了陶特的初心,分享了陶特发展过程中的三组故事。
虽然这是一场“故事会…

hadoop报错:HADOOP_HOME and hadoop.home.dir are unset. 解决方法
目录报错信息解决方法1.下载apache-hadoop-3.1.0-winutils-master2.解压到宿主机3.添加环境变量4.重启IDEA或eclipse报错信息
java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
java…

自定义分区并区内排序
简单的wordCount
假设我们的文件中有这么一些数据:
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spark
spark
hive
hadoop
spa…

Esaypoi简单使用
1.使用背景
最近笔者的代码涉及到了excel的导出 一开始笔者是直接原生使用poi,自己书写导出规则, 毫无疑问,是利用反射机制书写的,但有时总不可避免有些新的导出规则需要书写 后来接触到了easypoi,发现其确实好用&…
微软杀疯了,谷歌蒸发1000亿市值作陪,中文编程和它却打起翻身仗
微软VS谷歌,究竟谁是最后赢家?
当微软宣布收购OpenAI开发的ChatGPT的决定一出,Google深感威胁,开发出Gmail的早期员工甚至大胆预测,Google离完全毁灭只剩下一到两年!
好歹也在互联网之战中屹立多年&#…
Android Room 数据库常见报错missing database
常见错误1:
D:\AndroidProjectsDemo\JetpeckTest\app\build\tmp\kapt3\stubs\debug\com\example\jetpecktest\room\BookDao.
java:15: 错误: There is a problem with the query: [SQLITE_ERROR]
SQL error or missing database (no such table: BookEntity)
publ…
深夜12点,果断卸载Access,3分钟启用国产Access,源自WPS
Access的“忠实粉丝”,你我皆可能是一员
历经20多年迭代的微软Access,因简单易用,在全球吸引了一大批的“忠实粉丝”,你我可能就是其中的一员。
基于Windows操作系统的集成开发的大环境,Access的灵活性和实用性大大提…

工业4.0,为什么数字化转型这么难,上了ERP还要上MES
工业4.0时代,中国制造企业已经面临着与国际先进水平的差距,更多的企业在寻找新的发展道路,数字化转型是制造业企业转型升级的必由之路。但是,许多制造型企业由于在传统生产过程中,业务数据不能得到有效监控、生产过程数…
【天猫erp、发货接口】如何从点击、访客、销量方面提升拼多多流量
现在有很多的商家都入驻拼多多,商家们入驻拼多多的一大目的就是看中了拼多多“薄利多销”的一个点!但是很多商家在入驻开店之后,却发现自己店铺的流量怎么都提升不起来?那么,下面就来讲解一下拼多多流量该怎么提升的问…

1.数据库相关知识点整理
数据库知识点复习: 1.join和left join区别
https://segmentfault.com/a/1190000017369618
当有重复值的时候:
left join,right join,inner join,full join之间的区别 - lijingran - 博客园
2.阿里开发规范:为啥禁止使用外键 案例: 1&…
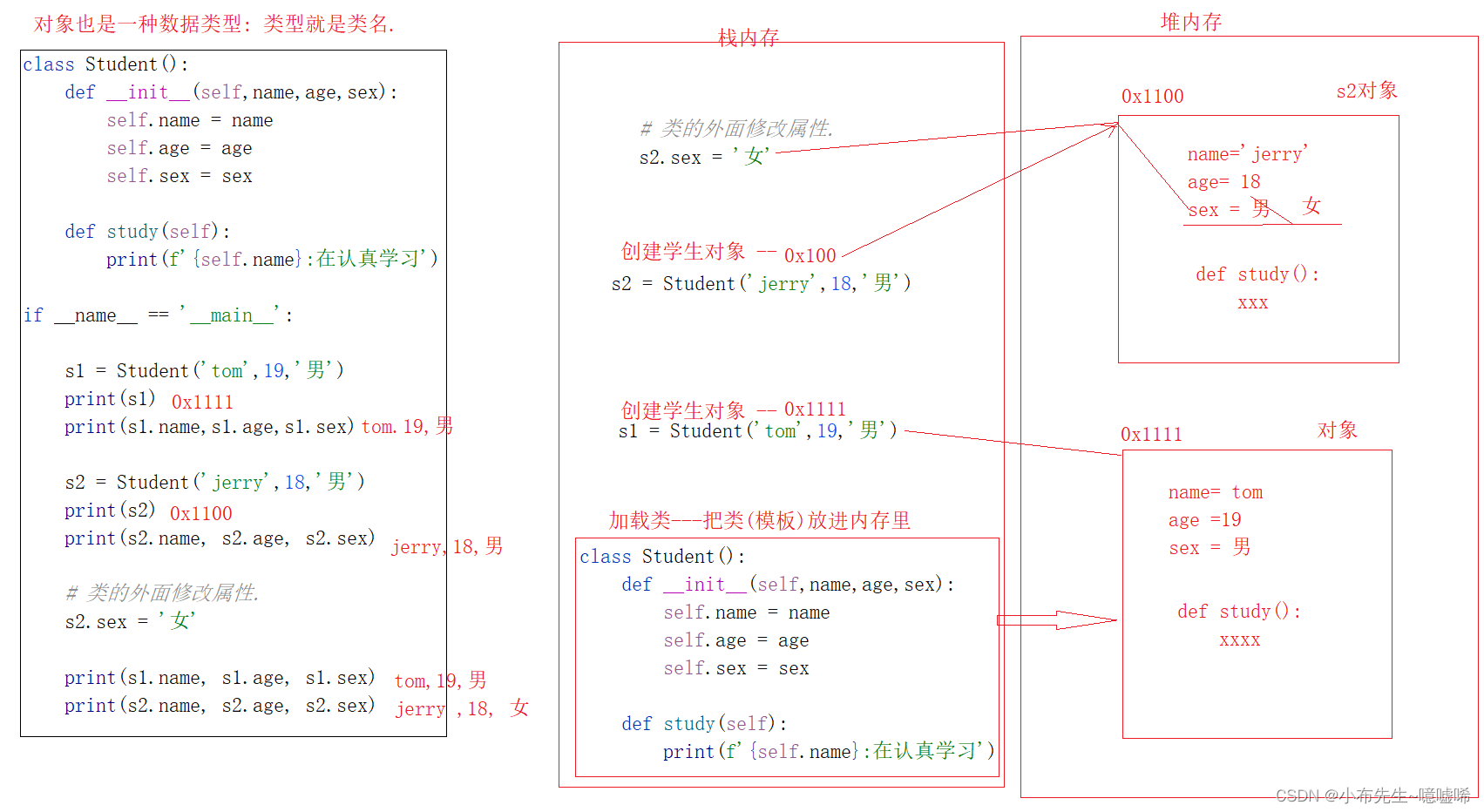
python 面向对象--类,对象,属性,方法,魔法方法
1.理解面向对象思想 面向过程思想: 遇到问题,分析步骤.按照步骤解决问题.(复杂,重复) 面向对象思想: 遇到问题,找到能解决问题的对象去解决.(简单,复用) 2.类和对象 # 定义类的格式:
# class 类名():
# 代码
# ......class Student():
def study(self):print(学生好…

计算机毕业设计Python+Spark招聘推荐系统 招聘大数据分析 招聘数据采集 招聘可视化系统 求职职位推荐系统 求职大数据 招聘小程序app 招聘网站
功能 技术
Hadoop、Vue.js、Spark、SpringBoot、echarts、阿里云短信、百度AI、支付宝沙箱支付、Python、MySQL、协同过滤推荐算法(apache-mahout)
创新点
Spark大数据架构、开源数据采集、大屏数据可视化、短信接口、图片识别、app/小程序移动端、在线支付、协同过滤推荐算…

无代码开发:让程序员更高效,让非编程人员也能参与
说起无代码开发,可能大多数人的第一反应就是:“我不知道!” 作为一种能快速实现复杂系统的软件开发模式,无代码开发目前还处于推广阶段。但在我们看来,无代码开发是一个很好的尝试,它能让程序员更高效&…
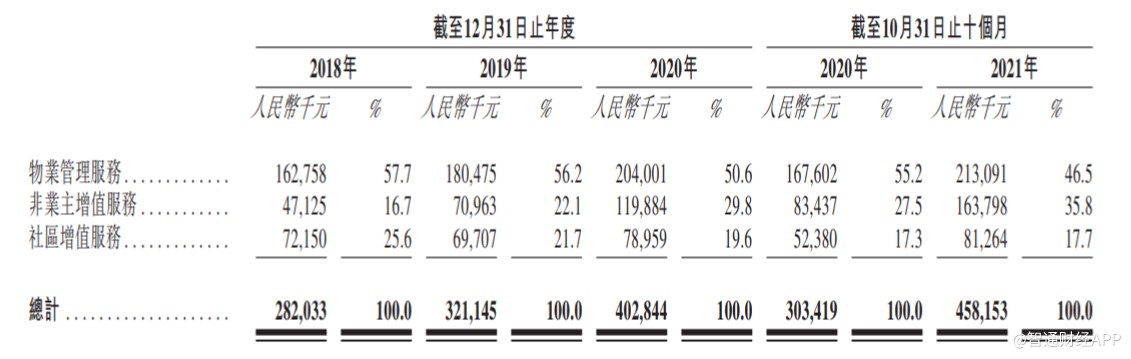
二次递表港交所,鲁商生活服务何时缓解对母公司的依赖症?
2021年5月份,香港联交所上调主板上市的盈利规定,修订后的主板上市盈利规定较此前上调约60%,于2022年1月1日生效。对于正在排队上市或者酝酿上市的公司而言,压力徒增。
据港股研究社了解到,早在2021年7月2日࿰…
1.2 Hadoop
1.2 Hadoop 1.2.1 Hadoop常用端口号 hadoop2.x Hadoop3.x 访问HDFS端口 50070 9870 访问MR执行情况端口 8088 8088 历史服务器 19888 19888 客户端访问集群端口 9000 8020 1.2.2 Hadoop配置文件 配置文件: hadoop2.x core-site.xml、hdfs-site.xml、mapred-site.xml…
计算机毕业设计之SpringBoot+Vue.js高考志愿填写分析推荐系统 高考志愿推荐系统 高考大数据分析 大数据毕业设计(大屏、推荐算法、支付技术)
【技术架构】 高考志愿填写分析推荐系统主要是基于Java语言的技术开发,同时使用SpringBoot框架,利用其自动装配的优点为我们简化许多配置代码;
前端开发主要使用Vue.js来进行页面的展示与布局;
使用阿里云OSS、本地mysql来进行数…

2021年MathorCup高校数学建模挑战赛——大数据竞赛A题
赛道 A:二手车估价问题
随着我国的机动车数量不断增长,人均保有量也随之增加,机动 车以“二手车”形式在流通环节,包括二手车收车、二手车拍卖、二手 车零售、二手车置换等环节的流通需求越来越大。二手车作为一种特 殊的“电商商…
ClickHouse深度解析
一、什么是ClickHouse?
ClickHouse由俄罗斯第一大搜索引擎Yandex于2016年6月发布, 开发语言为C,ClickHouse是一个面向联机分析处理(OLAP)的开源的面向列式存储的DBMS,简称CK, 与Hadoop、Spark这些巨无霸组件相比,ClickHouse很轻量级,查询性能…
flink 相关资料
相关链接 ververica中文网站: https://ververica.cn/ Apache Flink 视频教程: https://github.com/flink-china/flink-training-course Flink Forward Asia 2019: https://ververica.cn/developers/flink-forward-asia-2019/ Flink Forward China 2018: …
2021-09-22 2021年危险化学品生产单位安全生产管理人员考试报名及危险化学品生产单位安全生产管理人员考试资料
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:危险化学品生产单位安全生产管理人员考试报名是安全生产模拟考试一点通生成的,危险化学品生产单位安全生产管理人员证模拟考试题库是根据危险化学品生产单位安全生产管…

写代码?文心一言or文言文,谁更胜一筹?新工具或许可堪重任
中国版的ChatGPT“文心一言”写代码能力尚浅
被称为中国版的“ChatGPT”的“文心一言”可以说是上市几个月了,很多用户都受到了邀请码来体验,遗憾的是,小编早就申请了,但还在排队等待中。虽然没有亲自体验过百度的“文心一言”&a…
2021年A特种设备相关管理(锅炉压力容器压力管道)考试题库及A特种设备相关管理(锅炉压力容器压力管道)最新解析
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:A特种设备相关管理(锅炉压力容器压力管道)考试题库是安全生产模拟考试一点通生成的,A特种设备相关管理(锅炉压力容器压力管道&#…
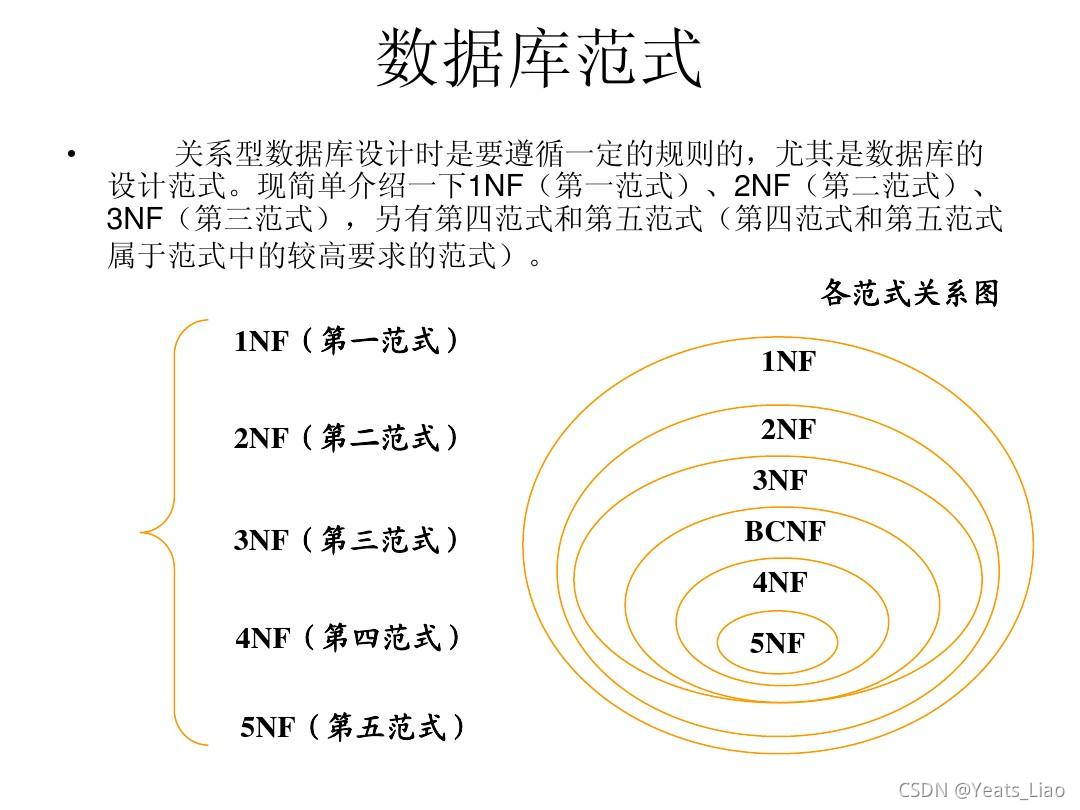
7:数据库设计思维-MySQL
目录7.1 数据库设计的基本概要7.2 实体和实体之间的关系7.3 Codd第一范式:确保每列原子7.4 Codd第二范式:非键字段必须依赖与键字段7.5 Codd第三范式:消除传递依赖7.1 数据库设计的基本概要
表结构就是定义数据表文件名,确定数据…
MES系统选择指南:企业如何选择适合需求的MES管理系统?
MES(Manufacturing Execution System)管理系统是一种用于生产管理的软件系统,可以帮助企业提高生产效率、降低成本和提高质量。然而,不同类型的MES管理系统适用于不同类型的企业需求,因此选择适合自己企业需求的MES管理…

比亚迪销量远超“理小蔚”,“智能化”混战已经来临?
伴随着8月份的结束,国内造车势力纷纷发布了单月新汽车销量。
小鹏、蔚来、理想已经将座次切换到了“理小蔚”。
但值得关注的是,比亚迪在传统汽车领域继续实现领跑,自7月重回全球新能源单月品牌销量榜首之后,比亚迪一路高歌猛进…

2015-2021年考研人数报考统计
2015-2021年考研报考人数趋势图(单位:万人) 近几年,由于考生个人对自身发展的要求提高、毕业生就业压力较大、非全日制研究生考试纳入统考以及研究生招生人数扩大等多重因素的推动下,全国硕士研究生报考人数呈现了逐年上升的态势。
2018年12…
2021年氧化工艺找解析及氧化工艺考试总结
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:氧化工艺找解析根据新氧化工艺考试大纲要求,安全生产模拟考试一点通将氧化工艺模拟考试试题进行汇编,组成一套氧化工艺全真模拟考试试题,学员可…
2021年金属非金属矿井通风免费试题及金属非金属矿井通风考试总结
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:金属非金属矿井通风免费试题参考答案及金属非金属矿井通风考试试题解析是安全生产模拟考试一点通题库老师及金属非金属矿井通风操作证已考过的学员汇总,相对有效帮助金…

毫秒级返回数据,58同城 DBA 团队选择 TDengine 解决传感器数据处理难题
小 T 导读:在 58 同城的驾考业务上,需要存储分析驾校教练车传感器产生的数据,这是典型的时序数据场景,开发人员对原有的 TiDB 性能并不是很满意,因此 DBA 团队开始调研更具针对性的时序数据库。基于自身的业务需求&…
AI发现两个数学新猜想 人工智能拓展在前沿领域应用范围
人工智能治理是和人工智能发展相伴而行的问题。联合国教科文组织当地时间11月25日正式推出《人工智能伦理问题建议书》,该建议书由教科文组织会员国集体通过,是关于人工智能主题的首份全球性规范框架。 该建议书旨在促进人工智能为人类、社会、环境以…
TDengine 在蓝深远望电机物联网监测预警与预测性维护平台中的应用
作者:李凯 蓝深远望 小 T 导读:蓝深远望致力于服务政府及大型国有企事业单位的数字化转型,结合大数据、数字孪生、区块链、网络安全等核心技术,为政府运行、社会服务、城市管理、公共安全、基层治理等领域,提供智能场景…
科学中心有能力重新定义城市社区及其周围环境 为可持续发展助力
在缺少能见度和没有GPS的未知区域,利用无人机代替人工,关键时刻可能可以挽救生命。以水电输水隧道的人工检测为例:耗时、成本高且不精确,另外会带来健康和安全风险,例如跌落、结构倒塌、危险气体泄漏甚至爆炸。 由…
elasticsearch 添加,修改_mapping
创建索引及_mapping
PUT test_mapping
{"mappings": {"test": {"dynamic_templates": [{"string_fields": {"match": "*","match_mapping_type": "string","mapping": {"ana…

Kafka 根据指定时间消费数据
背景
在kafka的实际应用过程中,由于数据处理问题,需要对kafka中的数据进行重新消费。重新消费数据一般都是使用一个新的groupId,但默认的配置是earliest(当各分区下有已提交的offset时,从提交的offset开始消费;无提交…
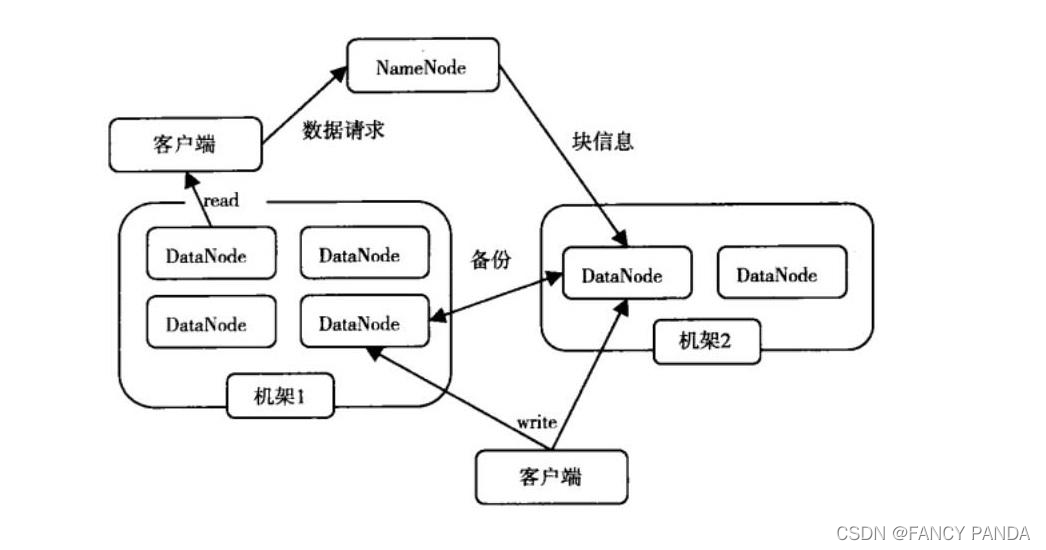
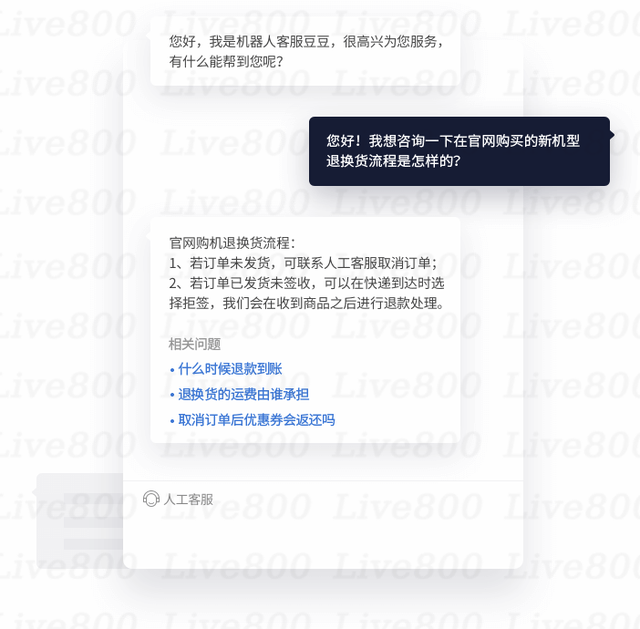
Live800:智能客服与人工客服谁能更胜一筹?
科技改变生活,而智能客服改变客服行业。
随着互联网技术不断发展,越来越多的新名词、新技术涌入我们的生活,从早期的社交媒体碎片化,到互联网,再到新零售,先进的理念和技术给我们带来新的改变,…

ELK+Kafka+Filebeat 企业内部日志分析系统(版本6.5.4)
文章目录一、ELK1、组件介绍(1)Elasticsearch(2)Logstash(3)Kibana2、环境介绍3、版本说明二、ELK 实施部署1、 Elasticsearch部署(1)安装配置jdk8(2)安装配置…

计算机毕业设计之Python+Spark汽车推荐系统 汽车可视化 汽车数据分析 汽车大数据 汽车推荐app 汽车小程序 大数据毕业设计 汽车爬虫
功能 最近移动端的沙箱支付不太稳定,经常报订单不存在,可以不管,直接多点几次,仍然可以支付的。
Vue spark 懂车帝汽车大数据大屏
技术
基于spark java API
实现分析功能 基础情况:预约流程、汽车经纪人、用户统计…

Linux中的数据库管理程序mariadb
常用的命令:初始化mariaDB服务: 首先安装我们的mariadb服务 [rootlocalhost ~]# dnf install mariadb mariadb-server -y 在确认mariadb数据库软件程序安装完毕并成功启动后请不要立即使用。为了确保数据库的安全性和正常运转,需要先对数据库程序进行初…
用go语言实现一个日志搜集工具
data-agent
一、简介
简称“数据代理”,实现的初始目的是用go语言实现ELK中和logstash一样收集、解析和转换日志的工具。logstash的性能问题比它的替代者来比的话还是差了一些。Filebeat采用了go语言开发,它重构了logstash采集器源码,性…

《Hadoop 3大数据技术快速入门(大数据技术丛书)》写得很通俗,适合快速入门
#好书推荐##好书奇遇季#《Hadoop 3大数据技术快速入门(大数据技术丛书)》,京东当当天猫都有发售。本书写得通俗易懂、快速理解、无痛入门,适合零基础开发人员以及大数据岗位应聘人员。 当前已完全进入大数据时代,人们忽…

Redis作为高速缓存和数据库的数据一致性的问题,如果数据更新的话是先更新数据库还是先更新缓存?如果先更新数据库再更新缓存会涉及什么问题
首先,缓存由于其高并发和高性能的特性,已经在项目中被广泛使用。在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。 但是在更新缓存方面,对于更新完数据库,是更新缓存呢,还是删除…

【大数据入门核心技术-Ambari】(一)Ambari介绍
一、什么是Ambari Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。 Apache Ambari 支持HDFS、MapReduce、Hive、Pi…

科普:什么是企业的数字化转型,OA有何作用?
在当前的社会,技术巨变,新基建概念的提出,让企业信息化、数字化成为了一种必然的趋势。
企业的数字化转型是什么?
所谓的数字化转型,即利用数字化技术推动企业/组织/单位对其组织架构、业务模式等等方面进行新的变革…
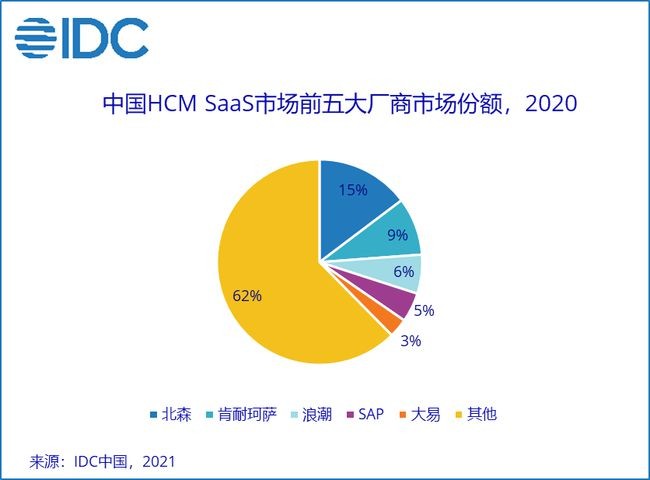
毛利率超60%却仍旧亏损,HR SaaS第一股北森的价值几何?
企业对人才管理的高需求与日俱增,加之数字化转型的推动,人力资源信息化管理顺势而生。北森在HR SaaS行业沉淀了十年,去年5月,“北森云计算”在宣布完成F轮融资2.6亿美金,这也是HR SaaS赛道迄今为止最大的单笔融资。
1…
![微服务拆分[转载]](https://img-blog.csdnimg.cn/a2daf588da404a36b689a4edf8f6ab5c.png)
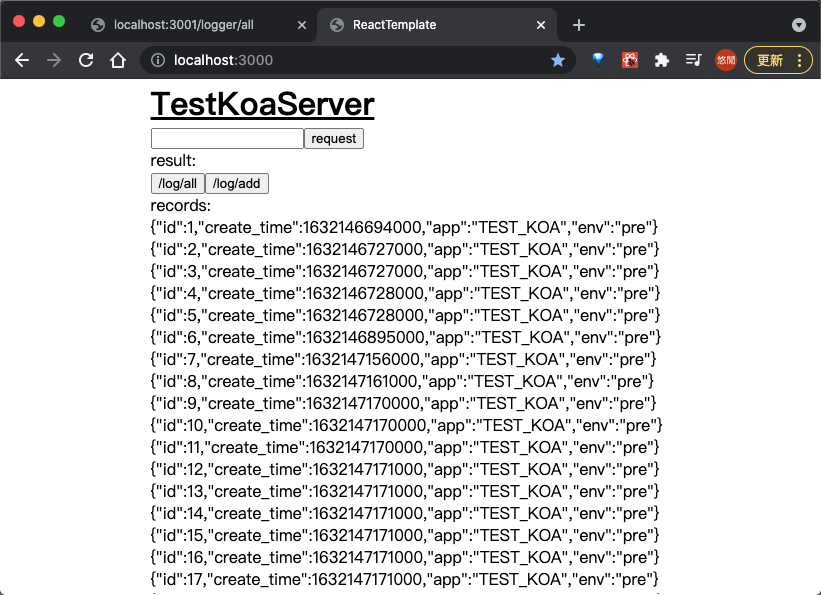
Koa 项目启动: 从脚手架到自定义项目(连接 mysql 数据库)
Koa 项目启动: 从脚手架到自定义项目(&连接 mysql 数据库) 文章目录Koa 项目启动: 从脚手架到自定义项目(&连接 mysql 数据库)前言正文1. 官方脚手架生成项目解析1.1 安装脚手架 生成项目1.2 目录结构1.3 中间件配置1.4 …
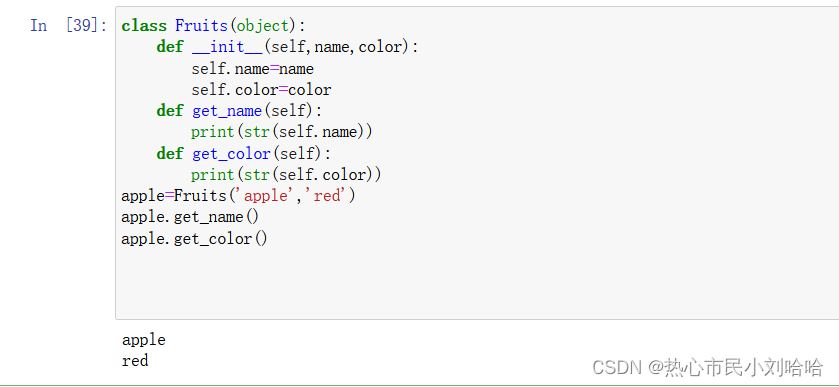
大数据与人工智能协会 机器学习小组 测试试题纠错
文章目录前言机器学习方面激活函数:激活函数的作用:常用的激活函数:批量梯度下降(Batch Gradient Descent,BGD)随机梯度下降(Stochastic Gradient Descent,SGD)交叉熵损失…
LoadRunner 在负载下对基于 Web 的应用程序进行测试的过程
1、计划测试
定义明确的测试计划将确保制定的 LoadRunner场景能完成您的负载测试目标。
2、创建 Vuser 脚本
Vuser通过与基于 Web 的应用程序的交互来模拟真实用户。Vuser 脚本包含场景执行期间每个 Vuser 执行的操作。 (1)每个 Vuser 执行 &…
【无标题】2022年危险化学品经营单位主要负责人考试内容及危险化学品经营单位主要负责人考试试卷
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:危险化学品经营单位主要负责人考试内容是安全生产模拟考试一点通总题库中生成的一套危险化学品经营单位主要负责人考试试卷,安全生产模拟考试一点通上危险化学品经营单…
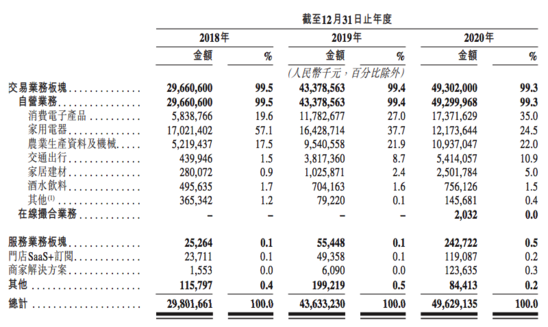
获阿里与央企基金战略投资,汇通达IPO能否领跑农村电商?
自拼多多上市以来,“下沉市场”成为资本市场关注的一个大热点。阿里、京东等纷纷下场瓜分存量市场。同时,也有不少农村电商平台被资本看好。
根据东方财富网消息,了解到汇通达网络股份有限公司通过港交所上市聆讯,预计近日在香港…

坎坷的国际化战略,快手裁员能否走出困境?
据澎湃新闻报道,快手科技年末的裁员潮还在继续。1月4日,多位快手内部员工表示,快手从去年年底开启较大范围裁员,覆盖电商、商业化、国际化、游戏四大事业部,个别团队裁员比例达到30%。
澎湃新闻记者就裁员一事向快手求…
2021年裂解(裂化)工艺考试报名及裂解(裂化)工艺复审模拟考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:裂解(裂化)工艺考试报名参考答案及裂解(裂化)工艺考试试题解析是安全生产模拟考试一点通题库老师及裂解(裂化࿰…
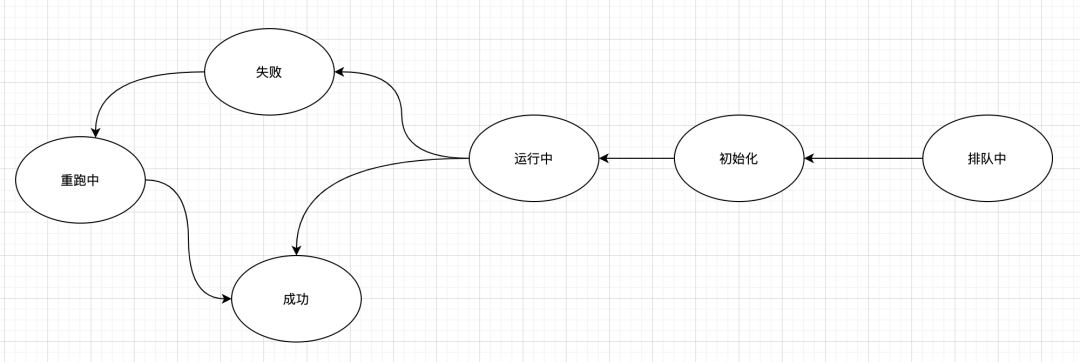
(全网首篇)数仓专题-及时性保障方案
在数仓的建设之路中,其中必不可少的一个依赖组件就是调度系统。目前市面上也有很多优秀产品,如以DAG为核心的工作流系统:Azkaban、Oozie、Airflow、DolphinScheduler;以Quartz为代表的定时系统包括Elastic-Job、Xxl-Job、Saturn、…

业绩收入严重依赖五大客户,耐看娱乐能借IPO说出好故事吗?
2021年,影视行业依旧在调整期。
多方压力的同时来袭,对于领域内公司的抗风险能力要求更为严格。而在这样一个大环境下,耐看娱乐却迈出了上市步伐。据港交所1月3日晚间披露,耐看娱乐控股有限公司向港交所主板提交上市申请…

物流赛道加速内卷,安迅上市能否博得更大席位?
继2016-2018年的上市潮后,2021年物流行业的上市热潮再次掀起。
5月,京东物流率先在港交所上市,市值一度超2900亿港元;同月,日日顺正式向创业板递交招股书申报稿;福佑卡车向美国证券交易委员会递交招股书&…
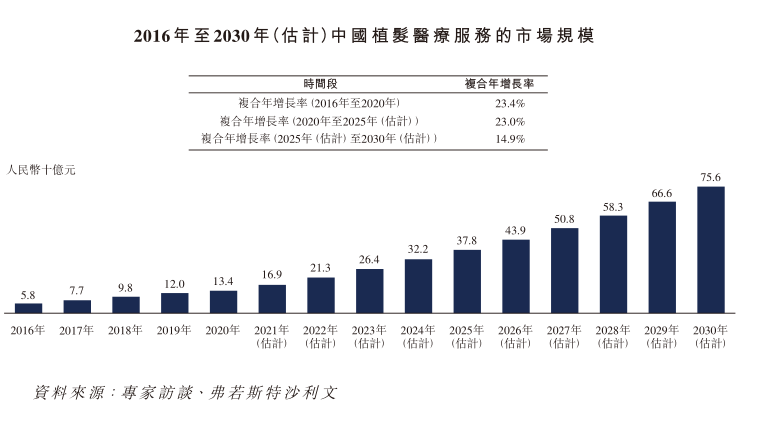
IPO进度提速,尽显“头”部优势的雍禾医疗却披着广告公司的里子?
士为知己者死,女为悦己者容。自古以来,女性对美的追求就从未停止过。
现如今,当颜值经济愈演愈烈,紧随而来还有大众的容貌焦虑。“动动脸”、“削削骨”、“植植发”等相关医美项目逐渐发展起来。
近日,据港交所文件…
小区车辆乱停、占位引纠纷,捷径智慧物业系统提出解决方案
小区车辆乱停、占位引纠纷,捷径智慧物业系统提出解决方案
众所周知,物业承担着小区的后勤服务,帮助业主解决生活上的众多困扰。
由此可见,小区物业的管理水平和居民的居住体验有着密切的联系,小区的物业质量也因此成…

京东发布2021年第三季度财报 京东云强化基础技术 加速助推“数实融合”
11月18日,京东集团(纳斯达克股票代码:JD,港交所股票代号:9618)对外发布了2021年第三季度业绩。京东集团净收入为2187亿元人民币(约339亿美元),同比增长25.5%。其中96%的成…

自学运维真的学不下去了,有靠谱的培训班吗?
选机构我是从这几个方面来看的-------- 1、生源质量
生源决定一切,一家机构的生源质量可以直观反映出机构的质量,入学的人水平高,那么教学的人水平就不能低。有些机构为了利益可是连初中毕业的学生也招收,虽说IT行业技术是核心&a…

“瘦家电”站上天猫超市C位,年轻人如何撑起千亿细分市场?
在如火如荼的电商双十一期间,小家电又站上了C位。
据京东家电10月31日晚8点销售统计的数据显示:
家用洗地机开售1小时销量同比增长近7倍;
京品九阳免洗破壁机1小时成交额同比增长200%;
无雾加湿器前4小时成交额同比增长近5倍&…
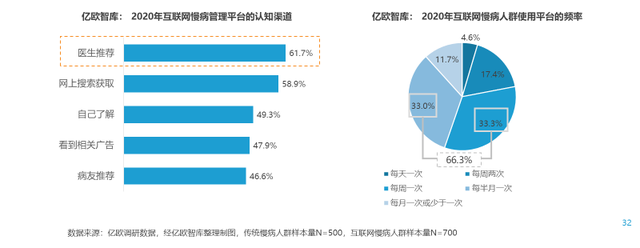
扎堆涌入“慢病管理”赛区,互联网医疗们看见了怎样的未来?
医药健康领域或许从来不缺踏浪前行的追梦者。
从最初的医药电商,到一步步向着互联网医疗深水区进发,医药健康玩家们的打法演变似乎成为互联网医疗领域的一部缩影。
值得一提的是,在近日的进博会上,百度健康、平安健康这些国内互…
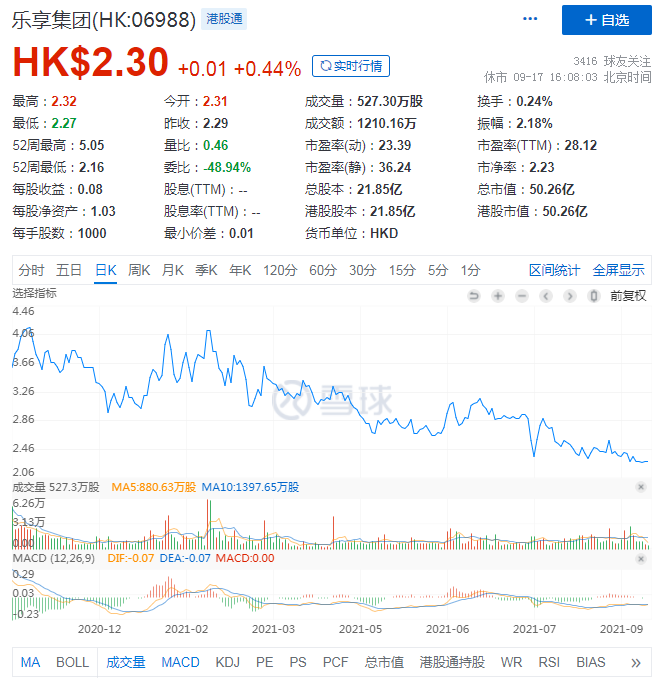
乐享集团上市近一年,效果营销的“功与过”
当下,步入新消费时代,移动新媒体效果营销风头正劲。
赛道不断涌出一批批前行者,诸如乐享集团、云想科技等。
回看过去,乐享集团、云想科技均在2020年登陆港股市场,这也带动了短视频效果营销的潜力释放。
随着时间的…

TDengine 在酷哞哞的应用
小 T 导读:酷哞哞与 TDengine 结缘于 2019 年,在其工业互联网设备上云解决方案中,选择了 TDengine 作为数据平台,以满足海量工业数据存储和分析的需求。本篇文章解读了 TDengine 在此方案中的具体应用。 互联网和传统工业的融合将…
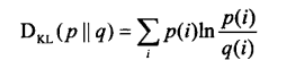
《推荐系统实践》 第三章 推荐系统冷启动问题 读书笔记
如何在没有大量用户数据的情况设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题
冷启动问题简介
用户冷启动 用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据…

TDengine助力京东云IoT数据统计改造
作者:何佳瑞 小T导读:在万物互联的时代,大到企业数字化转型、数字城市建设,小到和生活息息相关的家居生活、智能驾驶、运动健康等,都离不开智能物理设备广泛的连接和互通。AIoT是人工智能和IoT技术的融合,通…

回顾 2021,展望 2022 | TDengine 一年“成绩”汇总
导语:2021 年是全球进入后疫情时代的第二年,各行各业都依然处在疫情所带来的阴霾中,因为病毒的不断肆虐,企业的业务拓展处处受阻,各种行业交流峰会也举步维艰。但只要我们以乐观的心态来应对未来不确定的挑战ÿ…

直播整理 | TDengine 技术分享:兼容 OpenTSDB
整理 | 尔悦
嘉宾 | 廖浩均 小 T 导读:近年来,随着各种新兴技术的发展,物联网、工业互联网等行业获得了快速发展,由此产生的时序数据量也越来越庞大,通用大数据方案越来越难以为继,各种时序数据库产品应运…
Hadoop各配置文件详解
1、Hadoop各目录说明
文件夹名称作用bin存放对hadoop相关服务(HDFS,YARN)进行操作的脚本sbin存放启动或停止hadoop相关服务的脚本etchadoop的配置文件目录,存放hadoop的配置文件lib存放hadoop的本地库(对数据进行压缩解压缩功能&…
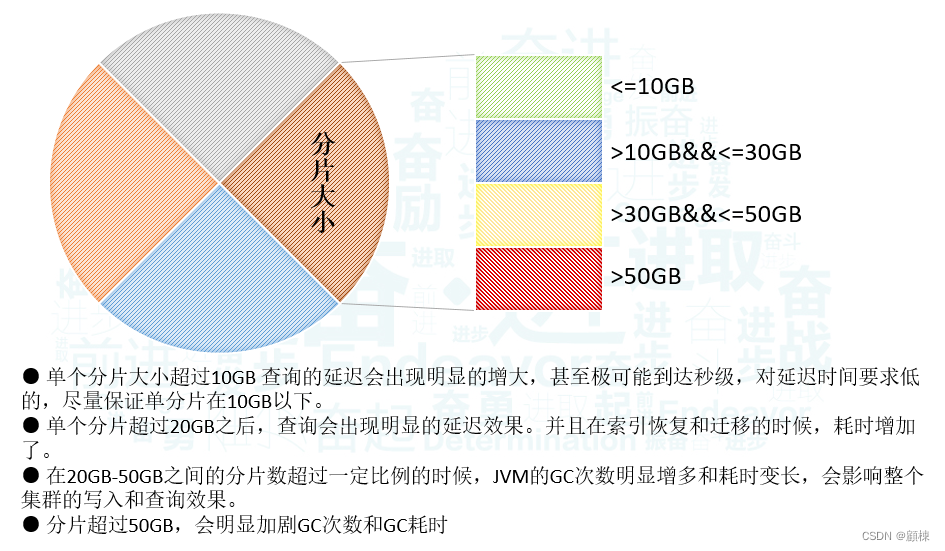
【ES实战】索引大分片治理
文章目录大分片治理思路大分片的危害如何处理大分片寻找大分片分析大分片的索引处理方式的具体实现索引主分片数的计算分片存储大小建议大分片治理思路
大分片的危害
过度占用服务器资源,降低集群服务能力加剧JVM的GC,导致查询,写入变慢在进…
【ES实战】索引模板template使用说明
文章目录索引模板模板的管理创建&修改模板多模板应用查询模板删除模板版本化模板索引模板
模板的主要作用:可以帮助简化创建索引的语句,将模板中的配置和映射应用到创建的索引中。
新建索引时,索引名称满足index_patterns条件的&#x…
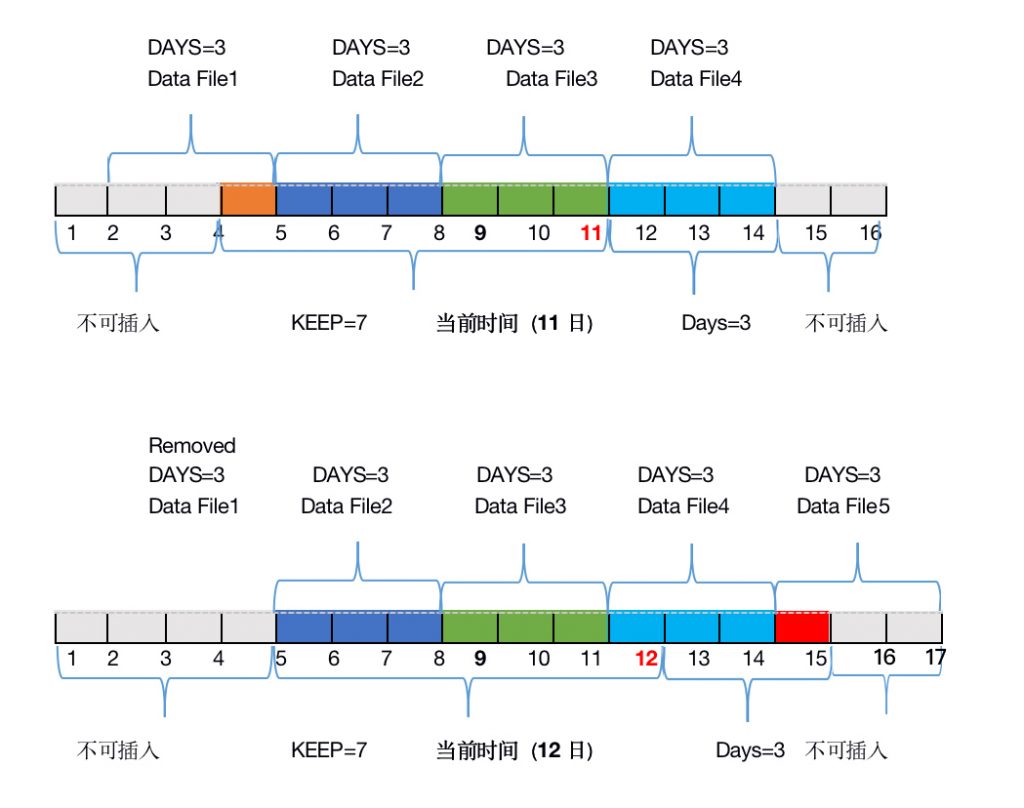
五分钟掌握TDengine时序数据的保留策略
小 T 导读:在《这几个神秘参数,教你TDengine集群的正确使用方式》这篇文章中,我们讲到了如何利用合理的配置vnode完成TDengine的数据分片,本期我们来继续讲讲TDengine如何从时间维度去对数据进行管理。 首先,先看看官网…

Hadoop(一):初始Hadoop
Linux安装hadoop:
参考:【Linux】安装hadoop详细步骤_Code.Knight的博客-CSDN博客_linux安装hadoop
这里要注意的是,修改主机名要慎重,可以不修改。 解决报错
启动 hdfs 会报错:temporary failure in name resoluti…
国际数据保护日,数据安全谁来守护?
“福气到,过新年,重要的事情说三遍,防骗防骗防诈骗。”为了提高大家在春节期间防骗意识,今年国家反诈中心首次登上五福福卡,中国铁路局也在列车上开设了“反诈列车”主题车厢。为什么我们会经常容易接到一些推销电话或…

普通大专生毕业在线自学Java,已经到手12K+的工作(经验+资料共享)
我是一名普通的不能在普通的大专学生,大学学的是室内设计,毕业后在一所小城市浑浑噩噩的干啦2年工资不到4k,并且在这里看不到任何提升的前景。装饰公司的图纸改的一遍又一遍,同时自己跨行的想法增长的一点又一点~~。 本人平常作图…
大专生学Java的心历路程,时经7个月,现已经成功上岸!
我的一个朋友的亲身经历,接下来,我讲用第一人称来讲述这个经历,是一名大专生,自认为不属于没有学习能力的那一个群体,高中成绩也曾是班级前三,高考双语都有一百多分,性格是能静下心来看书的那种…
scp、rsync与集群分发
1、scp(secure copy)安全拷贝
定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
基本语法
scp -r $pdir/$fname $user$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 …

基于Flink实时数仓——DWS 层与 DWM 层的设计(3.1)
设计思路 在之前通过分流等手段,把数据分拆成了独立的 Kafka Topic。那么接下来如何处 理数据,就要思考一下到底要通过实时计算出哪些指标项。 因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况 考虑…
离线计算与实时计算的比较、Presto与Kylin区别、实时需求种类
离线计算:就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是 Hadoop 的 MapReduce 方式&#x…

普通实时计算与实时数仓比较
离线数仓中为什么要分层?
普通实时计算与实时数仓比较
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此 做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时 需求…

spark实现倒排索引
1.需求:读取文件夹下的文件列表,并实现文件索引和词频统计 2.思路
2.1 读取目录下的文件,并生成列表
2.2 遍历文件,并读取文件类容成成Rdd,结构为(文件名,单词)并将多个Rdd拼接成1…

美的携手极视角创建数字化实验室,打造“AI+智慧园区”标杆示范点
为调整经济产业结构,集聚产业优势,我国大力发展的园区经济,形成了我国地域经济的增长极。园区的管理是全方位、多层次的管理。由于园区规模比较大,管理半径与管理纵深相应变大,面临着非常多的挑战:从项目、…

基于数据库Binlog记录操作日志-实践篇
前言
本篇要实现的功能 1.1 cannal监听指定的表 1.2 切面写入操作信息,通过traceId进行关联 1.3 MQ消费消息,将diff日志记录到指定的traceId记录中
Cannal的过滤(只监听指定的表)
简单介绍Cannal启动流程 如果启动模式为spring(mode或者globalConfig.…

基于数据库Binlog记录操作日志-摸索篇
前言
本文章主要参考《我们已经不用AOP做操作日志了!》
架构设计 业务应用生成每次操作的traceid,并更新到操作的业务表中,发送1条业务消息,包含当前操作人相关的信息 1.1 因为binlog的数据反映真实数据变动,脱离业务…

极视角与统信、海光、兆芯完成产品兼容互认证
近日,极视角旗下算法推理平台「极星平台V6.3」、AI私有化平台「极栈平台V2.1」与统信服务器操作系统V20、海光5000/7000系列处理器、兆芯KH-30000/KH-20000/ZX-C系列处理器完成了产品兼容互认证。
极星平台
极星平台是面向客户的算法推理平台,集算法配…

极视角与山东港口科技集团青岛有限公司共建「AI 赋能智慧港口联合实验室」
2月22日,极视角与山东港口科技集团青岛有限公司在极视角青岛展厅签订了战略合作协议,未来将共建「AI赋能智慧港口联合实验室」。 △ 山东港口科技集团青岛有限公司总经理张子青(左)、极视角副总裁何庆(右) …
人类最基本的思维方式有哪些?
人类最基本的思维方式有哪些?
ID:AcmeCore单爆营
人类最底层的思维仅包括四种:收敛思维、发散思维、水平思维和系统思维。
1、什么是收敛思维
收敛思维也叫做“聚合思维”、“求同思维”、“辐集思维”或“集中思维”,是…

加速推动科技创新,高校云数智融合实验平台兴起
“一直以来,将教学、科研以及咨询等工作做到更高质量且更有价值,都是我们持续追求的,过程中有成绩也有不少困惑,例如产学研用如何高效联动、科技转化怎样加速落地,确实长期困扰我们。”郑州大学电气工程学院某研究院大…

市委书记王伟中会见“深圳青年五四奖章”获奖代表,极视角CEO陈振杰在列
【导读】五四青年节来临之际,在深圳粤港澳大湾区建设和中国特色社会主义先行示范区建设中作出突出贡献的80名优秀青年和40个优秀集体,获评首届“深圳青年五四奖章”,深圳极视角科技有限公司CEO陈振杰在列。
4月23日,市委书记王伟…
docker中创建mysql容器,远程数据库
文章目录1.拉取合适版本的镜像2.启动docker,配置数据卷3.运行mysql1.拉取合适版本的镜像
[rootVM-0-17-centos ~]# docker pull mysql:5.7.31
5.7.31: Pulling from library/mysql
bf5952930446: Already exists
8254623a9871: Pull complete
938e3e06dac4: Pull…
什么是集群?看完这篇你就知道了
什么是集群?集群有哪些分类?集群的实现方式有哪些?什么是正向代理、反向代理、透明代理?
什么叫集群?
多台主机提供相同的服务的一组序列就叫集群 简单地说,集群就是指一组(若干个)…
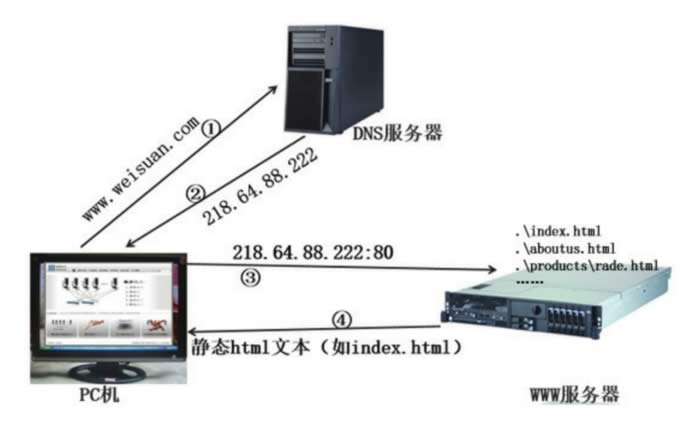
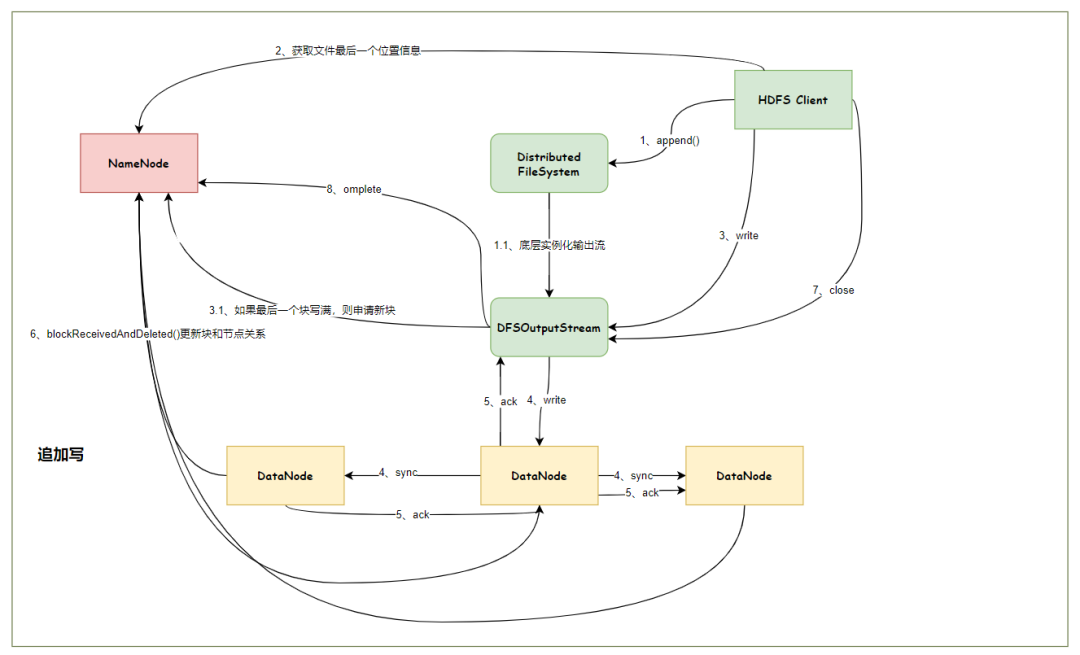
Hadoop三部曲搞起~
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料(密码每周更新一次)
入门大数据,通常先从Hadoop学习。通过本文可以学习到以下几点: Hadoop基本特性 HDFS读流程 HDFS写流程 HDFS追加流程 HDFS数…
Hive(HQL)数据库的安装及配置
点击可查看Hive中MySQL数据库的安装及绑定
Hive的特点
Hive与SQL语句相像能将SQL语句转变成MapReduce任务来执行Hive要依赖于yarn只能用于结构化Hive只能处理离线数据,处理大型数据
Hive在集群上的操作
1.Hive安装及配置
(1)点击XShell&…

旧貌换新颜,捷径系统助力老旧小区向智能化迈进
智能手机、智能穿戴、智能家居,社会变得越来越智能化,这已经成为不争的事实。
大数据无孔不入,从淘宝到抖音,从京东到快手,无处不是智能的身影,而人们也从开始的排斥、好奇、不解到逐步接收、应用、习惯&a…

业主委员会如何成立?让捷径智慧物业改变美好生活
天下苦物业久亦!
你看全网,一篇篇、一个个苦不堪言的文章和视频,如何改变我们的生活环境?
首先,我们业主需要驱动让物业使用诸如捷径智慧物业管理系统的综合型管理软件,双重超级管理员是业主委员会和物业…

为什么越来越多的物业服务被曝光-捷径智慧物业
打开各类小视频、新闻网站,近年来小区业主与物业的矛盾,不断被曝光。在文章和视频的评论里,大家的几乎是同仇敌忾,每个人都在声讨物业,声讨物业服务。
为什么大家都有这样的共鸣呢?
毕竟,房子…

Flink001---offset设置窗口起点
Intro
滚动窗口,想要设置窗口开始的时点,怎么弄。举例说明:
watermart设置为3s滚动窗口长度设置为5s起点设置为3,即[3,8)是一个窗口
Code
代码没啥说的,就是个offset的使用
import org.apache.flink.api.common.f…
Spark003-基础概念
Intro
spark一些基本概念,主要参考尚硅谷-Spark教程从入门到精通,美团《Spark性能优化指南——基础篇》。
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。 Driver 在 Spark 作业执行时主…

极视角联合英伟达亮相CNCC大会,分享极星平台的进阶之路
12月16日-18日,以“计算赋能加速数字化转型”为主题的第十八届中国计算机大会(CNCC2021)在深圳成功举办。在为期三天的大会中,超过600位国内外计算机领域知名专家、企业家到会演讲,大会设17个特邀报告、3场大会论坛、1…

极案例|守护农作物免受177种病虫害骚扰,极视角智慧农业系列算法大有可为
导读:我国是一个农业大国,据有关数据显示,目前我国智慧农业应用渗透率还不到1%,初步估算2020年我国智慧农业行业的市场规模约为622亿元左右,未来我国智慧农业发展将持续可期。
农业信息化、智慧化、精细化是农业发展必…

Hadoop_MapReduce_Partition分区案例实操
目录 1.需求
2.需求分析
3.代码
(1)在之前的序列化案例实操的基础上,增加一个分区类
(2) 在driver类中增加自定义数据分区设置和ReduceTask设置 1.需求
将统计结果按照手机归属地不同省份输出到不同文件中&#x…
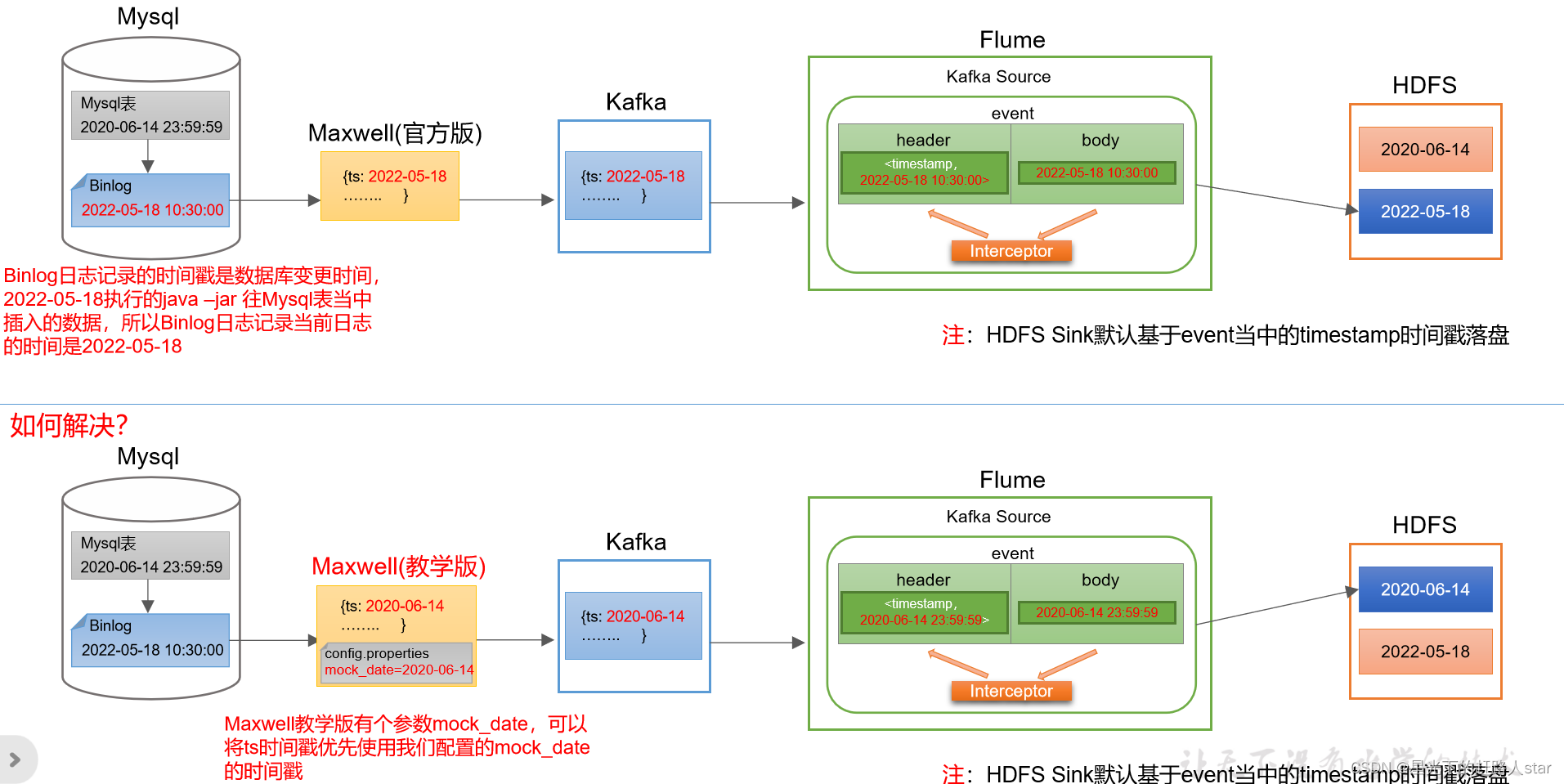
4、离线数仓数据同步策略(全量表数据同步、增量表数据同步、首日同步、采集通道脚本)
1、离线数仓同步数据
1.1 用户行为数据同步
1.1.1 数据通道
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
1.1.2 日志消费Flume配置概述
按照规划&…

极案例|119全国消防安全日,极视角智慧消防系列算法将火灾意外“拒之门外”
众所周知,“119”是我国的火警电话号码,为了增加全民的消防安全意识,使“119”更加深入人心,自1992年起,公安部将每年的11月9日定为“全国消防安全日”。
纵然如此,每年燃气爆炸、工厂失火、森林大火等事故…

「凤凰网专访」极视角何庆:点亮繁星 赋能百业
文章来源:凤凰网广东
2021年5月20日,第二届深圳国际人工智能展开幕式暨智能制造创新高峰论坛在深圳会展中心福田盛大启幕。
作为全国首个覆盖人工智能全产业链的专业展会,展会共设置人工智能硬件终端展示区、人工智能核心技术展示区、人工智…

青岛市第六批赴深圳体悟实训干部 “入职”极视角科技
2021年5月10日,在青岛市市北区委常委、组织部部长张雷一行的陪同下,青岛市第六批赴深圳体悟实训队干部——青岛市委政研室政治研究处处长韩超臻到极视角科技报到,并举行“青岛干部实训基地”授牌仪式。作为“青岛市第六批赴深圳体悟实训队”项…

逐浪CMS后台简单高效的操作数据库一键备份
作为网站运营维护人员,保障网站数据的安全及数据的备份是首要任务,但很多网站 后台是不支持数据的备案,且不能在后台做到自由管理。
在逐浪cms后台,完全开放可数据的备案、还原等操作,给维护人员提供了超级便捷的操作…

数据库练习-Magedu 11周
1、 导入hellodb.sql生成数据库
mysql -uroot -p123456 <hellodb_MyISAM.sql(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄
select * from students where age>25 and gender"M";(2) 以ClassID为分组依据ÿ…

Redis单机数据库的实现1
前言
Redis系列博客为对黄健宏老师《Redis设计与实现》一书内容的整理 第9章 数据库
服务器中的数据库
Redis服务器通过db数组来保存redis数据库
默认情况下,Redis客户端的目标数据库为0号数据库,但客户端可以通过执行select命令来切换目标数据库
s…
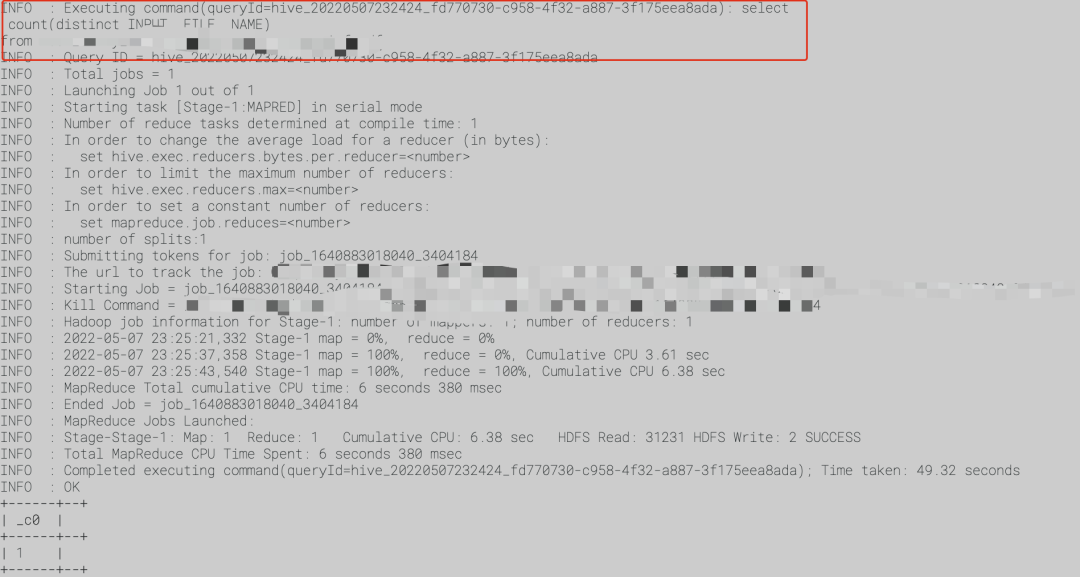
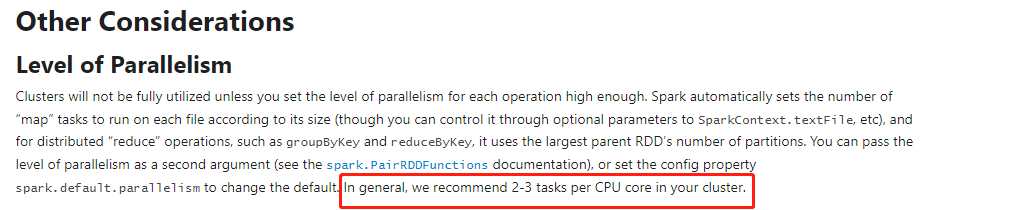
Spark作业不知道该如何分配资源怎么办?
前几天有好几个朋友问我关于spark作业分配资源的问题:即在提交作业的时候,不知道该分配多少资源比较好?我的回答是靠经验,仔细想想靠经验这等于不是没说吗,总有一些方法论或者思路的吧。所以就有了这篇文章,…
Hive专题-数据修复篇
相信使用过Hive的同学,一定会知道msck repair的用途(元数据修复)。那么不知道大家有没有好奇过Hive底层是怎么实现该机制的呢?这里带大家简单了解一下。
一、基本解释
在HMS(Hive MetaStore)中存储着每个表的分区列表࿰…
![[Kubernetes]如何通过服务名发现服务? kube-proxy 和 kube-dns 原理解密](https://img-blog.csdnimg.cn/2021082913044878.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAcWluZ2RhbzY2NjY2Ng==,size_20,color_FFFFFF,t_70,g_se,x_16)
[Kubernetes]如何通过服务名发现服务? kube-proxy 和 kube-dns 原理解密
前言
在这里,你将了解 Kubernetes 集群如何实现通过服务名,进行服务发现,负载均衡,调用后端服务。 这里,我们以服务名为ticknet为例,假设我们要访问内部服务ticknet的某个http接口,则ÿ…
hutool 日期时间工具-DateUtil
Testpublic void test1(){//当前时间Date date DateUtil.date();//当前时间Date date2 DateUtil.date(Calendar.getInstance());//当前时间Date date3 DateUtil.date(System.currentTimeMillis());//当前时间字符串,格式:yyyy-MM-dd HH:mm:ssString…

新形势下的捷径智慧物业管理
“老王,把置物架上的快递整理一下。快放不下了。”
“老张,把置物架上的超市配送整理一下,这样放起来很乱,不利益防疫安全。”
“老李,……”
…………
以前,每天都在做的事情,每天都漠然在…

捷径智慧物业系统,引导商业物业互联网思维升级改造
近年来,经济的快速发展,让我国商业现代化水平急速提高。
北上广这些大城市的商业物业陆续涌入。导致商业物业竞争剧烈。
商业物业管理的合理化要求也越来越高,市场竞争要求商业物业从布局、规模、功能、档次等方面都更加合理,更…

云计算技术:存储技术
存储技术演进路线
ICT产业从60年代以主机、终端为核心的第一平台到80年代以个人电脑、客户端/服务器和局域网/互联网为依托的第二平台,直至今天演进到了以云计算、大数据、移动、社交媒体为依托的第三平台。第三平台被IDC称为ICT的未来,整个IT行业向第三…

【Flink学习】入门教程之Streaming Analytics
文章目录流式分析概要使用 Event TimeWatermarks延迟 VS 正确性延迟使用 WatermarksWindows概要窗口分配器窗口应用函数ProcessWindowFunction 示例增量聚合示例晚到的事件深入了解窗口操作滑动窗口是通过复制来实现的时间窗口会和时间对齐window 后面可以接 window空的时间窗口…
【ES源码分析】Transport模块的初始化
文章目录Transport模块的初始化ActionModule的初始化NetworkModule的初始化NetworkPluginNetty4TransportNetty4HttpServerTransportTransportService的初始化Transport模块的初始化 源码基于6.7.2 传输模块的初始化主要的在节点启动时的构造函数中完成的。
节点启动时&#x…

看得懂的猪周期,牧原们却不一定跨得过
2022年2月16日,全国各省三元猪均价为12.34元/公斤,较昨日下跌0.13元/公斤,较上周同期猪价(2月9日)下跌1.20元/公斤。
在供需关系的支配下,猪肉价格上涨,散户蜂拥而上,猪肉供给大增,肉价下跌&am…
【ES实战】如何进行集群规划
文章目录集群规划系统层1. 操作系统2. 内存、CPU、磁盘3. JDK4. 操作系统参数5. 生产模式启动强制校验项6. 配置Linux OOM Killer7. TCP参数修改8. vm相关9. 禁用透明大页(Transparent Hugepages)集群层1. 影响因素2. 部署架构节点层索引层其他客户端读写…
【ES实战】reindex API的使用
Reindex API的使用
可以用来处理大分片和数据迁移,以及索引规整 文章目录Reindex API的使用使用前提主要功能使用举例本集群复制将源索引的部分字段进行复制到目标索引使用脚本脚本修改文档和文档元数据重新路由目标索引文档跨集群复制索引修改目标字段名称分片手动…

Spark 独立部署模式
Spark Standalone Mode http://spark.apache.org/docs/latest/spark-standalone.html 文章目录Spark Standalone ModeSecurityInstalling Spark Standalone to a ClusterStarting a Cluster ManuallyCluster Launch ScriptsResource Allocation and Configuration OverviewConn…
Spark 提交应用
文章目录Submitting ApplicationsBundling Your Application’s DependenciesLaunching Applications with spark-submitMaster URLsLoading Configuration from a FileAdvanced Dependency ManagementMore InformationSubmitting Applications http://spark.apache.org/docs/l…

基于Flink实时数仓——维表关联代码实现(4.2优化:异步查询)
在 Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。 例如:
在电商场景中,需要一个商品的 skuid去关联商品的一些属性,例如商品所属行业、 商品的生产厂家、生产厂家的一些情况ÿ…
MapReduce 基础之:图文讲解 MapReduce 工作原理
图文讲解 MapReduce 工作原理理解什么是map,什么是reduce,为什么叫mapreducemapreduc工作流程分片、格式化数据源执行 MapTask执行 Shuffle 过程执行 ReduceTask写入文件整体流程图MapTaskReduceTask理解什么是map,什么是reduce,为…
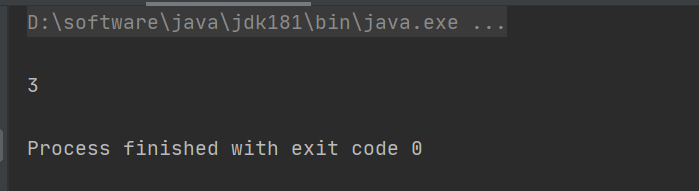
HadoopRPC调用案例
目录 1.需求:
2.基本思路
2.1 首先需用定义一个协议,它描述了服务对外提供了哪些接口或者功能--MyProtocol.java
2.2 Server端需要实现协议接口,并返回版本号,实现返回学院名称的函数--MyImp.java
2.3 构建Server,…

Mapreduce案例之---统计手机号耗费的总上行流量、下行流量、总流量
1.需求:
统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备:
2.1 输入数据格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码 2.2 最终输出的数据格式&…

大数据--spark生态7--spark的shuffle过程详解
目录
一: 理解shuffle
二: shuffle write
2.1 shuffle write的目标
2.2 shuffle write的位置
2.3 桶(bucket)
2.4 默认分区算法
2.5 bucket数量太多的解决方案
三: shuffle read
3.1 在什么时候fetch
3.2 边…
大数据--spark生态4--sparkSQL
目录
一:sparkSQL介绍
二:DataFrame
三:dataSet
四:rdd,dataframe,dataset之间的转换
五:rdd,dataframe,dataset异同点
5.1 相同点
5.2 区别
六:DataFrame的常用操作 一:sparkSQL介绍
…
hive调优最全总结
目录 第八章 数据调优及其原理11/15
8.1 小问题问题
8.1.1 小文件的危害
8.1.2 小文件的产生原理
8.1.3 小文件的治理方案
8.2 数据倾斜问题
8.3 减少数据量
8.4 参数优化
8.5 企业级调优 第八章 数据调优及其原理11/15
8.1 小问题问题 小文件过多会占用大量内存&…

数据倾斜产生,原因及其解决方案
目录 第七章 数据倾斜
7.1 数据倾斜的产生,表现与原因
7.1.1 数据倾斜的定义
7.1.2 数据倾斜的危害
7.1.3 数据倾斜发生的现象
7.2 数据倾斜倾斜造成的原因
7.3 几种常见的数据倾斜及其解决方案
7.3.1 空值引发的数据倾斜
7.3.2 不同数据类型引发的数据倾斜…

大数据--spark生态3--RDD介绍及其算子
目录
一:RDD创建
1.1从文件系统中加载数据创建RDD
1.2通过并行集合(数组)创建RDD
二:RDD操作
2.1转换操作
2.2行动操作
2.3 惰性机制
2.4 持久化
三:rdd转换算子
3.1 value类型
3.2 key-value类型
四&…
Elasticsearch优化的一些建议
1. 增大系统打开文件数
调大系统的“最大打开文件数” ,建议32K甚至是64K
ulimit -a(查看)
ulimit -n 32000(设置)2. 合理设置JVM内存
修改配置文件调整ES的JVM内存大小。
修改jvm.options中-Xms和-Xmx的大小,建议…
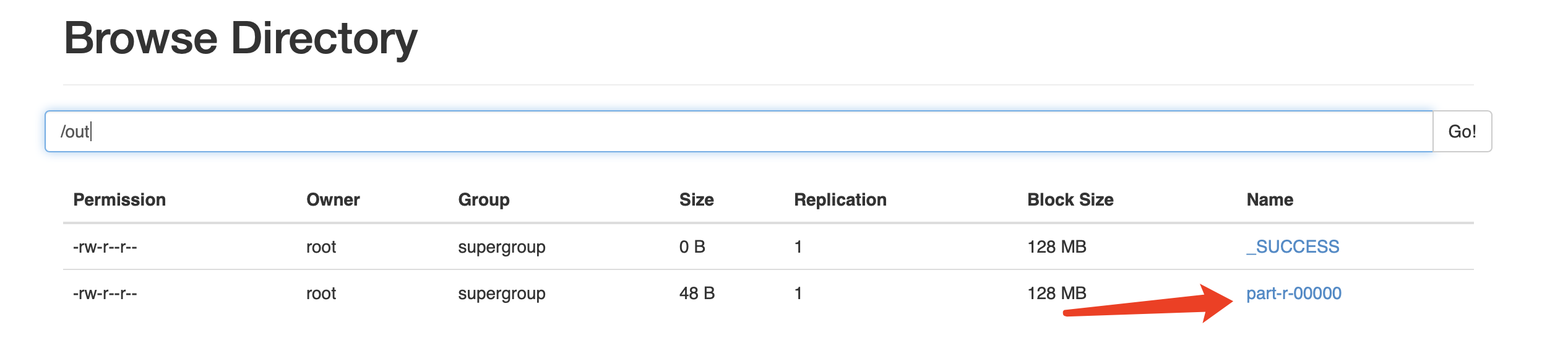
【每天五分钟大数据-第一期】 伪分布式+Hadoopstreaming
说在前面
之前一段时间想着把 LeetCode 每个专题完结之后,就开始着手大数据和算法的内容。
想来想去,还是应该穿插着一起做起来。
毕竟,如果只写一类的话,如果遇到其他方面,一定会遗漏一些重要的点。
LeetCode 专题…

快速阅读《PostgreSQL数据库内核分析》
第一章 PostgreSQL 系统概述
简单描述PostgreSQL的来源、特性和应用。 要用的话,可以看看数据库的具体命令。
第二章 PostgreSQL的体系结构
五大部分组成: 1、连接管理系统(对操作请求进行处理和分发) 2、编译执行系统…
大数据--spark生态5--sparkStreaming
目录
一:流数据特征
二:流数据的数据价值
三:流计算系统的标准
四:流处理系统与传统的数据处理系统区别
五:数据处理分类
六:streaming的特点
七:DStream转换
八:Flink优势 …
zk java api
1.pom 文件 <dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.4.8</version></dependency><dependency><groupId>org.apache.curator</groupId><arti…

大数据--mysql3--sql必知必会(第五版)之mysql的检索过滤数据
本篇博客是对《SQL必知必会》第五版书籍的总结
对于文章的出现的表名称,列名请参考书籍《SQL必知必会》及上一篇博客
sql必知必会(第五版)学习总结(一)--mysql预备知识汇总
目录
1:检索数据
1.1检索某…
Python 和 R 营销数据分析
特点
学习实施数据科学技术,以了解营销活动成功和失败背后的驱动因素了解和预测客户行为,并制定更有针对性的个性化营销策略。执行从简单到高级的任务,从数据中提取隐藏的见解并使用它们做出明智的业务决策了解是什么推动了销售并增加了产品…
Hadoop的安全问题
认证
kerberos:Kerberos 是一个网络身份验证协议,用户只需输入身份验证信息,验证通过获取票据即可访问多个接入 Kerberos 的服务,机器的单点登录也可以基于此协议完成。
用户执行任务前,先通过KDC认证自己࿰…

数据库系统概论——关系模型(关系完整性约束)
文章目录关系的三类完整性约束实体完整性和参照完整性实体完整性(Entity lntegrity)参照完整性参照完整性(关系间的引用)外码(Foreign Key)参照完整性(参照完整性规则)用户定义的完整…
大数据与云计算是什么关系
运用人工智能、大数据、云计算等技术,青岛企业竞速两轮车换电"新赛道"两轮车换电,青岛企业竞速"新赛道"核蜂动力运用人工智能、大数据、云计算等技术打造换电新场景"两轮车换电"正成为一条日益火热的新赛道... 声明:转载此文是出于传递更多信息之…

hive优化大全(hive的优化这一篇就够了)
文章目录写在前面一、概述1.1 数据倾斜1.2 MapReduce二、产生原因三、解决方案和避免方案3.1 Hive语句初始化配置3.1.1 join过程的配置3.1.2 map join过程的设置3.1.3 combiner过程3.1.4 group by 过程3.1.5 map 或者reduce 过程3.1.6 mapper 设置3.1.7 reducer设置3.1.8 存储与…

Kafka基础(一)
接下篇 消息系统:
1、消息系统的应用场景
1.1、应用解耦 将一个大型的任务系统分成若干个小模块,将所有的消息进行统一的管理和存储,因此为了解耦,就会涉及到kafka企业级消息平台
1.2、流量控制 秒杀活动当中,一般会…

本期探究:Flink是怎样支持批流一体的呢?
今天咱们来聊一聊Flink是怎样支持批流一体的呢?
实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等。这些都是处理有限数据流的经典方式。而Flink专注的是无限流处理&am…
Scala操作hudi
文章目录Scala操作hudi1、启动客户端2、配置信息3、 创建数据表4、插入数据5、查询数据6、更新数据7、增量查询8、时间点查询9、删除数据10、覆盖写入Scala操作hudi
1、启动客户端
//spark3.1
spark-shell \--packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.10.1,o…
Hadoop搭建配置信息
文章目录一、etc/hadoop/core-site.xml二、etc/hadoop/hdfs-site.xml1、NameNode的配置:2、DataNode的配置:三、etc/hadoop/yarn-site.xml1、ResourceManager 和 NodeManager 的配置:2、ResourceManager的配置:3、NodeManager 的配…
sqoop 整库导入数据
文章目录需求整库导入常用参数通用参数导入控制参数输出格式参数输入分析参数Hive参数代码生成参数需求
最近在迁移老数据的时候需要把mysql的整个库全部迁移到hive,由于mysql的表和库比较多,建表麻烦,所以只有祭出神器–sqoop的整库导入。 …
kafka配置参数简介
配置及参数说明
Broker 端参数
所谓静态参数,是指你必须在 Kafka 的配置文件 server.properties 中进行设置的参数,不管你是新增、修改还是删除。同时,你必须重启 Broker 进程才能令它们生效。而主题级别参数的设置则有所不同,K…

Hive 安装部署MySQL 安装Hive 元数据配置到 MySQL
目录
1.安装 Hive
2.启动并使用 Hive
3.MySQL 安装
4.Hive 元数据配置到 MySQL 1.安装 Hive 1)把 apache-hive-3.1.2-bin.tar.gz 上传到 linux 的/opt/software 目录下2)解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面[atguiguhadoop102…

hbase rowkey设计案例
介绍
hbase中的rowkey可以唯一定位一条数据。rowkey设计的合不合理,很大程度上可以解决数据倾斜的问题。
和rowkey密切相关的是分区键,我们可以用命令行或者代码方式创建分区键: 比如staff这个表就有4个分区键:
aaaa
bbbb
cccc…

rdd算子之map相关
首先是RDD算子中与map有关的几个算子的理解。 rdd算子之map相关mapmapPartitionsmapPartitionsWithIndexmap
map其实就是一种数据结构的映射,将一种结构转换成另一种结构。
一个简单的spark程序实现列表中的每个数乘以2:
object MapOperator {def mai…
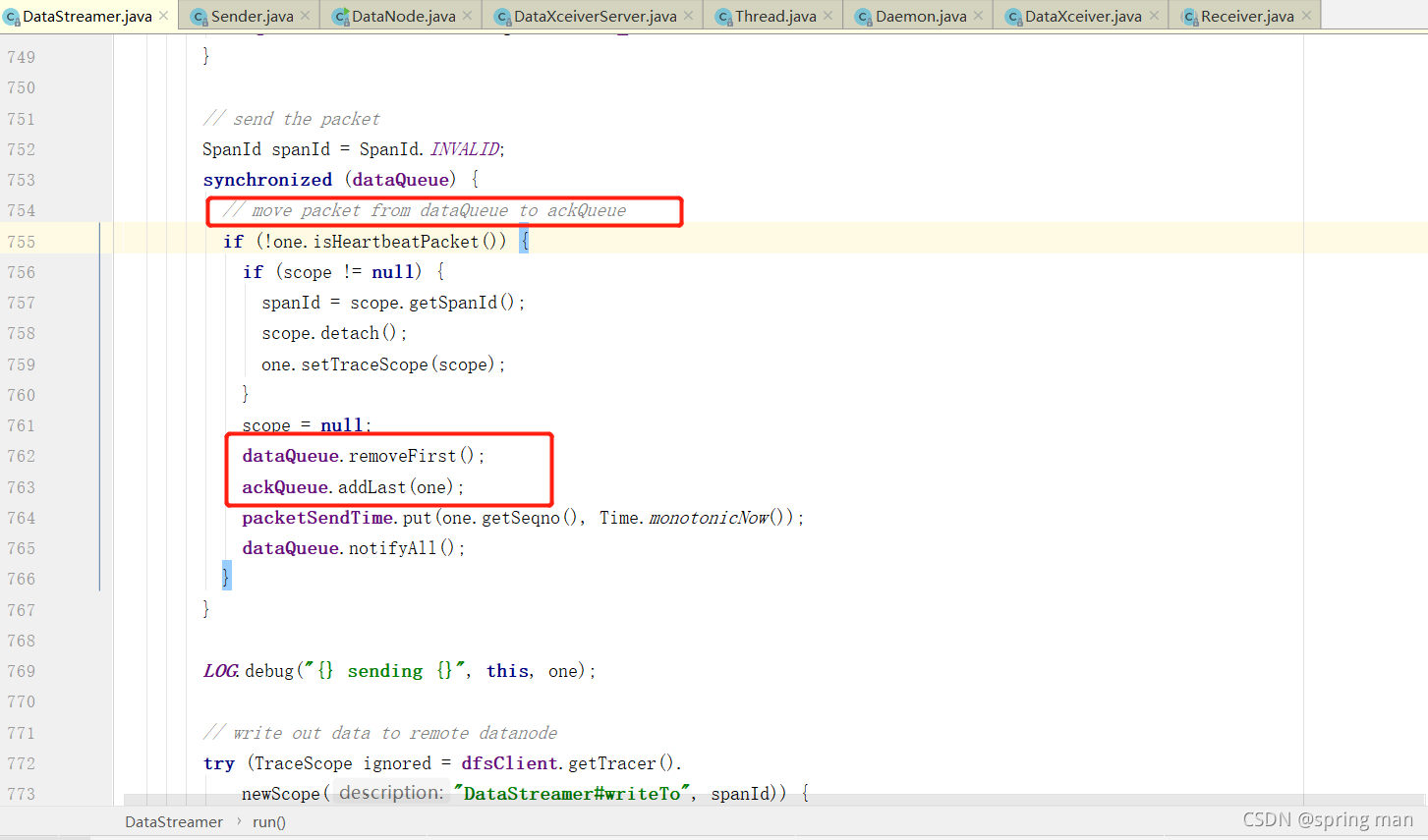
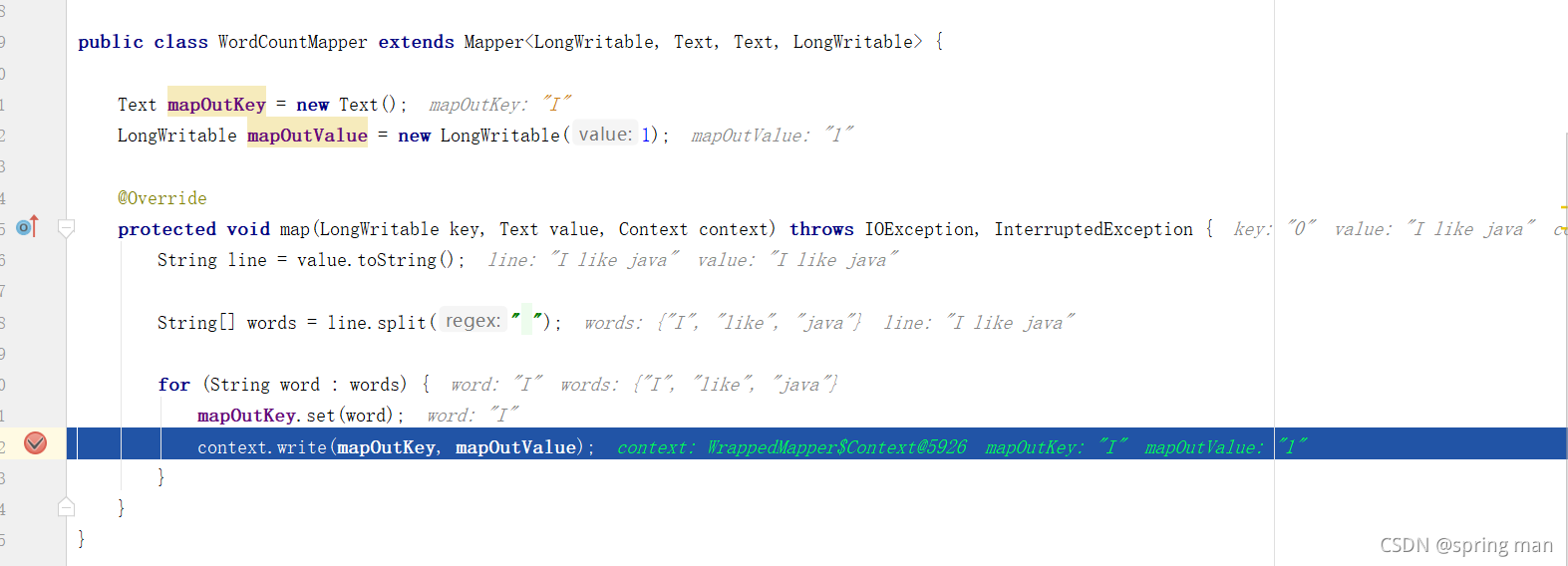
MapReduce之Map阶段
MapReduce阶段分为map,shuffle,reduce。
map进行数据的映射,就是数据结构的转换,shuffle是一种内存缓冲,同时对map后的数据分区、排序。reduce则是最后的聚合。
此文探讨map阶段的主要工作。 map的工作代码介绍split…

namenode的fsimage与edits文件
namenode的fsimage与edits文件引入合并查看引入
hadoop集群中,namenode管理了元数据。那么,元数据存储在哪里呢?
如果是磁盘中,必然效率过低,如果是内存中,又会不安全。
所以元数据存储在内存中…


JAVA中如何将以Date型的数据保存到数据库以Datetime型的字段中
用Timestamp就行了
recordOuttime是Date类型
import java.sql.Timestamp;
Record record recordMapper.selectByPrimaryKey(recordId);
Date recordIntime record.getRecordIntime();
Date dNow new Date();
Timestamp recordOuttime new Timestamp(dNow.getTime());
rec…
Spark3.1.2高可用部署
Spark3.1.2高可用部署文档 解压、改名
tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz -C /opt/
cd /opt/
mv spark-3.1.2-bin-hadoop2.7/ spark
cd spark/conf添加Hadoop配置文件的软链接
ln -s /opt/hadoop/etc/hadoop/core-site.xml
ln -s /opt/hadoop/etc/hadoop/hdfs-site.xm…
Polardb训练营-Polardb-X集群做动态扩缩容
本文将主要介绍如何在 Kubernetes 上,通过 PolarDB-X Operator 实现 PolarDB-X 数据库集群的弹性扩缩容。关于如何用 Kubernetes安装PolarDB-X,请您移步上一篇博客中获取:https://blog.51cto.com/yangjunfeng/5383036我们这里放一张…
百万数量级优化及MVCC硬核知识
本笔记通过看 B站IT老哥获得 文章目录MVCC什么是innodb的当前读和快照读?当前读:快照读mysql百万级别数据优化1、加索引 0.009ms2、最左前缀法则3、不要对索引做以下处理4、索引字段不要放在范围查找的右边5、减少select * 的使用 ,使用覆盖索…

Flink零基础学习(四)RunTime总览以及核心组件简单介绍
用户的任务会以job方式提交给集群,runtime负责整个作业的调度,支持各种作业方式。
简单的一个作业表单 实际上作业是: 这里就是逻辑图(JobVertex)和执行图(ExecutionVertex)的区别,虚线圈表示的是一个Operator chain(要求并发度一…
Polardb训练营-本地部署 PolarDB-X
PolarDB-X是阿里巴巴自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。云原生MySQL生态PolarDB-X已作为标准云产品在世界范围内的13个地区提供服务。依托云资源和容器化部署能力,Pol…
铁打的星巴克,流水的新饮品
400元自助餐事件,再次让星巴克登上头条。
初代小资三大圣地,哈根达斯、宜家、星巴克,都逐渐失去原有光芒。
哈根达斯已经彻底丧失原有地位,在新茶饮的进攻下不堪一击,与其曾经的高端定位已经渐行渐远。
星巴克营收、…

Spark基础之:常用算子逐一详解
Spark常用算子逐一详解一、什么是Spark rdd算子?二、算子的分类Transformation算子Action算子三、常用的Transformation算子及使用方法1.map算子2.flatMap算子3.mapValues算子4.filter算子5.foreach算子6.groupBy算子6.groupByKey算子7.sortBy算子8.glom算子9.parti…
Hive基础之:hive数据倾斜原因及解决方案
hive数据倾斜产生的原因
数据倾斜的原因很大部分是join倾斜和聚合倾斜两大类
一、Hive倾斜之group by聚合倾斜
原因: 分组的维度过少,每个维度的值过多,导致处理某值的reduce耗时很久; 对一些类型统计的时候某种类型的数据量特…

Hive基础之:图文详解hive分区、分桶
什么是分区、分桶
下面我用一组图和一个情景先简单的介绍一下什么是分区、分桶: 小黄人要去医院打疫苗,于是格鲁把它们分成了几组让他们去不同的医院,用来分散医院的压力。如图所示,格鲁根据身高把它们分成了三组。 来到医院后&a…

Hive基础之:Order By、Sort By、distribute by 、cluster by的区别
Order By
order by 排序出来的数据是全局有序的,在hive mr引擎中将会只有1个reduce
Sort By
sort by 排序出来的数据是局部有序的,但是全局无序。即partition内部是有序的,但是partition与partition之间的数据是没有顺序关系的
distrib…
Flink主要知识点联系和全面总结
目录
1.Flink集群有哪些角色?各自有什么作用?
2.Flink TaskManager的内存管理
3.Flink 资源管理中 Slot、Task 和SubTask的概念
电商大数据分析模块的设计和概念
一、架构选型 a. 数据量多少 b. 业务对统计结果反馈时间是否严格 时效性是否非常高 二、离线数据分析范围 适用于对统计过反馈时间不是那么严格的场景 eg:网站的运营数据指标 技术类型 a. 早期 主要编写hadoop的mapreduce b. 现在 感觉采用基于…

拼多多的智慧农业探索价值
出品 | 何玺 排版 | 叶媛
4月25日,第二届“多多农研科技大赛”落下帷幕,这场耗时8个月、汇聚全球各地精英科研团队和研究人员的比赛圆满结束,其所取得的成就不仅仅是百万奖金或是研究出如何提高番茄产量的方法,而是意味着科技赋能…
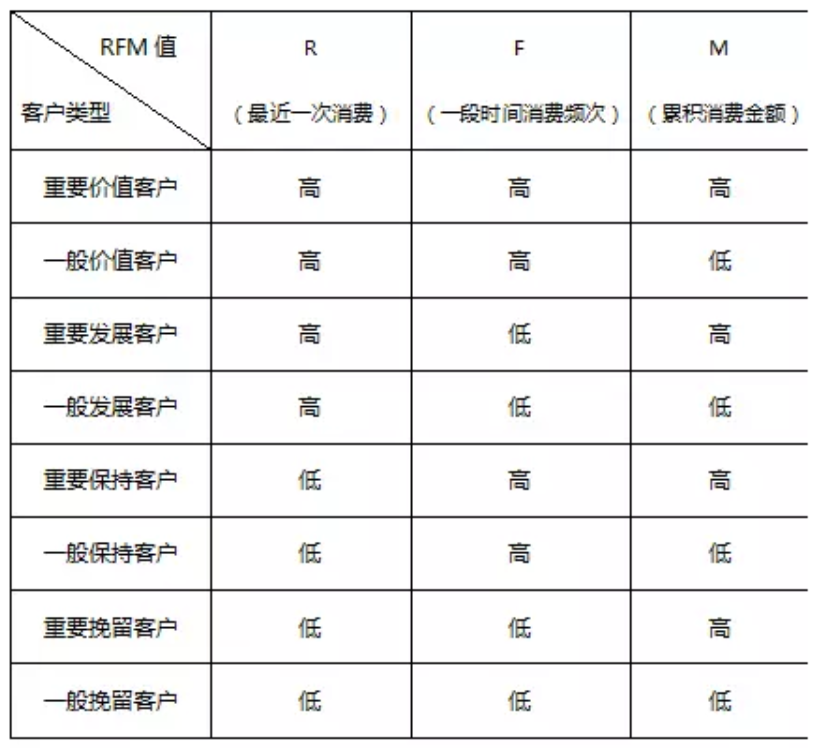
数据分析 一文搞懂什么是RFM模型
数据分析 | 一文搞懂什么是RFM模型
想知道你在电商平台心里的地位吗?学会RFM分析法,你自然知道
大家好,我是翔宇!今天我们来了解做数据分析一定要会的分析方法之一----RFM分析法。
相信大家在前天的双十一一定也多多少少贡献了…

数据分析入门 | kaggle泰坦尼克任务(四)—>数据清洗及特征处理
系列索引:数据分析入门 | kaggle泰坦尼克任务 文章目录一、数据清洗及特征处理(1)数据清洗简述(2)观察缺失值(3)缺失值处理(4)重复值的处理(5)特征…

Spark - RDD / ROW / sql.DataFrame 互转
一.引言 SparkSql 相比较 HiveSql 具有更快的运行速度和更高的灵活性,平常使用中经常需要进行数据转换,常见的有 RDD[T] -> DataFrame,DataFrame -> RDD[T] 还有 RDD[row] -> sql.dataFrame,下面简单介绍下常用用法。
初…

☀️☀️基于Spark、Hive等框架的集群式大数据分析流程详述
本文目录如下:基于Spark、Hive等框架的集群式大数据分析流程详述第1章 淘宝双11大数据分析—数据准备1.1 数据文件准备1.2 数据预处理1.3 启动集群环境1.4 导入数据到 Hive 中1.4.1 把目标文件上传到 HDFS 中1.4.2 将数据导入至 Hive 中第2章 淘宝双11大数据分析—H…

IBM提出改变城市未来的五大构想
在本次的 Web 2.0大会上,IBM新兴技术部总监 David Barnes就“如何才能拥有一个更智能的城市和智能的地球”发表了公司观点。IMB想建立一张网,这种网不是平常意义上的互联网,而是可以为政府,医疗机构,商人等提供大量“重要数据”的…

3.Spark 学习成果转化—机器学习—使用Spark MLlib的逻辑回归来预测音乐标签 (多元分类问题)
本文目录如下:第3例 使用Spark ML的逻辑回归来预测音乐标签3.1 数据准备3.1.1 数据集文件准备3.1.2 数据集字段解释3.2 使用 Spark MLlib 实现代码3.2.1 引入项目依赖3.2.2 将 MNIST 数据集以 libsvm 格式进行加载并解析3.2.3 准备训练和测试集3.2.4 运行训练算法来…

2.Spark 学习成果转化—机器学习—使用Spark ML的逻辑回归来预测乳腺癌 (二元分类问题)
本文目录如下:第2例 使用Spark ML的逻辑回归来预测乳腺癌2.1 数据准备2.1.1 数据集文件准备2.1.2 数据集字段解释(按列来划分)2.2 使用 Spark ML 实现代码2.2.1 引入项目依赖2.2.2 加载并解析数据2.2.3 为 ML pipeline 将 RDD 转换为 数据帧2.2.4 特征抽取与转换2.2…
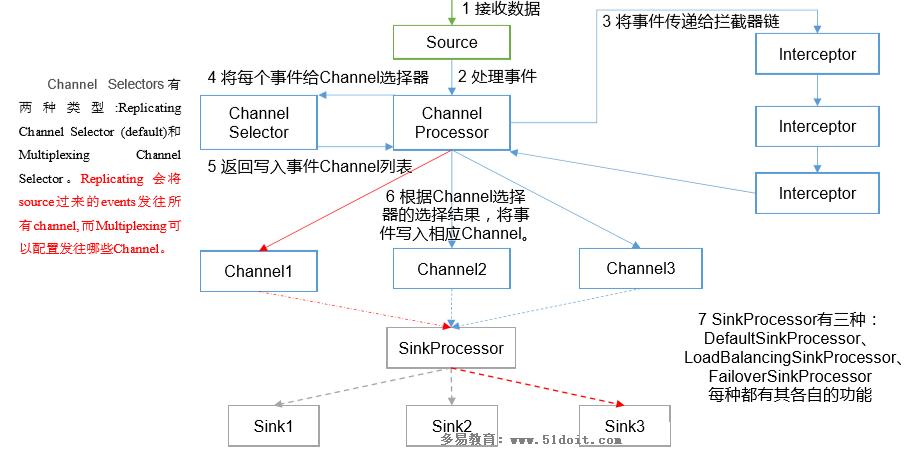
数据迁移工具之Flume
文章目录一、Flume1、Flume的架构1.Agent2.Source3. Sink4.Channel5. Event2、flume内部数据传输的封装形式3、 Transaction:事务控制机制4、 拦截器二、Flume安装1、启动命令三、Flume的端口数据监听1、切换目录并创建配置文件2、配置信息3、打开Flume监听窗口4、使…
数据迁移工具之DataX
文章目录一、DataX1、DataX框架2、DataX运行原理二、安装DataX1、DataX的下载安装地址2、编译三、配置模板1、从Stream流到控制台2、从MYSQL到HDFS3、从HDFS到MySQL一、DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、…
1.Spark 学习成果转化—德国人贷款情况分析—各职业人群贷款目的Top3
本文目录如下:第1例 德国贷款群体情况分析1.1 数据准备1.1.1 数据库表准备1.1.2 数据库表字段解释1.1.3 在 IDEA 中 创建数据库表 并 导入数据1.2 需求1:各职业人群贷款目的Top31.2.1 需求简介1.2.2 需求分析1.2.3 功能实现注: Spark 学习成果转化中系列…

1.Spark Streaming基础—Spark Streaming架构图、背压机制、WordCount 案例实操、WordCount 解析
本文目录如下:第1章 Spark Streaming概述1.1 Spark Streaming 是什么1.2 Spark Streaming架构1.2.1 架构图1.2.2 背压机制第2章 Dstream 入门2.1 WordCount 案例实操2.1.1 添加依赖2.1.2 编写代码2.1.3 启动程序并通过 netcat 发送数据2.2 WordCount 解析第1章 Spar…
利用shell实现hadoop3.1.3单机集群的搭建
文章目录利用shell实现hadoop单机集群的搭建1、材料准备2、自动化安装脚本利用shell实现hadoop单机集群的搭建
1、材料准备
一个联网的liunx虚拟机yum环境配置完毕(关于yum环境搭建,请查看本人文章利用自动化脚本实现Linux的yum仓库本地镜像和远程华为…
hadoop的HDFS的shell命令大全(一篇文章就够了)
文章目录HDFS的shell命令1、安全模式1.查看安全模式状态2.手工开启安全模式状态3.手工关闭安全模式状态2、文件操作指令1.查看文件目录2.查看文件夹情况3.文件操作4.上传文件5、获取文件6.查看文件内容7.创建目录8.修改副本数量9.创建空白文件(不推荐使用࿰…
Hadoop服务开启与关闭及其源码介绍
文章目录Hadoop的服务开启与关闭1、开启关闭所有服务(不推荐)1.命令使用2.start-all.sh脚本3.stop-all.sh2、开启Hadoop所有服务★★★1.命令使用2.start-dfs.sh3.start-yarn.sh3、关闭Hadoop所有服务★★★1. 命令使用2.stop-dfs.sh3.stop-yarn.sh4、利…

实在智能签约中国集成灶领航者亿田,共赴智能制造新时代
民以食为天,食以安为先。近日,实在智能签约中国集成灶领航者浙江亿田智能厨电股份有限公司(股票简称:亿田智能,股票代码:300911),助力企业提质降本增效,共赴智能制造新时…

实在智能收获机器之心权威认证,展现头部RPA厂商强劲实力
摘要:实在智能在机器之心发布的《中国市场 RPA 产品 AI 技术融合情况测试报告》中,多个单项及综合得分排名第一。
近日,国内领先的前沿科技媒体和产业服务平台机器之心,联合多名业内资深技术专家共同完成业内 RPA 产品的首次深度…


荣耀magic 3系列冲击高端胜算几何?
荣耀向高度市场发起冲击。
8月20日,荣耀CEO赵明在Magic3系列迎首销日在社交媒体发文称:荣耀Magic3系列全渠道首销,这是我们全能科技实力无缝对接消费者体验的开篇,也是荣耀高端旗舰的揭幕。
01
火爆的magic 3系列“全能旗舰” …
failed to register layer: open xxx no such file or directory
今天遇到一个镜像下载失败的问题,如下
failed to register layer: open /ssd/docker/overlay2/8b59377a7b63cd2014d31a3a885353c107f2aad1fb07886c92e1aa35732b3d21/committed: no such file or directory搜索网上的解决办法,比如
docker system prune…
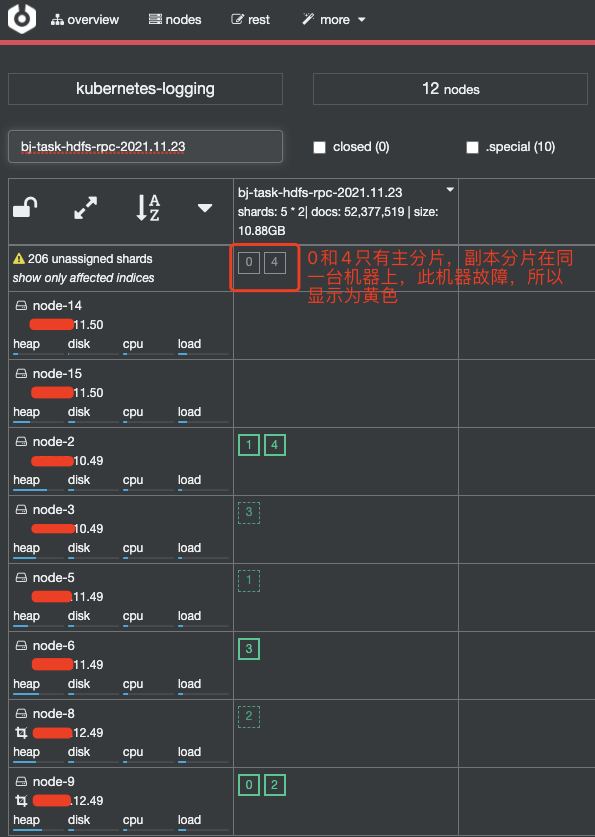
解决es集群Yellow与Red的问题
1. 集群健康度 分片健康,在集群中节点的状态有三种:绿色、黄色、红色 红色:至少有一个主分片没有分配,表示集群无法正常工作。 黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行&#x…
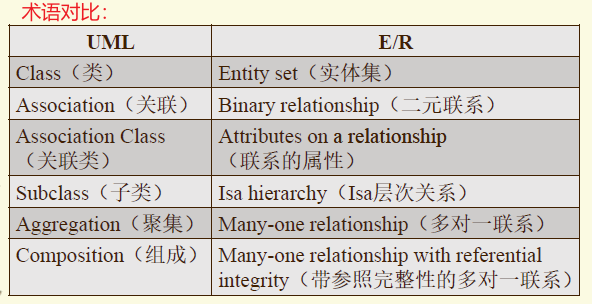
数据库原理 第五章 笔记
文章目录五、数据库设计1. 数据库设计全过程2. ER模型2.1 ER模型的基本元素2.2 联系的设计2.3 采用ER模型的设计概念2.4 ER模型向关系模型的转换3. UML模型3.1 UML3.2 UML模型到关系模式的转换五、数据库设计 1. 数据库设计全过程 数据库各级模式的形成
数据库的各级模式是在设…
Spark源码分析之一:Job提交运行总流程概述
Spark是一个基于内存的分布式计算框架,运行在其上的应用程序,按照Action被划分为一个个Job,而Job提交运行的总流程,大致分为两个阶段: 1、Stage划分与提交 (1)Job按照RDD之间的依赖关系是否为宽依赖,由DAGScheduler划分为一个个Stage,并将每个Stage提交给TaskSchedule…
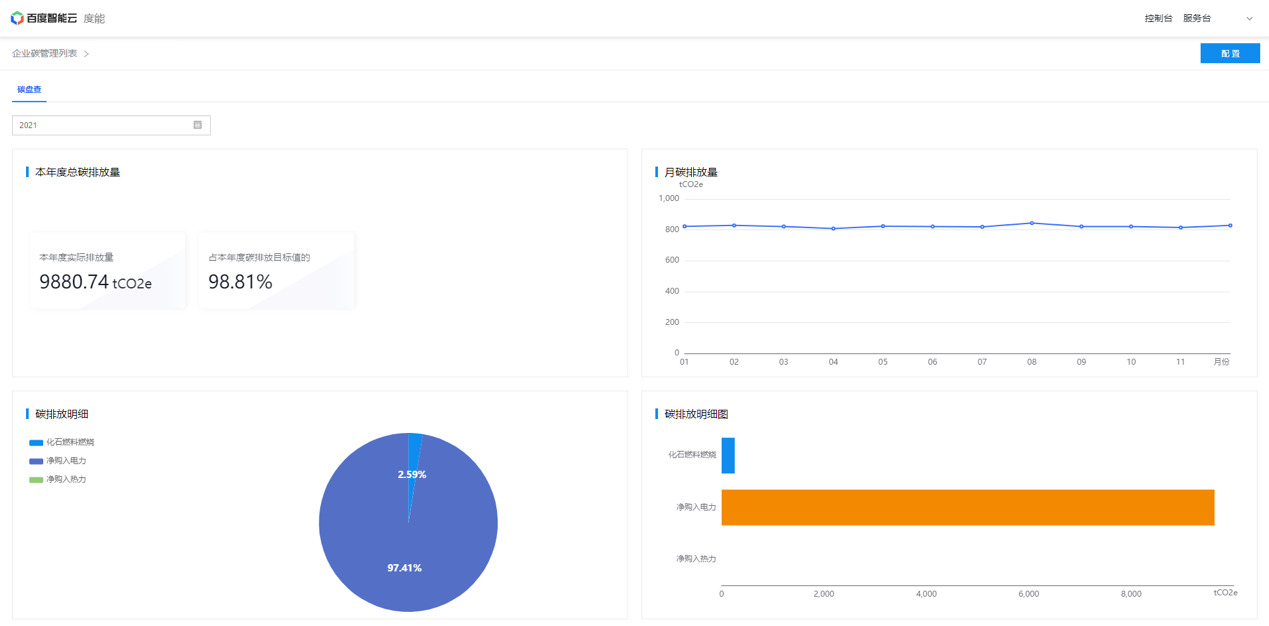
百度智能云度能全新推出SaaS服务,为企业能源数字化轻量转型提供灵活选择
伴随5G、AI等技术的成熟发展,人工智能作为新一代产业变革的核心驱动力之一,正在加速产业创新。智能化带来的不仅仅是效能的改变也为企业创造更低碳的未来。在国家双碳战略的背景下,百度智能云充分利用技术优势,不断深入对细分领…

人力RPA@你,你的HR机器人已上线
“大多数公司中,人们用2%的精力招聘,却用75%的精力来应对当初的招聘失误。”
——美国第一资本投资国际集团公司的首席执行官理查德•费尔班克
企业对各类人才的招聘热情带动了相应岗位的投递量,这也必然增加了人事部门的工作量,…

实在智能财务RPA:数字化转型在路上
财务属于强规则领域,在业务流程中存在大量重复的工作(如扫描传输、复制粘贴、排序筛选、数据录入等操作)需要手工完成,这些工作的业务特点与RPA技术的应用条件高度匹配。
财务部门作为企业核心职能部门,记录着企业所有…

走进准独角兽,看实在智能RPA数字员工重新定义RPA
11月25日,由杭州市科技局、杭州市创业投资协会组织的“2021杭州独角兽(准独角兽)走访活动”来到了实在智能。本次活动由杭州市创业投资协会常务副会长兼秘书长、杭州日报传媒有限公司副董事长傅强带队,携赛圣谷、杭州联合银行等10…

实在智能@空客RPA:共启数字化转型新时代
摘要:空中客车(天津)总装有限公司给杭州实在智能科技有限公司发来一份表扬信,信中对实在智能RPA系统交付项目组给予肯定和表扬。
近日,我们收到了一份实实在在的感谢——空中客车(天津)总装有限…
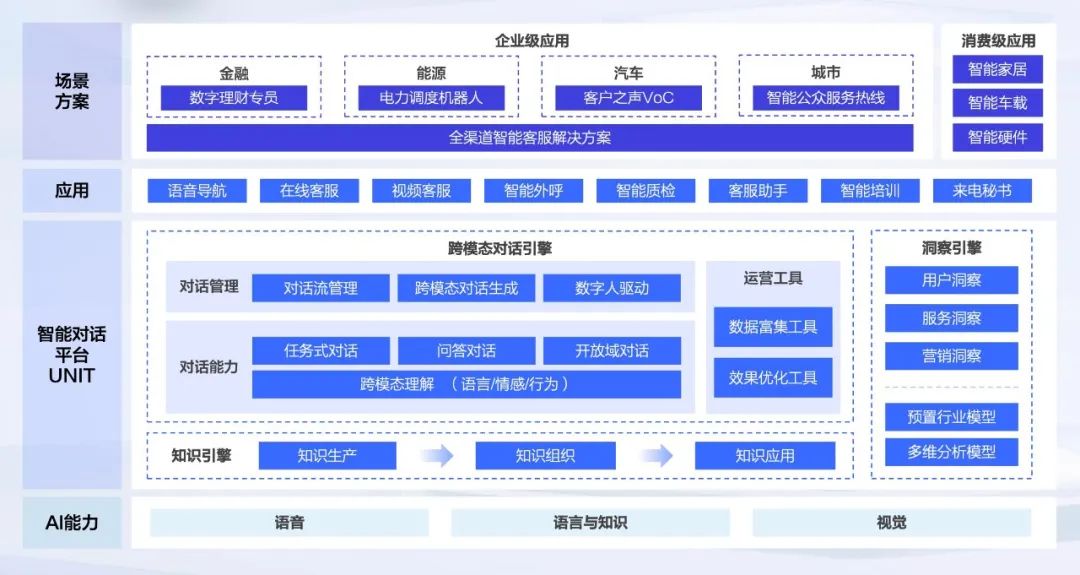
智能对话平台UNIT 7.0三大引擎正式亮相
在人工智能技术与产业深度融合发展的大潮下,企业应用全面迈入“智能对话”时代,智能对话平台已成为企业智能化转型的首选产品。5月18日,在“2022云智技术论坛-智能对话专场”上,百度智能云发布了智能对话平台 UNIT 7.0ÿ…

位列首位 百度智能云开物入选“双跨”平台国家队
5月5日,工信部发布2022年新增跨行业跨领域工业互联网平台(简称“双跨”平台)清单,百度智能云开物首次申报即入选“国家队”,在新增企业中位列首位。 开物是百度智能云在2021年推出的工业互联网平台品牌,以…
拾肆:Spark with Hive和Hive on Spark
在 Hive 与 Spark 这对“万金油”组合中,Hive 擅长元数据管理,而 Spark 的专长是高效的分布式计算,二者的结合可谓是“强强联合”。今天这一讲,我们就来聊一聊 Spark 与 Hive 集成的两类方式,一类是从 Spark 的视角出发,我们称之为 Spark with Hive;而另一类,则是从 Hi…

实在智能RPA微观:HR崩溃上热搜
摘要:实在智能RPA数字员工可以帮助人力部门解决招聘、员工福利管理等环节的大量重复性操作,有效地解放人力部门的生产力。
一则#HR做得快崩溃了#的热搜引起了很多从事人力行业朋友的共鸣,众多人力行业从业者在话题下分享了自己工作中的或糟心…
实在智能IPA:助力电商提质降本增效
双十二在即,各大电商已经摩拳擦掌,纷纷为接下来的宣传、促销、产品上下架等活动出谋划策。然而,这些工作费时费力,倘若由人工独立完成不知要到何年何月。目前,各大电商已经纷纷加入了AI(人工智能࿰…
mysql数据库应用软件navicat快捷键
mysql数据库应用软件navicat快捷键
navicat快捷键
ctrlF 搜索本页数据CtrlQ 打开查询窗口Ctrl/ 注释sql语句CtrlShift / 解除注释CtrlR 运行查询窗口的sql语句CtrlShiftR 只运行选中的sql语句F6 打开一个mysql命令行窗口CtrlL 删除一行CtrlZ 返回上一个操作CtrlN 打开一个新的…
从X70系列影像旗舰看vivo的高端市场野心
9月9日,vivo X70系列正式发布,凭借自研芯片和全新影像性能,一出场便成了市场上最靓的仔。特别是搭载了V1芯片和蔡司镜头的vivo X70 Pro,更是备受用户关注。
9月15日,iphone 13系列发布,凭借加量不加价的“…
Hazelcast Jet 聚合(Aggregate)
前言
Jet内部使用了2阶段聚合。第一阶段为accumulate,第二阶段为combine。 为什么使用2阶段的聚合方式呢? 因为单阶段的聚合方式仅仅适用于batch,在流式聚合中,单阶段的方式违背了数学定理CA(commutative associative…

Kafka MirrorMaker 跨集群同步工具详解
一、MirrorMaker介绍
MirrorMaker是Kafka附带的一个用于在Kafka集群之间制作镜像数据的工具。该工具从源集群中消费并生产到目标群集。这种镜像的常见用例是在另一个数据中心提供副本。 图1. MirrorMaker
对于迁移的topic而言,topic名字一样, partitio…


大数据--hadoop生态--hdfs最全总结
目录
第二章:HDFS
2.1 hdfs主要组件及其功能
2.1.1 Hdfs的组成
2.1.2 SecondaryNameNode
2.2 hdfs数据存储原理
2.2.1 冗余数据保存
2.2.2 数据存取策略
2.2.3 HDFS块的大小
2.2.4 数据错误与恢复
2.3 hdfs读写数据过程
2.3.1 读数据过程
2.3.2 写数据过…

大数据--数据仓库--数据同步方式
第四章:同步策略/存储方式
4.1 数据存储方式概述 首先弄清楚,增量同步,快照同步,增量表,全量表,拉链表之间的关系。 4.2 全量 全量表无分区,每天凌晨流程执行完后,表中的数据是截至…
大数据--数据仓库--事实表设计
目录 第三章:事实表设计
3.1 事实表设计原则
3.2 事实表设计方法
3.3 事实表分类
3.3.1 事务事实表
3.3.2 周期快照事实表
3.3.3 累积快照事实表
3.3.4 三种事实表比较 第三章:事实表设计
3.1 事实表设计原则
原则1:尽可能包含所有与…

实在智能RPA厂商:银行业务数字化大潮下,RPA机器人如何发挥作用?
大数据时代,数字化依然是企业与机构在时代大潮下必须要做出的决定,而作为天然的数据与信息集散地,银行的数字化升级毫无疑问拥有着最容易发生化学反应的场景,2020年10月,银保监会主席郭树清强调“所有金融机构都要抓紧…

数据库原理 第一章 笔记
文章目录一、数据库基础概念1. 数据和信息2. 数据库、数据库管理系统、数据库系统、数据库管理员3. 数据库系统的体系结构4. 数据模型5. 数据管理技术的产生和发展一、数据库基础概念
1. 数据和信息
1)信息
信息是客观存在的,是关于现实世界事物的存在…

大数据--数据仓库--维度设计
目录 第二章:维度设计
2.1 维表层建设原则
2.1.1 维度的基本概念
2.1.2 维度的设计方法
2.1.3 确定维度属性
2.2 维度模型分类
2.2.1 星型模型
2.2.2 雪花模型
2.2.3 星座模型 第二章:维度设计
2.1 维表层建设原则
2.1.1 维度的基本概念 维度是…
mysql数据库的常规操作你不知道的那些事
目录 1.sql的执行顺序
from>where>group by>having>select>order by>limit
2.mysql的存储引擎
存储引擎有MyISAM和InnoDB mysql的默认引擎是InnoDB
两者的区别:
MyISAM没有行锁;只有表锁;InnoDB有表锁、行锁
行锁&…
Ubuntu16.04下Hadoop的本地安装与配置
Ubuntu16.04下Hadoop的本地安装与配置一、系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 3.3.1
二、安装步骤 1、安装并配置ssh 1.1 安装ssh 输入命令: $ sudo apt-get install openssh-server ,安装完成后使用命令 $ ssh localhost …

达梦DM8数据库安装和创建实例
最近在学习国产达梦数据库,结合自己的经验,将达梦数据库安装和实例配置记录如下:
1、基础环境和用户创建
#####当前达梦可以运行在X86、龙芯、飞腾等处理器架构上
#####查看cpu型号及信息
more /proc/cpuinfo
#####内存不少于1g
[rootsyste…

RPA机器人@你:把繁琐留给我,你去创造闪光的人生
摘要:实在RPA助你实现工作流程自动化,减少重复繁琐的操作,获得更多的成就感,创造属于你的闪亮人生!
正文:
近日,B站有个视频《甲方,你睡了吗?我睡不着》冲上了首页&…

双碳目标下煤炭行业的发展与挑战:矿山环保信息化,时代的必然选择
随着构建资源节约型、环境优化型社会是国民经济与社会发展中长期规划的一项战略任务,国家对环境保护的重视程度日益提高;同时随着十四五和双碳目标的提出,煤炭行业迎来了全新的挑战,如何提高环保信息化程度,实现污染物…

数据应用广场,使用户掌握数据主权
随着企业建设的业务系统越来越多,沉淀的数据体量也愈来愈庞大,而当前数据治理产品大多为技术人员开发使用,客户对治理结果无感知,企业在数据应用方面数据不可见、不可查、难感知、难管理等问题越发明显,极大的降低了数…
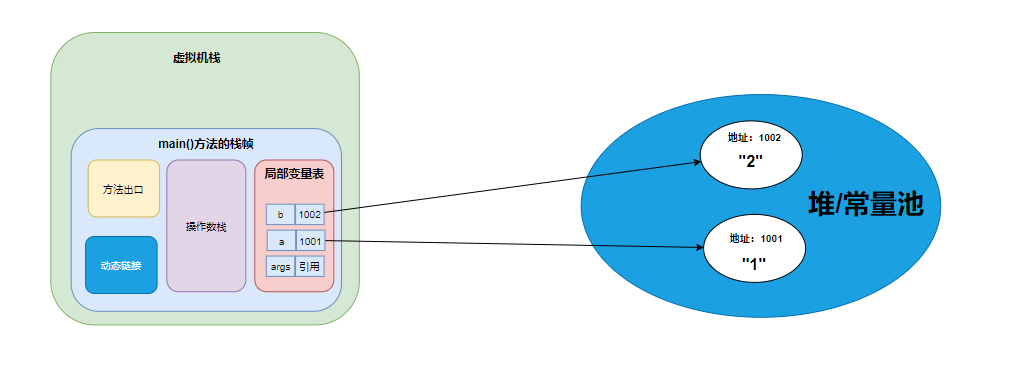
从JVM底层原理分析数值交换那些事·Java大数据高级架构师
基础数据类型交换
这个话题,需要从最最基础的一道题目说起,看题目:以下代码a和b的值会交换么: public static void main(String[] args) {int a 1, b 2;swapInt(a, b);System.out.println("a" a " , b" …

测试spark操作hudi 0.9 cdh6.3.2 版本不兼容时
spark-shell操作 (1)spark-shell启动,需要指定spark-avro模块,因为默认环境里没有,spark-avro模块版本号需要和spark版本对应,(可以在maven仓库https://mvnrepository.com/查看spark 个版本对应的spark-avro有没有再maven仓),并且使用Hudi编译好的jar包。 发现spark-avro…

浙外国际学院副院长莅临实在智能,共探产学研合作新方向
11月23日,浙江外国语学院国际商学院副院长方美玉及杨炳麟、蔡乐毅、苟建华、韩林静、姚雯雯老师一行莅临实在智能,双方就产学研基地合作进行深入讨论,共同培养数字化专业人才。 数字化人才已经成为世界范围内数字化经济发展的刚需,…

智慧矿山综合管控平台,实现井上井下一体化管理
「煤矿智能化是新时代煤炭工业的必由之路」
煤矿智能化是煤炭工业高质量发展的核心技术支撑,将人工智能、工业物联网、云计算、大数据、机器人、智能装备等与现代煤炭开发利用深度融合,形成全面感知、实时互联、分析决策、自主学习、动态预测、协同控制…

治理数据烟囱,给予数据无限生命,赋能业务
随着大数据及工业信息化的快速发展,多样性的数据源体量在日趋递进式增长,形成多源异构的数据烟囱,从而衍生出企业对各类数据如何协同管理的难题,也导致大量的数据失去了自身的无限价值。如何进行系统化的数据治理,达到…
实在智能|电商RPA:电商领域的张同学
近日,抖音上张同学的视频可谓是异常火爆,用专业的拍摄手来表现农村单身男青年的日常生活,真是别具一格。不过,现在人们对抖音的印象就是先通过短视频吸粉,然后再直播带货,完成商业变现。这似乎已经是人们的…

实在智能RPA告诉你,高效快速才是你的《狂扁小朋友》
近日,某站上一位自称学了十年代码的UP主自己制作《狂扁小朋友》游戏过程的视频大火,引来了一众网友的围观和讨论,同时也赢得了众网友的点赞喝彩。
网友从这位UP主的身上看到了游戏制作背后的故事,也发现原来制作游戏是这么好玩的…
数据库四大特性和三大范式
事务的四大特性?
事务特性ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
原子性是指事务包含的所有操作要么全部…

5.Spark 学习成果转化—机器学习—使用Spark ML的线性回归来预测商品销量 (线性回归问题)
本文目录如下:第5例 使用Spark ML的线性回归来预测商品销量5.1 数据准备5.1.1 数据集文件准备5.1.2 数据集字段解释(按列来划分)5.2 使用 Spark ML 实现代码5.2.1 引入项目依赖5.2.2 加载并解析数据5.2.3 对 DtaFrame 中的数据进行筛选与处理5.2.4 将特征列合并为特…

1.Spark ML学习笔记—Spark MLlib 与 Spark ML、Pipelines 的主要概念、实例(Estimator, Transformer)
本文目录如下:第1章 Spark 机器学习简介1.1 Spark MLlib 与 Spark ML1.1.1 Spark MLlib1.1.2 Spark ML (重点)1.2 Pipelines 的主要概念1.2.1 转换器 (Transformer): 实现了 transform() 方法1.2.2 评估器 (Estimator): 实现了 fit() 方法1.2.3 管道 (Pipeline)1.2.…

下一关口令:别犹“豫”,看“浙”里,一起“皖”
“实在三城记”: 大众创业万众创新
实在智能再次亮相双创周
10月19日至25日,2021年全国大众创业万众创新活动在郑州举行。实在智能作为全国144个项目及浙江省六家代表企业之一,继2019年入选「双创」主题展示项目后再次亮相主会场࿰…

1.Kafka基础—Kafka 简介、发布/订阅模式、基础架构、Kafka 安装、使用、使用脚本启动 Kafka 集群
本文目录如下:第1章 Kafka 基本概念1.1 Kafka 简介1.1.1 消息队列模式—发布/订阅模式1.2 Kafka 基础架构第2章 Kafka 安装、使用、集成环境2.1 虚拟机环境准备2.2 Linux环境下安装Kafka环境2.2.1 集群规划2.2.2 安装Kafka2.2.3 操作 Kafka 集群2.2.3.1 前置条件: 启…
⑦SparkSQL初案例
先看看最基础的sparkSQL,创建简单RDD然后过滤
val sparkConf: SparkConf = new SparkConf().setAppName("BookCarCard").setMaster("local[2]") //生产不要这段
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate() …
Pyspark读写csv,txt,json,xlsx,xml,avro等文件
1. Spark读写txt文件
读:
df spark.read.text("/home/test/testTxt.txt").show()
-------------
| value|
-------------
| a,b,c,d|
|123,345,789,5|
|34,45,90,9878|
-------------2. Spark读写csv文件
读:
# 文件在hdfs上…

(六)需要关注的Spark配置项+性能优化
实际上,应用程序运行得稳定与否,取决于硬件资源供给与计算需要是否匹配。这就好比是赛车组装,要得到一辆高性能的车子,我们并不需要每一个部件都达到“顶配”的要求,而是要让组装配件之间相互契合、匹配,才能让车子达到预期的马力输出。 因此,不妨从硬件资源的角度切入,…
hive的数据倾斜解决(Map端、reduce 端 、join中)
hive的数据倾斜解决(Map端、reduce 端 、join中)
lianchaozhao 2020-11-02 15:24:08 667 收藏 4 分类专栏: 工作实践 hive 大数据 文章标签: hive 大数据 版权 hive 的数据倾斜一般我们可以分为 Map倾斜、reduce 倾斜和join 倾…

英伟达特邀实在智能RPA,亮相云栖大会
2021年10月19日,被誉为“科技圈春晚”的云栖大会在杭州云栖小镇正式开幕,作为业内公认的科技创新风向标,本次大会聚集了包括两院院士、行业领军人在内的上千位重磅嘉宾,将在四天时间内,设置超百场论坛以及多项科技活动…

Hive数据倾斜YT
什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点 stage里面有一个task结束时间特别长,99%的时间都在这个task
分为了Mapr Reduce和Join三个阶段 如 事实表 关联 每日抽取的维表拉链表,维表中有很多重复的org_code(开链闭链)和事实表中数据关联…

低代码平台百数助力商家企业打造更高效便捷的订单管理系统
近十年,电商行业的兴起,促进了零售渠道的融合发展。为了迎合市场发展,一个品牌需要对接多个渠道的订单数据信息,包括商品、合同、销售等各个板块,数据量之大,依赖传统的人工操作是无法及时反馈跟进的。越来…

新零售时代,数字化门店管理应该关注仓储会员店模式吗?
这两年,几乎你所有听过的大型超市都在重点开设推广自己的仓储会员店。 首先是老牌山姆会员店在国内市场的成功,而后Costco进入中国引起火爆场面,让业内重新审视国内消费市场的强大潜力。盒马X会员店、永辉仓储店、FUDI生鲜、华联、家乐福都集…

实在观察丨为什么RPA 四件套是企业数字化转型标配?
近年来,产业数字化转型需求不断扩大,越来越多的企业开始关注RPA(机器人流程自动化)。目前,RPA作为一款自动化工具,已广泛应用于电商、运营商、政务、金融等众多行业,在财务、人力、客服等劳动密…

云表:为什么要使用低代码开发?低代码选择指南
随着信息技术的不断发展,我们进入了一个数字化的时代。在这个时代,IT技术已经成为推动全球信息化浪潮的重要力量。然而,随着应用程序开发技术的不断发展,开发效率并没有像摩尔定律一样快速提升,反而成为了瓶颈。因此&a…

在 Tubi 做 Tech Lead 有多刺激!
上周我们发布了一篇《当你在 Tubi 是一位 Tech Lead》采访稿,后台收到了这样一条留言,说出了许多技术人在选择管理岗位还是继续深耕技术方向时的纠结: ‘有些同事更喜欢投入精力处理有挑战的事情,而不愿花费太多时间进行人际沟通&…

怎么快速区分不同客户?CRM告诉你
客户是由诸多个人构成的人群,年纪、个人爱好、教育情况、岗位这些决策着客户对产品和服务不一样的需求和期望。
销售员对全部客户都一视同仁得话,在应对一些无意选购的客户时,会用时费力,乃至会造成一些老客户及其对盈利增长率大…

RPA机器人:RPA这么好,究竟能不能快速应用呢?
当前,企业对成本控制、效率提升需求愈发明显,RPA即机器人流程自动化技术的作用逐渐显现,它主要是通过软件机器人自动处理企业内部规则性强、重复性高的工作流程任务,实现企业提质、降本、增效。 那么如何判断能否接入RPA呢&#x…

生鲜电商有哪些盈利模式?
根据流量入口不同,生鲜企业分为3种模式:线上运营、线下社区和线上线下新零售。而根据企业的运营模式、配送方式和发展品类等不同,我们又可以细分为7大类型:综合平台型、垂直电商型、农场直销型、生鲜O2O型、社区便利店、社区团购和…
如何开通支付宝小程序助手?
小程序助手 是支付宝开放平台发布的官方小程序,为开发者提供小程序相关业务数据分析,其中提供数据概况,来源趋势及用户画像三大板块。
如何开通支付宝小程序助手?
如果您的支付宝账号已被设置为【开发者管理员】 或【 运营管理员…
一篇文章教你搞懂生鲜电商模式
生鲜电商,指用电子商务的手段在互联网上直接销售生鲜类产品,如新鲜水果、蔬菜、生鲜肉类等。
据企查查大数据研究院上个月发布的《近十年生鲜电商投融资数据分析报告》显示,2010年以来,我国生鲜电商赛道共产生融资事件287起&…

RPA企业:实在智能荣膺中国ToB行业年度创新力企业
12月29日,「ToB行业头条」联手3W集团正式发布《2021中国ToB行业年度榜单创新力榜》。 实在智能凭借在企业数字化赋能领域的卓越表现,以及持续进取的创新势头,从400多家参选企业中脱颖而出,实力获评「2021中国ToB行业年度榜单创新力…
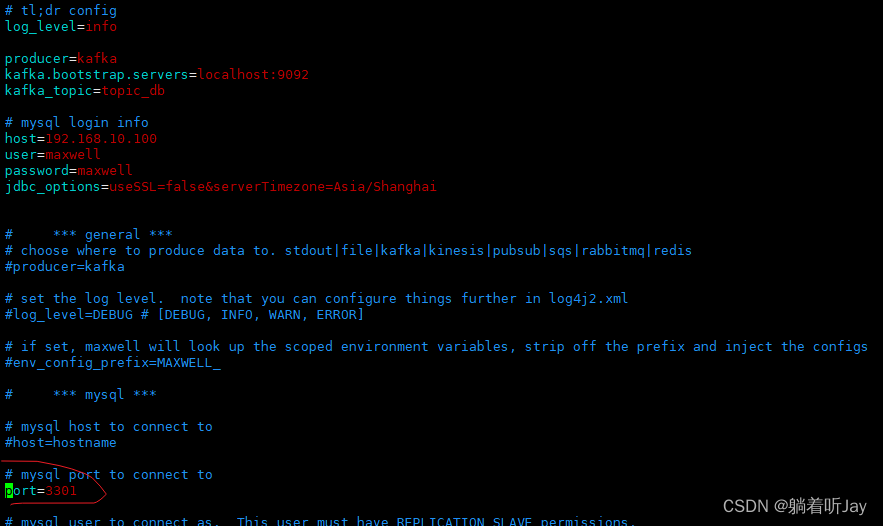

RPA优势:创新力MAX,实在智能获评全球科技营销创新TOP企业
12月21日,全球创新领域的年度盛会——由亿欧EqualOcean主办的“2021世界创新者年会”在上海重磅开幕,并在会上发布“世界创新奖(WIA)”系列榜单,对本年度科技创新领域最具突出成绩的个人和企业予以表彰。 作为数字化赋能领域的头部企业&#…

RPA那些事儿:实在智能获评36氪「WISE2021新经济之王」硬核企业
12月13日,万众瞩目的36氪「WISE2021新经济之王峰会」在上海重磅开启,会上揭晓了“WISE2021新经济之王——年度硬核企业”的评选结果。凭借业内领先的技术水平与出众的商业影响力,实在智能获评「WISE2021新经济之王」年度硬核企业,…

从零开始了解大数据(七):总结
系列文章目录 从零开始了解大数据(一):数据分析入门篇-CSDN博客 从零开始了解大数据(二):Hadoop篇-CSDN博客 从零开始了解大数据(三):HDFS分布式文件系统篇-CSDN博客 从零开始了解大数据(四):MapReduce篇-CSDN博客 从零开始了解大…

你关心的RPA技术都在这个发布会!
金秋十月,是实实在在收获的季节!实在智能作为一家行业领先的人工智能科技公司,致力于通过AI技术引领和推动RPA行业向IPA发展。公司在实实在在地解决客户真实痛点堵点过程中,全自研RPA产品和 AI 能力再次获得大幅提升,每…

实在智能秋季发布会——实在人为,智能取胜!
金秋十月,是实实在在收获的季节!实在智能作为一家行业领先的人工智能科技公司,致力于通过AI技术引领和推动RPA行业向IPA发展。公司在实实在在地解决客户真实痛点堵点过程中,全自研RPA产品和 AI 能力再次获得大幅提升,每…

大数据领域现状flink,storm,sparkstreaming,sql引擎
Hadoop 生态组件竞争激烈,Spark 优势明显,MapReduce 已进入维护模式 曾有开发人员表示,Hadoop 主要是被 MapReduce 拖累了,其实 HDFS 和 YARN 都还不错。堵俊平( 腾讯云专家研究员)则认为 MapReduce 拖累 H…
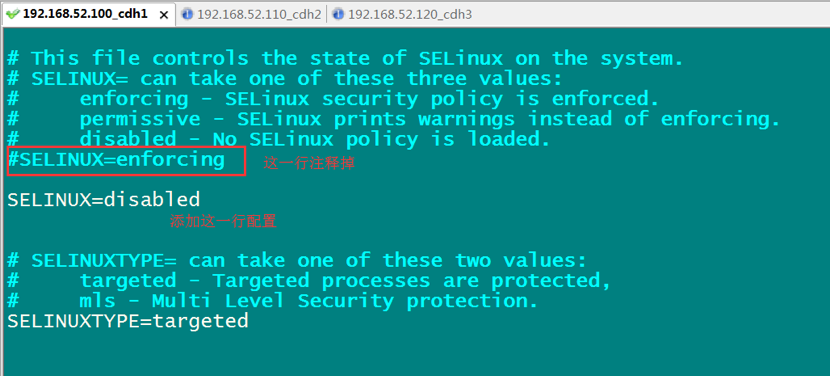
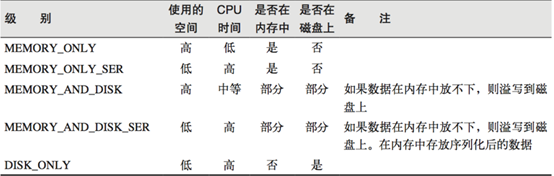
对Spark中一些基础概念的了解
1、Driver:运行应用程序的main函数,并创建SparkContext进程。初始化SparkContext是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与集群进行通信,并进行资源的申请、任务的分配和监控等。当Worker节点中的Executo…

jy-09-SERVLETJSP——Maven
目录:
1.Maven
2.Maven详解 1.Maven Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具。 Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则…
浅谈基于中台模式的大数据生态体系的理解
这篇文章主要浅谈一下我对大数据生态体系建设的理解。 大数据生态系统为高并发,高吞吐,高峰值,高堆积等大规模数据的采集,处理,计算,存储,服务提供了完善的处理体系,致力于打造核心数…
数字化转型导师坚鹏:政府数字化转型之数字化技术
政府数字化转型之数字化技术
——物联网、云计算、大数据、人工智能、虚拟现实、区块链、数字孪生、元宇宙等综合解析及应用
课程背景:
数字化背景下,很多政府存在以下问题:
不清楚新技术的发展现状?
不清楚新技术的重要应…

数字孪生,开启3D智慧园区管理新篇章
在各行各业数字化转型的浪潮中,园区也在转型发展:从传统园区向智慧园区不断演进。传统园区缺乏系统性规划,基于单点功能的建设,导致系统孤立、管理粗放且服务不足等问题,已难以满足人们日益增长的多样化需求。在需求与…

智慧工地-未来工地新形态
一、什么是智慧工地?
随着城市建设的不断深入,建筑行业得到蓬勃发展,工地面积、人员、设备物资、以及作业流程都有了质的提升,目前的智慧工地产品以BIM为核心树立建筑管理和以IOT为核心打造感知系统,已出现系统碎片化…

数据治理之IT系统存量信息梳理
在大数据背景下,数据作为数字经济的关键要素已经得到广泛认可,企业要为众多数据消费需求提供优质的数据供给,必须要做好数据治理。数据治理的对象包含存量数据及增量数据,对存量数据的治理重点在于实现分而治之、建章立制…

智慧城管——开启精细化城市管理
近年来,随着城市化进程的不断发展和城市基础设施不断完善,城市化过程中重建设、轻管理的治理模式给城市管理造成了困境。如何保证城市居民的生活质量,创造和谐开放的城市公共环境,已成为城市管理的重点。
在国务院印发的《中共中…

数据采集,一切数据管理流程的起点
当前,数字经济成为我国经济发展的新引擎,企业面临以大数据为核心的数字化转型的重要机遇和挑战。同时,伴随着数字化转型的加剧,企业日常运营中产生的数据量成指数级增长,且数据的类型更加多样化,数据应用场…

核音智言 | 维护数据安全,实现数据资产价值
一、数据安全危机
随着全球数字化趋势的来临,各行各业正在逐步进行数字化转型,数据被看作创造价值的核心资产。随着信息化技术的高速发展,大量业务数据持续迁移到网络环境中,不法组织与个人正在觊觎数据资产。 近年来,…
第三章 数据存储-数据库基础及MySQL使用 2021-09-23
爬虫系列总目录
本章节介绍数据存储相关内容。 第三章 数据库简介与MySQL使用 数据存储-数据库基础及MySQL使用爬虫系列总目录一、 数据库介绍1.1 数据库分类主要特点主要特点二、MySQL 数据库使用2.1 MySQL版本2.2 命令使用2.3 数据类型2.4 MySQL中约束的分类2.5 建库建表与 …

涂鸦商照智慧工业照明车间应用案例详解(内附系统拓扑图)
据中商产业研究院预测,2021年中国智能照明行业市场规模将超350亿元。 其中,工业及商业领域是智能照明行业最大的应用领域,占比57.21%。 工业照明泛指在人类从事生产劳动的各类工业厂房、物流仓储空间等场所的照明,受制于空间范围的…

ElasticSearch7学习笔记之聚合分析
文章目录定义Bucket聚合Metric聚合Pipeline聚合Matrix聚合聚合的作用范围作用范围为query结果集通过filter改变作用范围通过post_filter改变作用范围global全局聚合排序原理和精准度定义
ES除了检索之外,还提供对数据进行的统计分析功能,实时性比较高
…
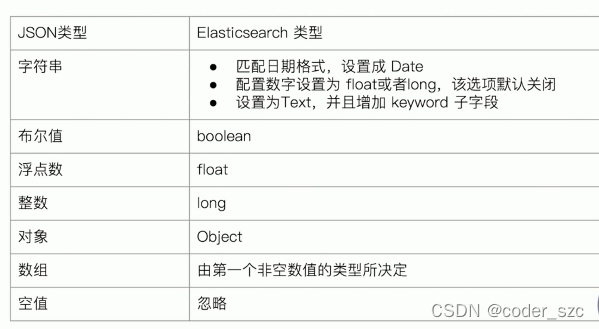
ElasticSearch7学习笔记之Mapping
文章目录背景倒排索引定义核心组成ES中的数据类型DynamicMapping能否更改Mapping的字段类型dynamic为falsedynamic为strict自定义Mapping定义字段可否被检索空值响应copy_to字段拼接IndexTemplate更新模板查看模板DynamicTemplate背景
ES中的Mapping类似数据库中的schema&…

关于数据库连接不上用户的问题~
cmd命令行中进入MySQL,
alter user myuser% identified with mysql_native_password by 你的密码;flush privileges;命令行结果如下:
alter user David identified with mysql_native_password by 密码;
flush privileges;数据库结果如下&…

玩转MYSQL(2) 数据库的约束、聚合查询、联合查询以及三种表的设计
目录标题一、MYSQL的那些约束你掌握了几种?二、表与表之间的三种关系三、查询3.1 :聚合查询3.2、GROUP BY3.3、HAVING和group by 搭配使用3.4、联合查询3.4.1内连接3.4.2 外连接3.4.3 自连接3.5、子查询3.5.1单行子查询3.5.2多行子查询3.6、合并查询四、结尾一、MYS…
ElasticSearch7学习之搜索API
文章目录概述URI search普通URI查询Phrase查询term查询布尔查询与逻辑:AND要求某一字符串不存在:NOT指定范围通配符查询请求体查询对某字段进行排序指定保留的字段使用脚本添加字段逻辑操作符match_phrasequery_string和simple_query_stringquery_string…

农粮组织数据分析实战
知识点:
1.pandas中空值是none,所以可以用isnull()方法来统计 面板数据:同一指标的对比 2.地理上相互联系的是否有关联
3.随着时间的推移是否有变化
4.时间序列的处理方法 按照时间切片
def time_slice(df, time_period):# Only take dat…
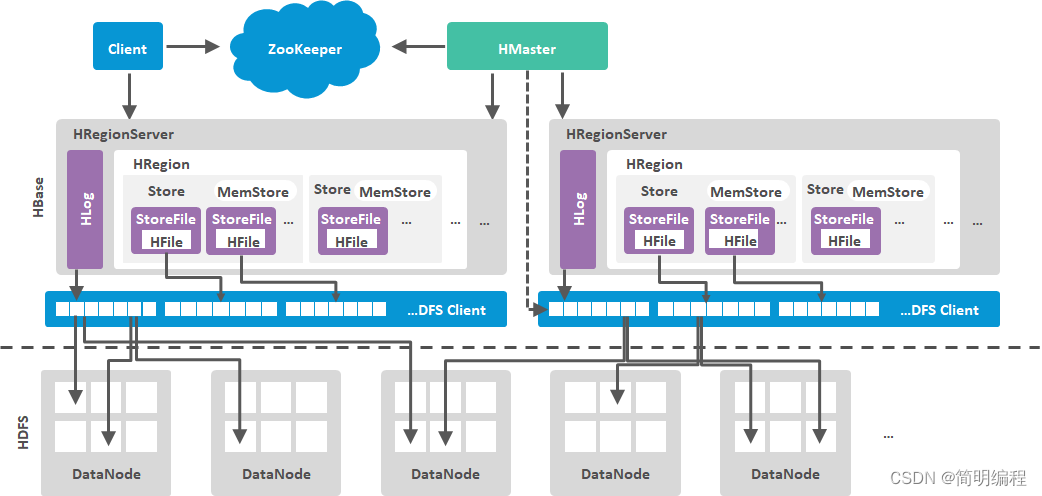

使用门槛高?操作太复杂?看完这款数字机器人,你会有新发现~
10月,对于实在智能来说,无疑是一个收获的季节。
10月10日,实在智能创始人兼CEO孙林君在2021中国人工智能年会暨中国AI金雁奖颁奖典礼上领取了金雁奖之领军企业大奖、创新企业大奖、先行者奖、创新技术大奖、领军应用大奖共5项大奖࿰…
【Datax分库分表导数解决方法】MySQL_to_Hive
Datax-MySQL_to_Hive-分库分表-数据同步工具
简介: 本文档介绍了一个基于Python编写的工具,用于实现分库分表数据同步的功能。该工具利用了DataX作为数据同步的引擎,并通过Python动态生成配置文件,并调用DataX来执行数据同步任务…
良心无广的4款软件,由于免费又实用,常被同行挤压
闲话少说,咱们直接上狠货!
飞观
飞观,一款助你汲取知识、实现迅速成长的高品质视频软件,适用于IOS和Android系统,让你随时随地都能有所学习,有所收获。
飞观
这里汇聚的视频不仅清晰度出众,…

坐拥400W用户的免费软件,一夜关停:360、钉钉、WPS等未来几何?
谁曾预料到?那款昔日备受瞩目且风光无限的免费软件,竟然会一夜之间关停!
在2021年10月20日,今目标公司官方公告宣布正式停服。今目标,这个自2005年创立的知名品牌,作为一款备受欢迎的OA协同平台࿰…

spark本地模拟多个task时如何启动多个Excutor
1、首先在9090端口下启动Excutor,作为第一个Excutor 2、然后修改9090端口为:9091,如下图点击Edit Configration 3、然后按下图操作 , 4、修改一下名字 5、点击apply,🆗 6、检查下面圈1是否是刚刚我们新建的MyExcutor(2…

打造人人都能上手的软件机器人,我们都做了哪些努力?
10月,对于实在智能来说,无疑是一个收获的季节。
10月10日,实在智能创始人兼CEO孙林君在2021中国人工智能年会暨中国AI金雁奖颁奖典礼上领取了金雁奖之领军企业大奖、创新企业大奖、先行者奖、创新技术大奖、领军应用大奖共5项大奖࿰…

难以想象!一个RPA产品的发布会竟然可以这么酷炫?
金秋十月,是实实在在收获的季节!实在智能作为一家行业领先的人工智能科技公司,致力于通过AI技术引领和推动RPA行业向IPA发展。公司在实实在在地解决客户真实痛点堵点过程中,全自研RPA产品和 AI 能力再次获得大幅提升,每…

2024.1.8 Day04_SparkCore_homeWork
目录 1. 简述Spark持久化中缓存和checkpoint检查点的区别
2 . 如何使用缓存和检查点?
3 . 代码题
浏览器Nginx案例
先进行数据清洗,做后续需求用
1、需求一:点击最多的前10个网站域名
2、需求二:用户最喜欢点击的页面排序TOP10
3、需求三&#x…
PiflowX组件-OracleCdc
OracleCdc组件
组件说明
Oracle CDC连接器允许从Oracle数据库读取快照数据和增量数据。
计算引擎
flink
组件分组
cdc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子hostnameHostname“”无是Or…

JAVA连接MySQL 数据库
文章目录一、环境配置二、MySQL连接三、参考一、环境配置 IDEA使用入门 下载jar包 解压 下载MySQL 如图,根据自己需要选择安装方式,接下来有execute点击execute,有next就点击next,有finish就点击finish,需要自己设…
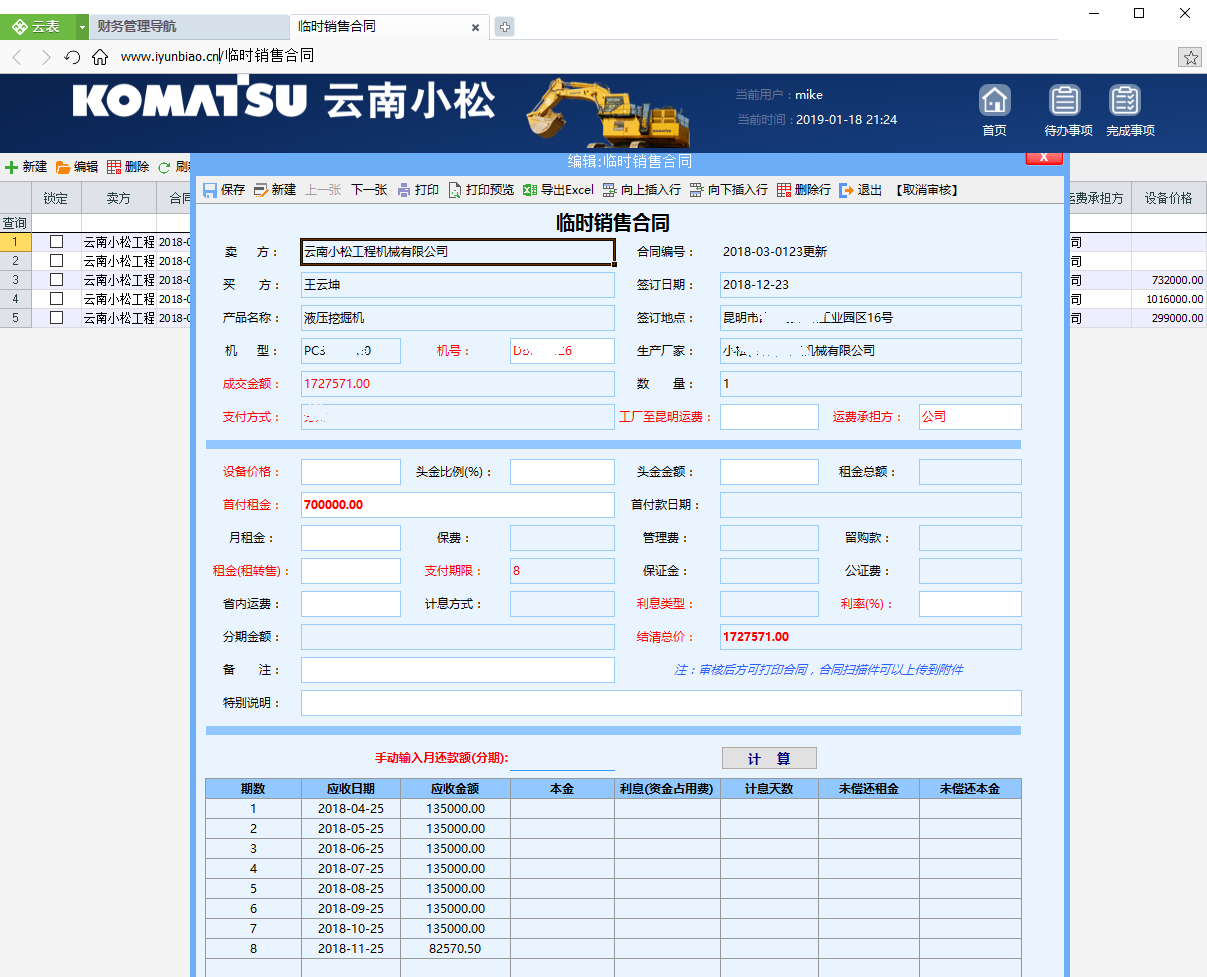
云表企业级无代码案例-复杂机械ERP管理系统
云南小松原本有供应商小松中国提供的一个数据管理系统,但是系统很简单,功能不能适时更新,对于企业相关业务管理也兼顾不到,而企业分支机构、人员、车辆、仓库等分布在全省各个角落(有工地的地方可能就有小松的员工&…

TDSQL inside之路
“力争让每一张钱都能打上TDSQL inside的标签”,距离潘安群在自己的朋友圈立下的这个flag,已经6年。 8月26日,在看到相关新闻之后,激动之余的老潘在朋友圈这样写道: “2016年第一次去人行立下的flag,今年要…

【数仓建设系列之一】什么是数据仓库?
一、什么是数据仓库?
数据仓库(Data Warehouse,简称DW)简单来讲,它是一个存储和管理大量结构化和非结构化数据的存储集合,它以主题为向导,通过整合来自不同数据源下的数据(比如各业务数据,日志文件数据等)…
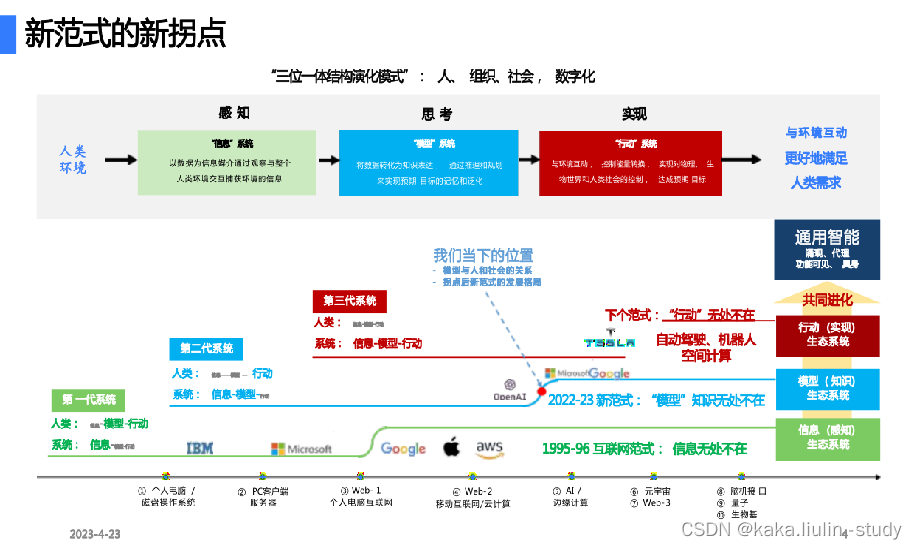
LLM赋能产业数智化业务系统升级的思考
1概述 2022年是人工智能的一个分水岭,ChatGPT,DALL E[ DALL E:是一款可以根据文本描述创建图像的AI工具。]和Lensa[ Lensa:是一款AI美图软件。]等几个面向消费者的应用程序发布了,它们的共同主题是使用生成式人工智能&…
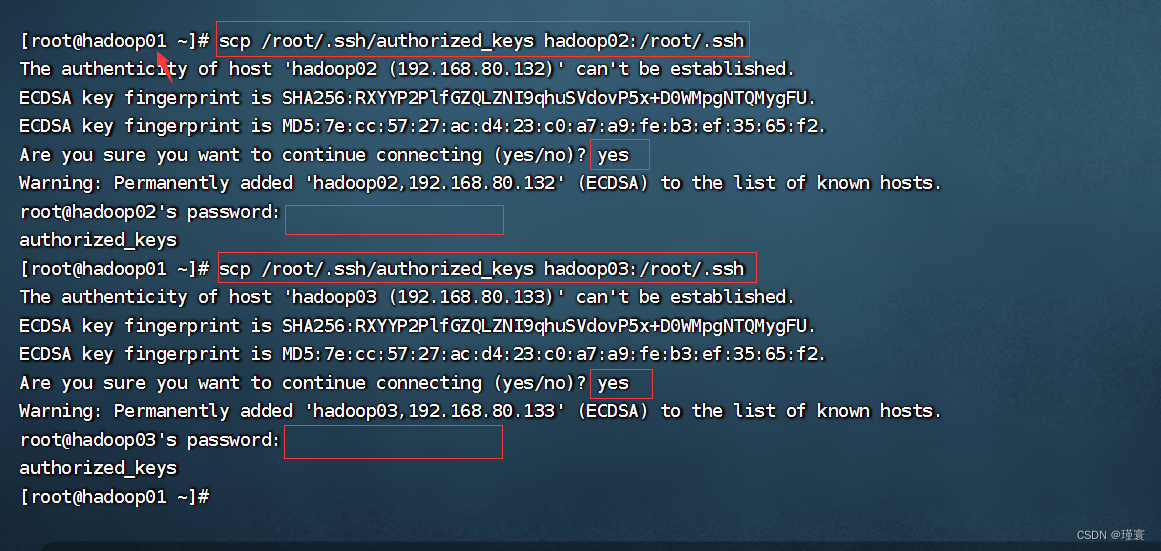
大数据项目实战(安装准备)
一,搭建大数据集群环境
1.1安装准备
1.1.1虚拟机安装与克隆
1.虚拟机的安装和设置以及启动虚拟机并安装操作系统(以下仅供参考)
安装一台虚拟机主机名为:hadoop01的虚拟机备用
VMware虚拟机安装Linux教程(超详细)_vmware安装…

大数据项目实战(Hadoop集群搭建)
一,搭建大数据集群环境
1.2 Hadoop集群搭建
1.2.1 jdk安装
1.下载jdk
(1)在根目录下创建三个子目录以备后用。具体如下:
mkdir -p /export/data mkdir -p /export/software
mkdir -p /export/servers (2)下载路径: 1、官网下载地址http…
“批量记录,轻松修改:让收支明细管理更高效!“
在繁忙的现代生活中,管理个人收支明细成为了我们理财的重要一环。晨曦记账本,作为一款功能强大的记账工具,致力于帮助用户轻松记录和管理每一笔收支,让财务更加清晰、有序。
第一步,首先我们要记进入晨曦记账本主页面…
云表:只需3步,让你搞懂低代码和传统开发有什么区别
自2014年Forrester明确提出低代码(Low-Code)概念以来,这个领域已经引起了广泛的关注,并逐渐受到越来越多的重视。近年来,低代码因为其低开发门槛、易用性等优点,赢得了众多投资研究机构和企业用户的青睐&am…
【物联网】Qinghub Kafka 数据采集
基础信息
组件名称 : kafka-connector 组件版本: 1.0.0 组件类型: 系统默认 状 态: 正式发布 组件描述:通用kafka连接网关,消费来自kafka的数据,并转发给下一个节点做相关的数据解析。
配置文…

云表|低代码助力职场人,一招制敌解决办公难题
身在职场,我们时常会面临一系列令人头疼的难题: ● 突然被领导要求30分钟内汇总所有人的填报信息,看着面前格式五花八门的Excel表格,我们无所适从,不知从何下手。 ● 在这个数字化的时代,公司仍然沿用古老的…

众望所归:FoxPro之后,可视化编程再现新突破,国产力作
许多以前的计算机语言,至今仍然展现出它们强大的生命力。
DOS时代下的FoxPro
然而,曾经风靡一时的FoxPro语言,如今已逐渐淡出人们的视野,令人不禁感慨万分。
每当提及FoxPro,总是有着无尽的话题和回忆。
想当年&am…
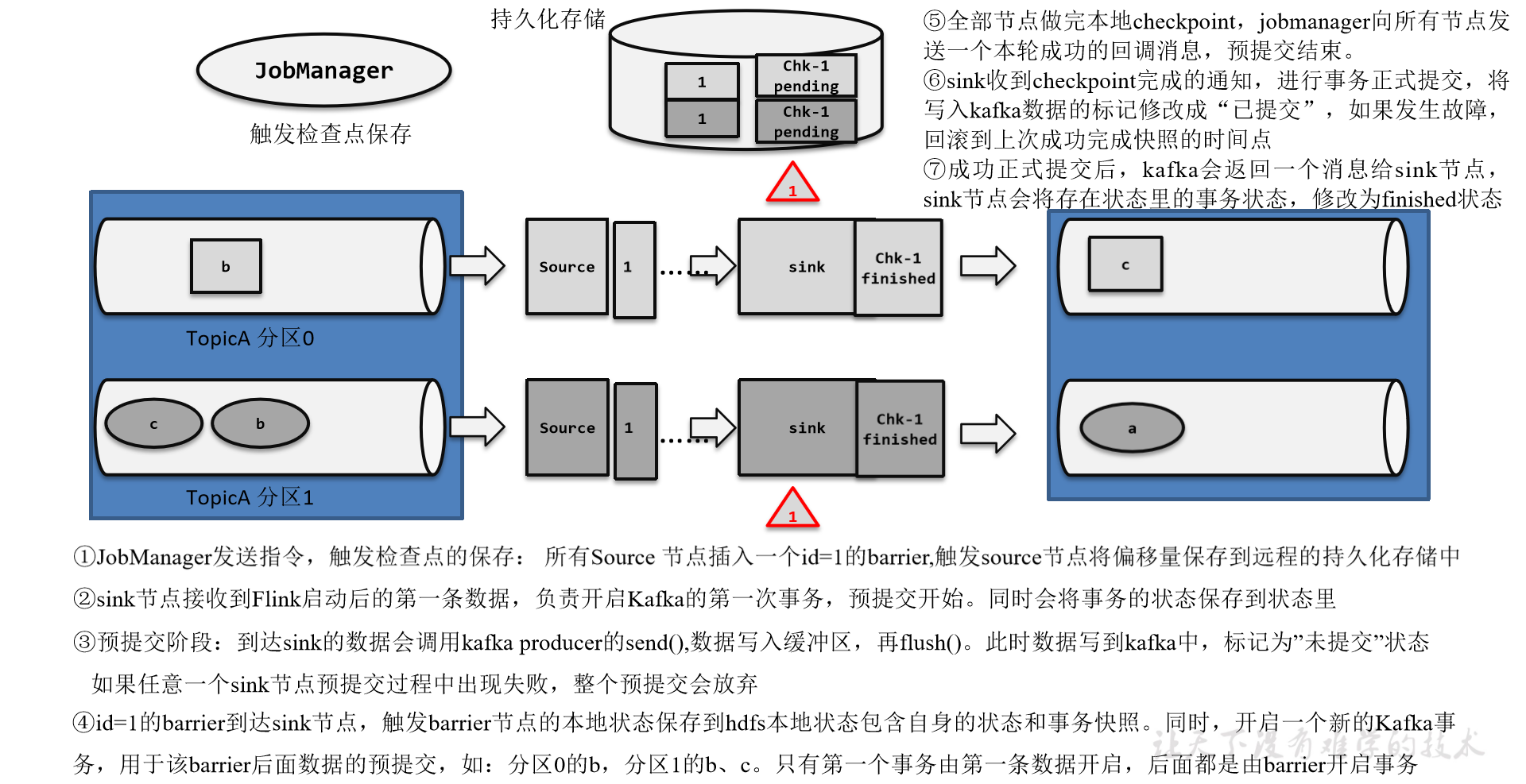
Flink1.17实战教程(第六篇:容错机制)
系列文章目录
Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程&…

WMS仓储管理系统与WCS系统:功能差异与特点对比
在物流行业的现代化管理中,WMS仓储管理系统和WCS仓库控制系统扮演着举足轻重的角色。虽然它们都是仓库管理软件系统,但是它们在功能和应用场景上存在显著的差异。本文将详细阐述这两者的功能和区别。 一、WMS仓储管理系统 WMS是一种综合性的软件系统&…
kylin3集群问题和思考(单机转集群)
目录
单机改集群注意事项
问题
思考
建议 单机改集群注意事项 之前是使用的单机版,但后面查询压力过大,一个方案是改成集群。 由于是同一个集群的,元数据没有变化,所以,直接将原本的kylin使用scp的方式发送到其他节…
供应链+低代码,实现数字化【共赢链】转型新策略
在深入探讨之前,让我们首先明确供应链的基本定义。供应链可以被理解为一个由采购、生产、物流配送等环节组成的网状系统,它始于原材料的采购,经过生产加工,最终通过分销和零售环节到达消费者手中。 而数字化供应链,则是…
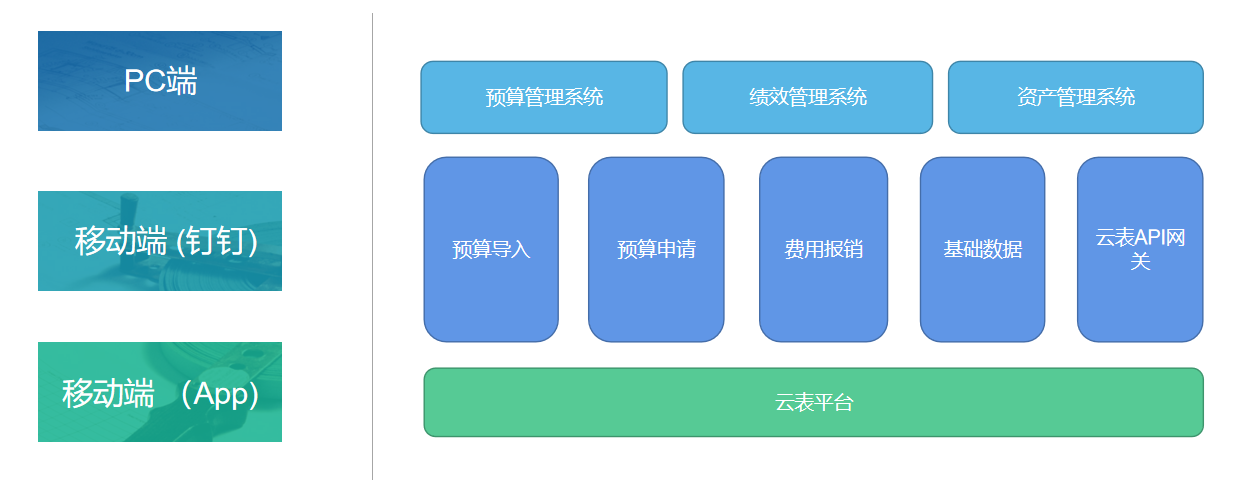
低代码助力制造业数智转型,激发创新力迎接工业 4.0
随着科技的不断进步,我们迈入了一个崭新的工业时代——工业4.0。这场工业革命不仅颠覆了制造业的传统形象,还为全球生产方式带来了前所未有的变革。 在这一过程中,制造业数字化转型逐渐成为主旋律,而低代码技术在这其中发挥着重要…
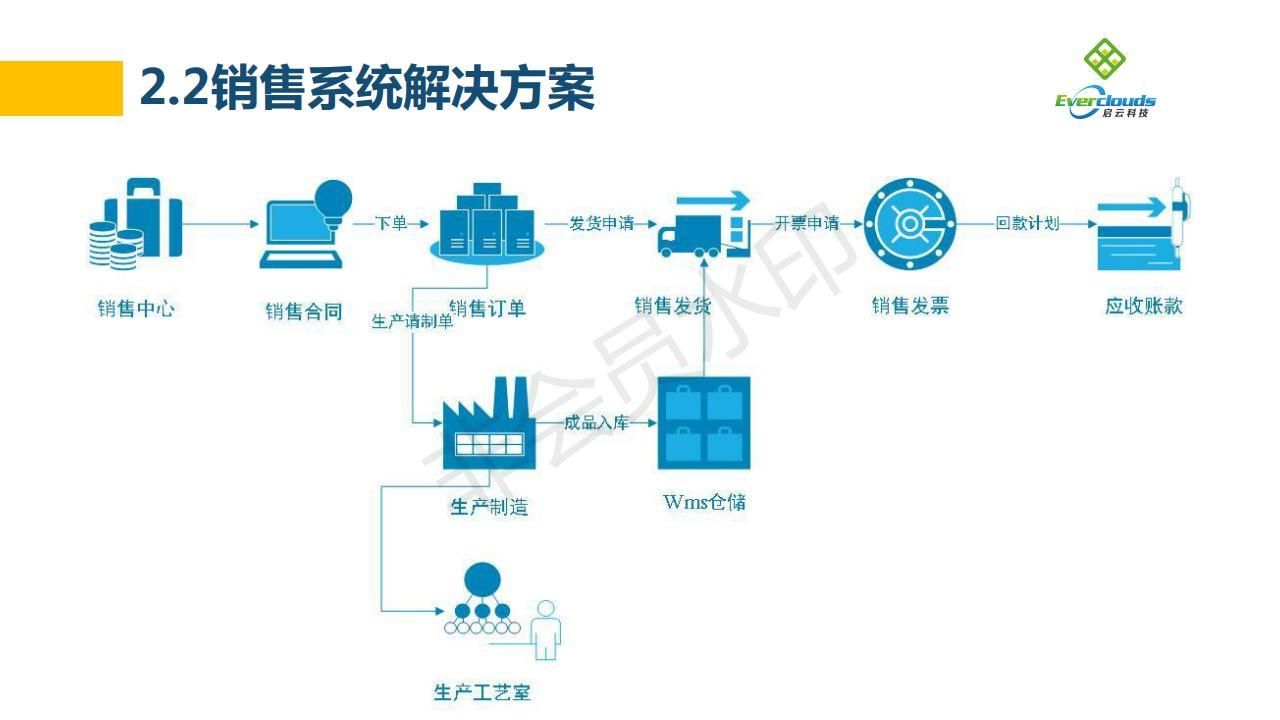
微软Office Plus与WPS Office的较量:办公软件市场将迎来巨变?
微软Office Plus在功能表现上远超WPS Office?
微软出品的Office套件实力强劲,其不仅在办公场景中扮演着不可或缺的角色,为用户带来高效便捷的体验,而且在娱乐生活管理等多元领域中同样展现出了卓越的应用价值
作为中国本土办公软…
数字化转型导师坚鹏:政府数字化流程管理
政府数字化流程管理
课程背景:
很多政府存在以下问题:
不清楚数字化对流程有什么影响?
不知道政府业流程如何进行优化?
不知道政府业流程优化的具体案例?
课程特色:
有实战案例
有原创观点
…
数字化转型导师坚鹏:数据安全法解读与政府数字化转型
网络安全法、数据安全法、个人信息保护法解读与政府数字化转型 课程背景:
很多机构存在以下问题:
不清楚网络安全法、数据安全法、个人信息保护法立法背景?
不知道如何理解网络安全法、数据安全法、个人信息保护法政策?
不…
Flink 1.11.0 版本介绍
Flink 1.11.0 发布于 2020 年,引入下面的新特性: 为了缓解 backpressure 下的 checkpointing 性能问题引入 unaligned checkpoints统一 Watermark Generator接口引入 Data Source API为 kubernates 引入新的部署模式:application modeUnaligned Checkpoints
触发一次 check…

MySQL 多表查询 连接查询 外连接
介绍
MySQL 多表查询 连接查询 内连接 外连接分为两种,左外和右外连接,
左外:相当于查询表1(左表)的所有数据 包含 表1和表2交集部分的数据,完全包含左表的数据 右外:相当于查询表2(右表)的所有数据 包含 表1和表2交集部分的数据…
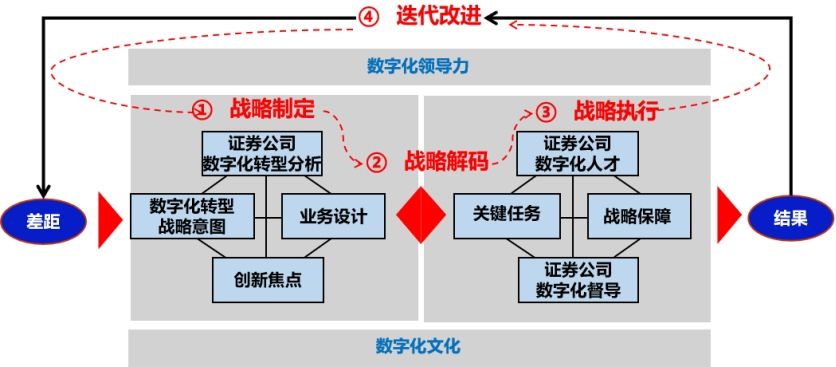
数字化转型导师坚鹏:BLM证券公司数字化转型战略
BLM证券公司数字化转型战略
——以BLM模型为核心,实现知行果合一
课程背景:
很多证券公司存在以下问题:
不知道如何系统地制定证券公司数字化转型战略?
不清楚其它证券公司数字化转型战略是如何制定的?
不知道…

2024年【山东省安全员C证】考试试卷及山东省安全员C证复审模拟考试
题库来源:安全生产模拟考试一点通公众号小程序
山东省安全员C证考试试卷根据新山东省安全员C证考试大纲要求,安全生产模拟考试一点通将山东省安全员C证模拟考试试题进行汇编,组成一套山东省安全员C证全真模拟考试试题,学员可通过…
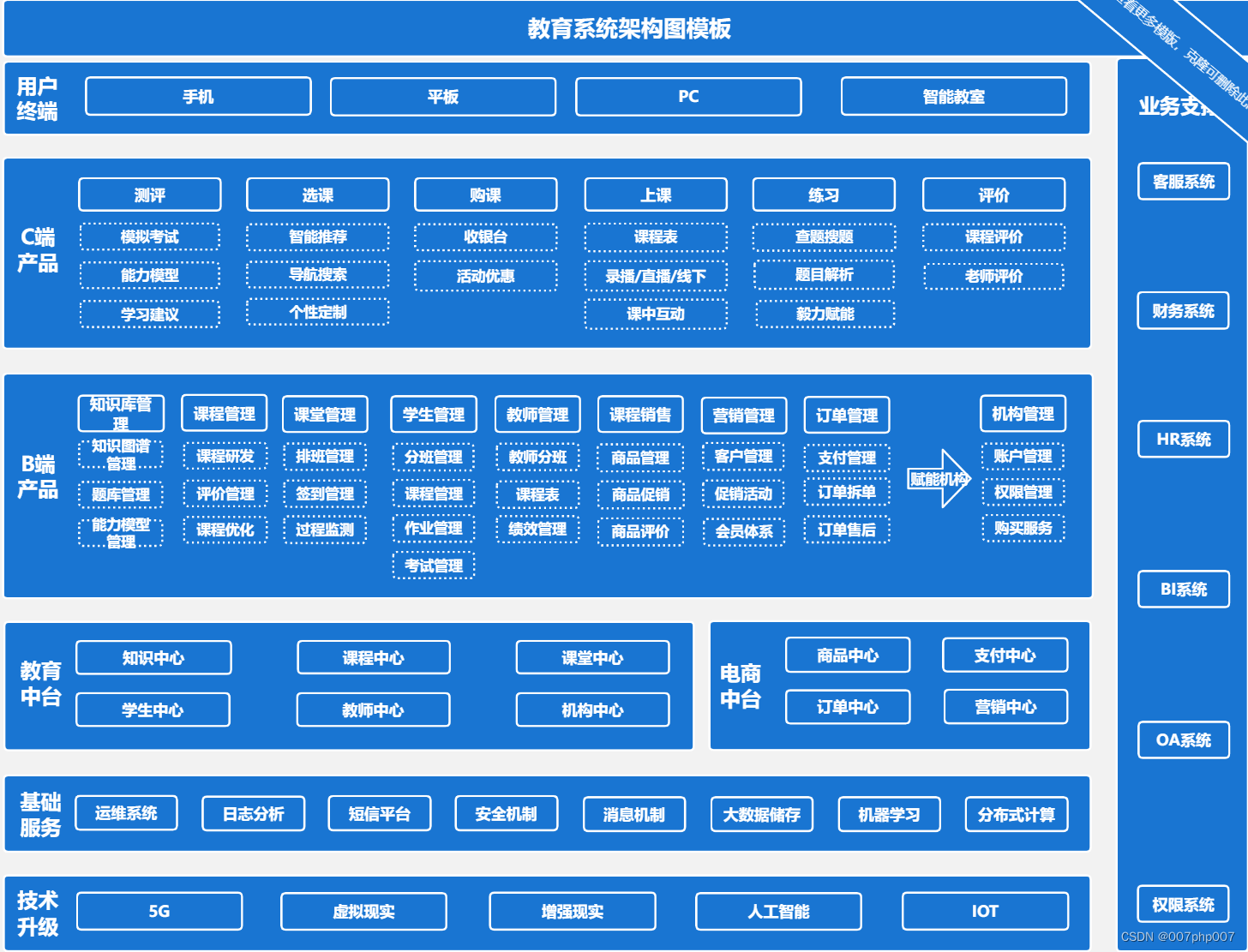
数字化运营在教育行业的技术架构实践总结
随着科技的不断进步和数字化时代的到来,教育行业也正面临着数字化转型的挑战和机遇。教育行业的数字化运营需要依靠合理的技术架构来支撑,本文将探讨教育行业数字化运营的技术架构设计。
## 第一步:需求分析和架构设计
在构建教育行业数字化…

LLM 构建Data Muti-Agents 赋能数据分析平台的实践之①:数据采集
一、 概述
在推进产业数字化的过程中,数据作为最重要的资源是优化产业管控过程和提升产业数字化水平的基础一环,如何实现数据采集工作的便利化、高效化、智能化是降低数据分析体系运转成本以及推动数据价值挖掘体系的基础手段。随着数字化在产业端的推进…
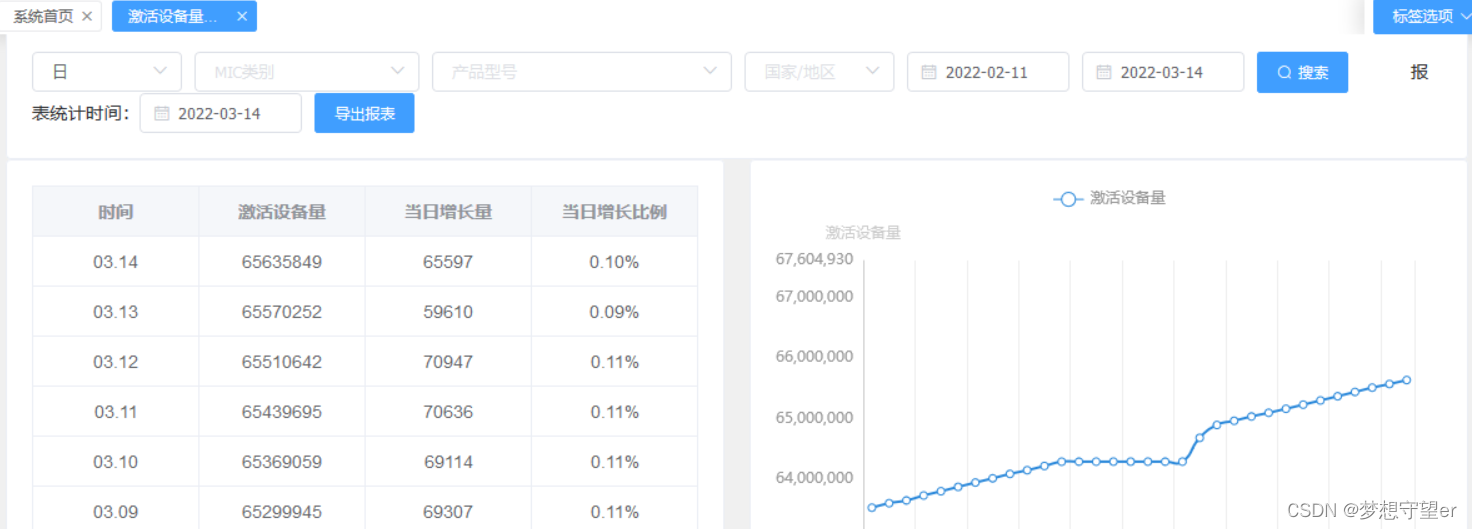
基于Kylin的数据统计分析平台架构设计与实现
目录
1 前言
2 关键模块
2.1 数据仓库的搭建
2.2 ETL
2.3 Kylin数据分析系统
2.4 数据可视化系统
2.5 报表模块
3 最终成果
4 遇到问题 1 前言 这是在TP-LINK公司云平台部门做的一个项目,总体包括云上数据统计平台的架构设计和组件开发,在此只做…
数据采集项目之业务数据(三)
1. Maxwell框架
开发公司为Zendesk公司开源,用java编写的MySQL变更数据抓取软件。内部是通过监控MySQL的Binlog日志,并将变更数据以JSON格式发送到Kafka等流处理平台。
1.1 MySQL主从复制
主机每次变更数据都会生成对应的Binlog日志,从机可…
驾校倒闭了这么多,凭什么我能活下来,因为有云表利剑
因为部门场地比较分散,学员名单都是通过wps传递,但是某个部门更新学员信息时,其他部门无法实时共享更新,导致其他部门无法掌握学员最新信息,为学员提供制定服务。用了云表后学员只需在一个部门办一次业务,其…
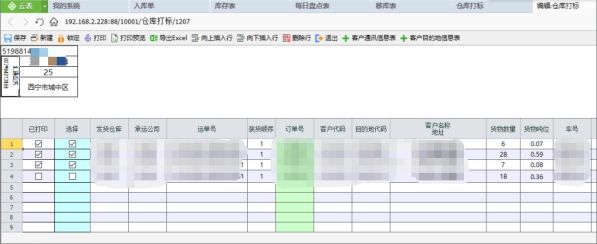
想做WMS仓库管理系统,找了好久才找到云表
公司内部仓库管理原方式均基于人工电子表格管理方式来实现收发存管理,没有流程化管理,无法保证数据的准确性和及时性,同时现场操作和数据核对会出现不同步的情况,无法提高仓库的运作效率,因此,我们基于云表…

数字化转型导师坚鹏:金融机构数字化运营
金融机构数字化运营 课程背景:
很多金融机构存在以下问题:
不清楚数字化运营对金融机构发展有什么影响?
不知道如何提升金融机构数字化运营能力?
不知道金融机构如何开展数字化运营工作?
课程特色:…
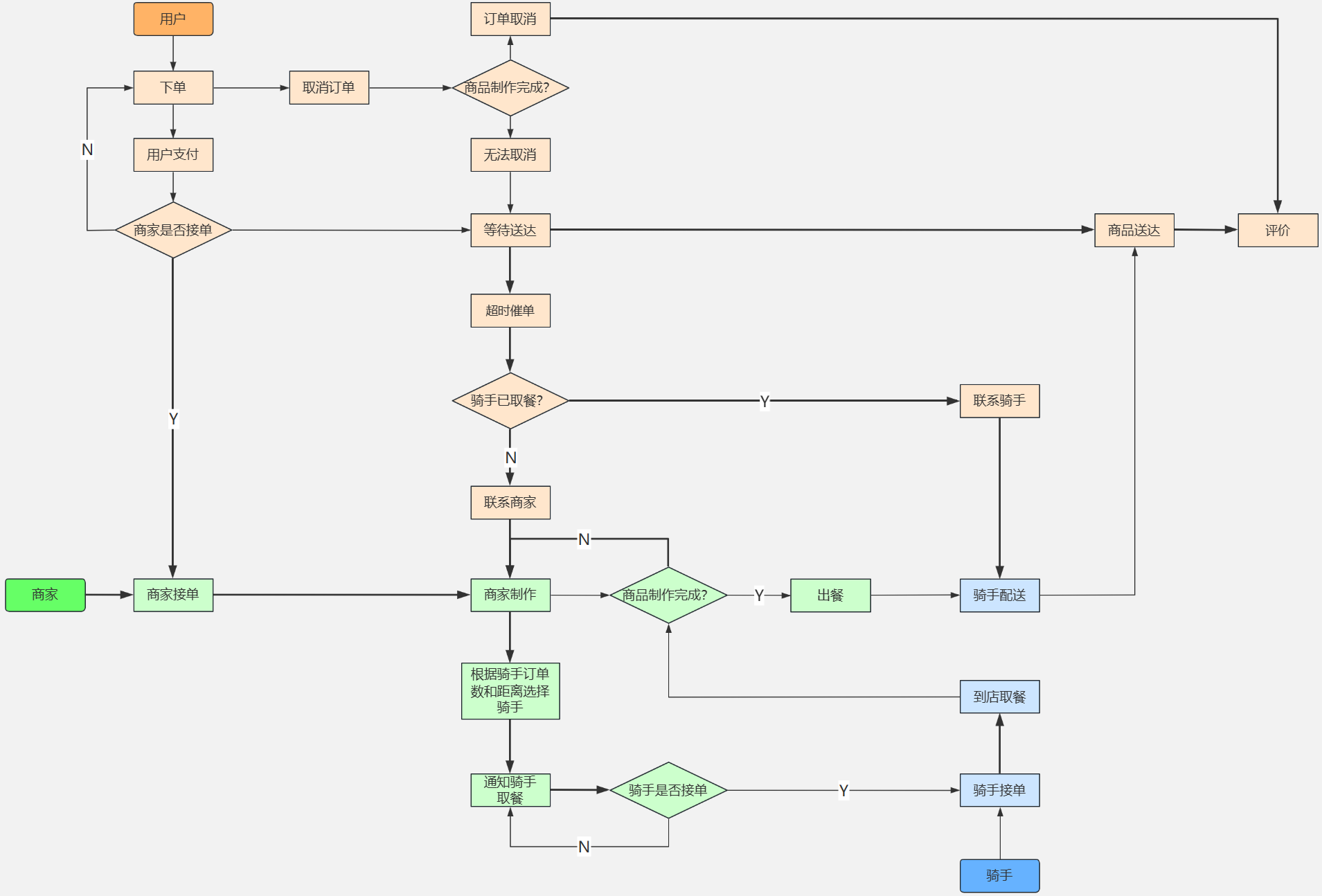
外卖平台订餐流程架构的实践
当我们想要在外卖平台上订餐时,背后其实涉及到复杂的技术架构和流程设计。本文将就外卖平台订餐流程的架构进行介绍,并探讨其中涉及的关键技术和流程。
## 第一步:用户端体验
用户通过手机应用或网页访问外卖平台,浏览菜单、选择…
风靡整个DOS时代的Pctools,现已不再,饱受争议的它,又能走多远
PCTOOLS,这个名字堪称一个时代的象征。
PCTOOLS 9.0
这款工具箱由美国Central Point公司精心打造,专为PC机量身设计,它的出现无疑让整个DOS时代为之疯狂。
或许,当你瞥见“PCTools For DOS”这个熟悉的名字时,心中会…

跟着 Tubi 同事吃遍全世界
在过去的一年里,Tubi 北京办公室的 Pantry 非常忙,忙于接收 Tubi 同事从全球各地带回的美食。而我们也有幸跟随慷慨的同事们尝遍了大江南北的味道。
细数这 30 多次美食分享,我们发现,大家分享的不仅是食物,还是…… …

【Flink 问题集】The generic type parameters of ‘Collector‘ are missing
错误展示: Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function main(CollectionDemo.java:33) could not be determined automatically, due to type erasure. You can give type in…
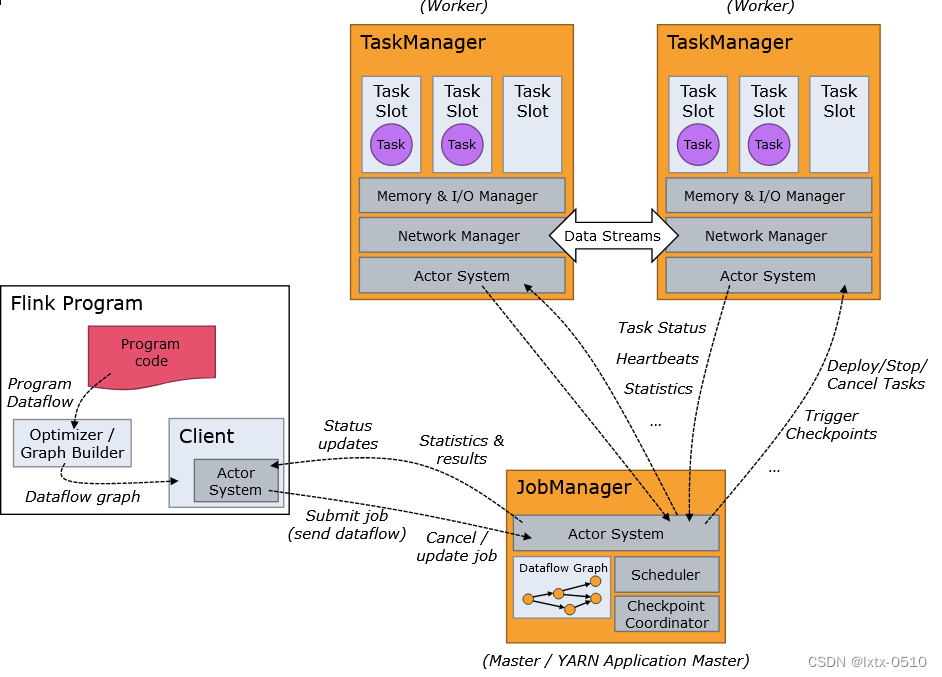
【Flink】系统架构
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task…

数字化转型导师坚鹏:数字化时代银行网点厅堂营销5大特点分析
数字化时代银行网点厅堂营销存在以下5大特点:
1、产品多样化:在数字化时代,银行的产品和服务变得更加多样化。除了传统的存款、贷款、理财等金融服务外,还新增了各种创新产品,如网上银行、移动支付、投资咨询、保险、…
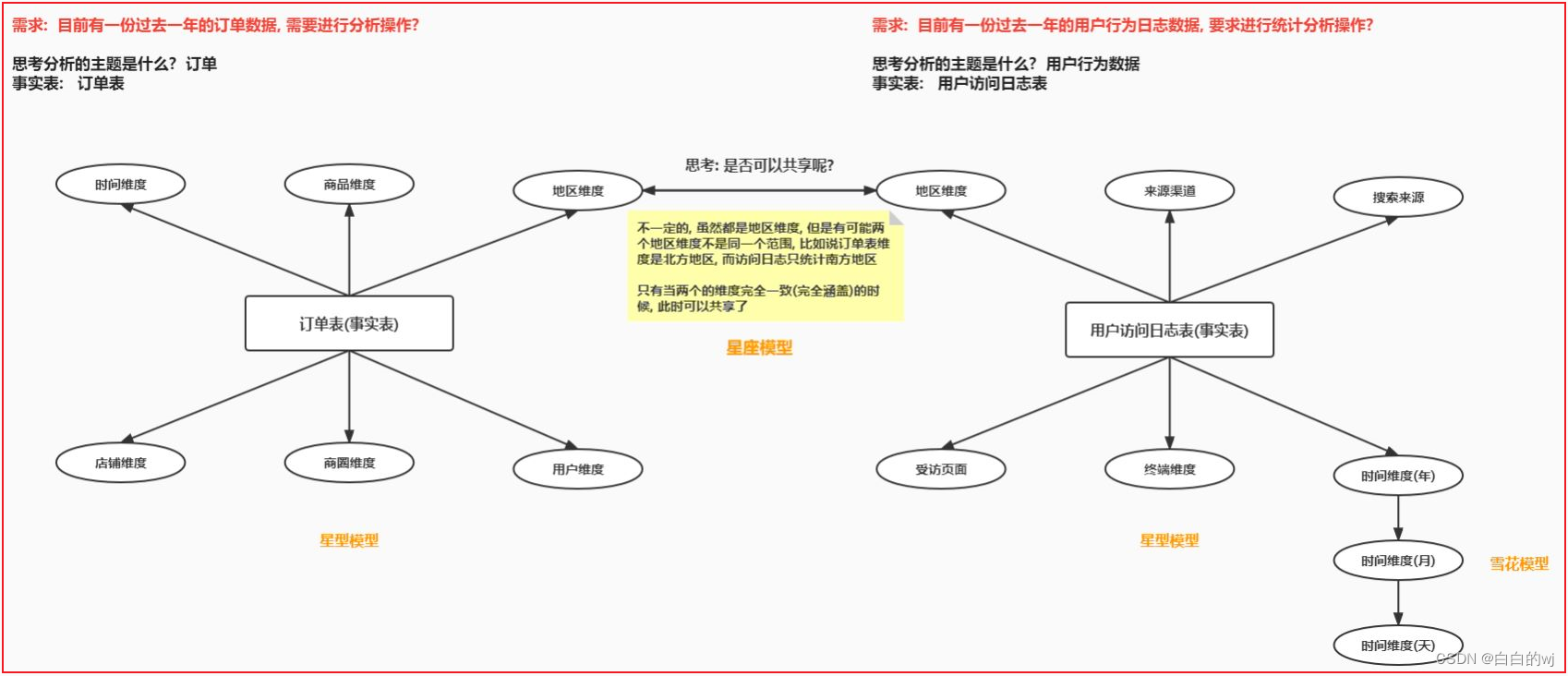
2023.11.22 数据仓库2-维度建模
目录 1.数仓建设方案
2.数仓结构图,项目架构图
2.1项目架构图 2.2数仓结构图 3.建模设计
4.维度建模 什么是事实表: 什么是维度表: 数据发展模式y以及对应的模型
5.数仓建设规范
数据库划分规范
表命名规范
表字段类型规范 1.数仓建设方案 ODS: 源数据层(临时存储层) 贴…

PySpark中DataFrame的join操作
内容导航
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统…
Hadoop_API文件下载文件删除文件移动、更名
1、完整代码
package com.atguigu.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
…
集群模式的kafka部署
Kafka集群模式deploy 解压安装
tar -xzf kafka_2.13-2.8.0.tgz -C /opt
cd /opt/
mv kafka_2.13-2.8.0 kafka
cd kafka
mkdir logs
cd config
vim server.properties添加相关参数
broker.id 唯一idlog.dirs 日志目录zookeeper.connect 使用外部zookeeper
#broker 的全局唯一…

rdd算子之cogroup
coGroup及其应用cogroupintersectionleftOuterJoin, rightOuterJoin, fullOuterJoin, joincogroup
cogroup也能组合RDD。
例子:
object CogroupOperator {def main(args: Array[String]): Unit {val sparkConf: SparkConf new SparkConf().setAppName(this.get…
《ThinkPHP 5实战》4个实战开发案例可从代码仓库下载
《ThinkPHP 5实战》本书带有4个实战开发案例,非常有参考价值。 本书分为18章,内容包括开发环境搭建、配置系统、路由、控制器、数据库操作层、模型层、视图、验证器、缓存、Session和Cookie、命令行应用、开发调试、服务器部署、数据库设计、多人博客系统…
Live800:智能客服有哪些优势?
随着科技的发展,智能客服逐渐走入大众视野,越来越多的企业开始使用智能客服,那么智能客服的优势有哪些? 智能客服是什么?
来自百度百科的释义:智能客服是在大规模知识处理基础上发展起来的一项面向行业应用…
伙伴赋能 | 如何快速交付优质的对话式AI?这些课程给你答案
为帮助合作伙伴轻松高效的完成智能客服的交付部署工作,百度智能云合作伙伴赋能平台全新上架智能对话平台UNIT(企业版)和智能客服语音服务交付方向的系列课程。
智能对话平台UNIT(企业版)是一款为解决企业中重复繁杂的…
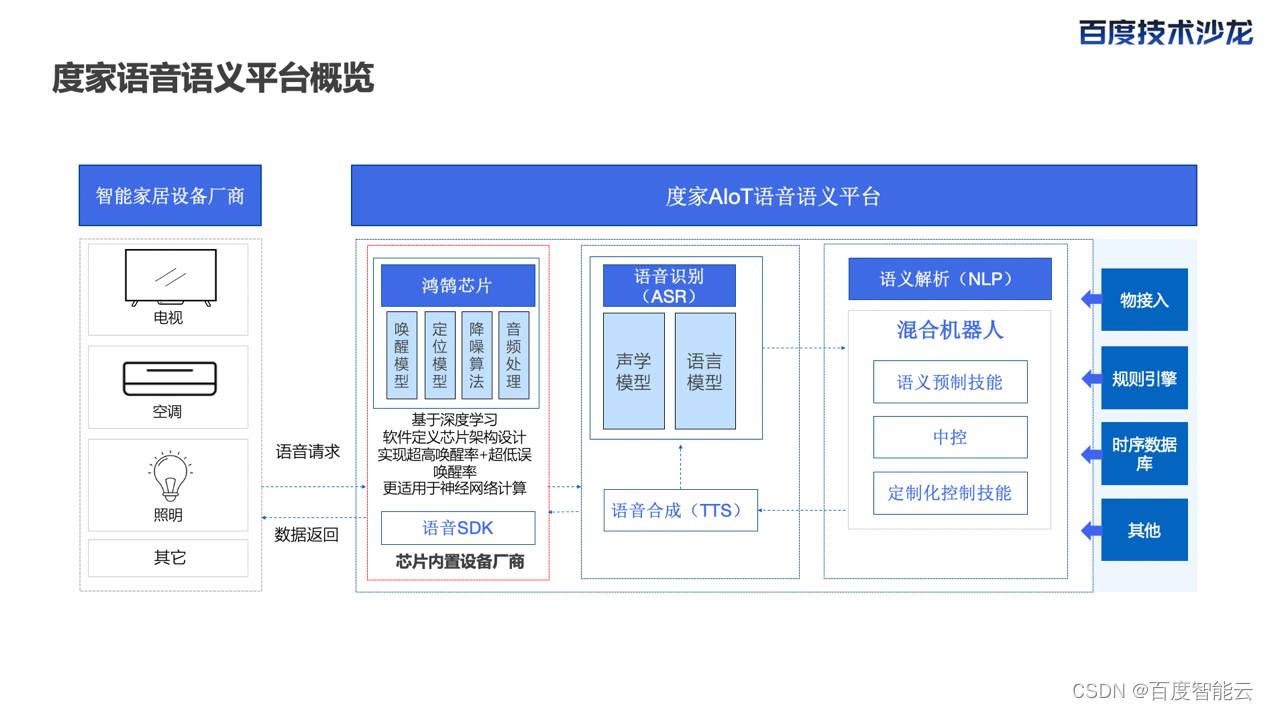
从理论到实战,带你全面解读智能物联网技术
作为连接物、人和信息资源的智能系统,物联网实现了对物理和虚拟世界信息的处理,伴随着5G 技术的成熟,物联网正在快速发展并渗透到我们衣食住行的各个方面,给我们的生活带来智能和便捷。
为了帮助更多开发者朋友了解与智能物联网有…
JDBC--连接JVM和数据库的接口
一、概述
1、JDBC 全称:java dataBase Connectivity java语言连接数据库 JDBC实质是一个接口, 用来连接JVM和数据库的接口(SUN公司制定的一套接口)
2、作用 将数据库与JVM建立连接,利用java语句动态操作数据库 而不是用sql本身…
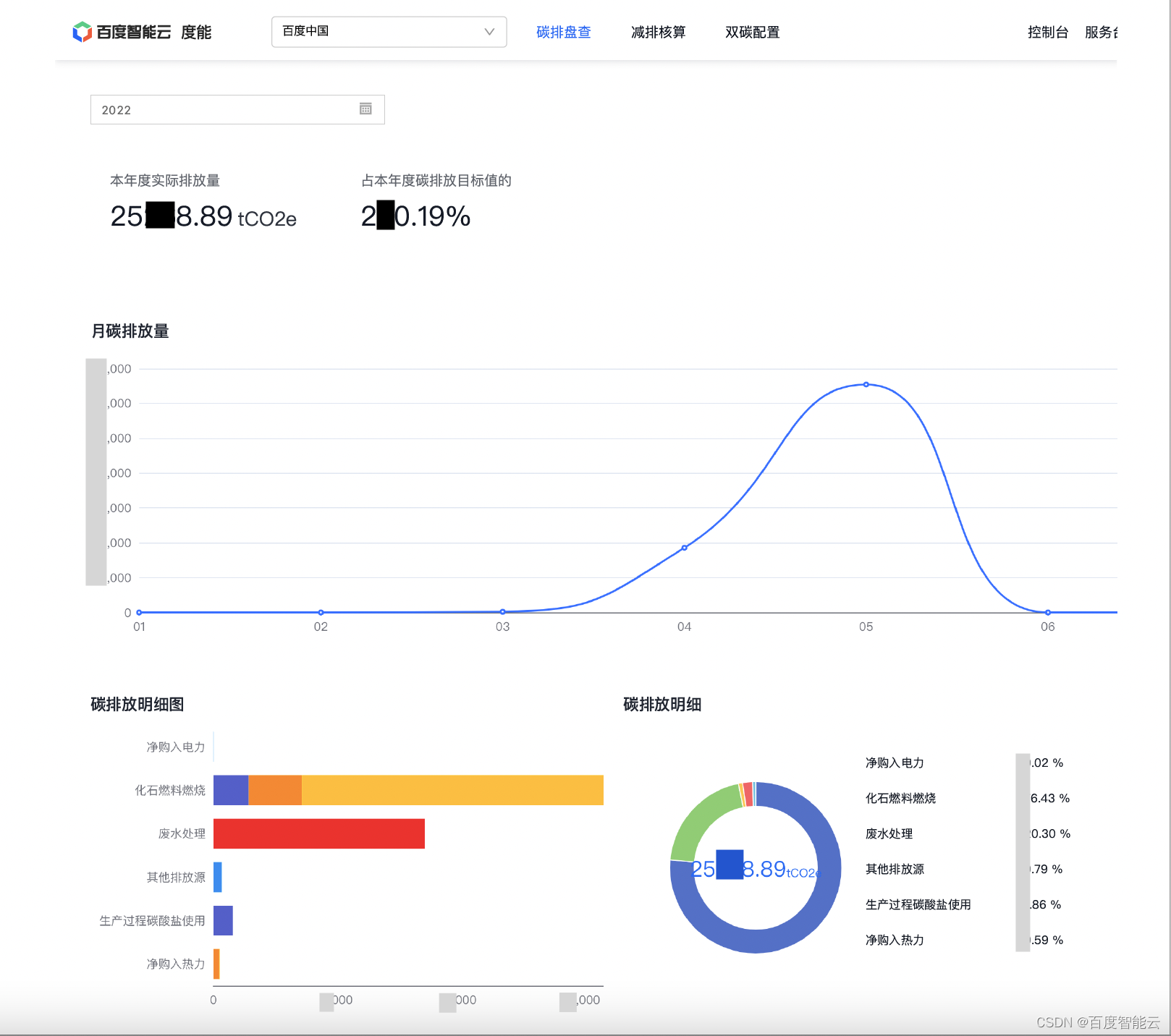
碳盘查功能全新上线,百度智能云度能助力企业园区零门槛搭建碳盘查方案
今年1月,国务院发布《“十四五”节能减排综合工作方案的通知》,方案提出到2025年,全国单位国内生产总值能源消耗比2020年下降13.5%,能源消费总量得到合理控制。百度也积极履行科技企业减碳责任,于2021年正式公布到2030…

大数据可能是一场骗局
编者按:本文作者冯大辉,丁香园CTO,雷锋网特约撰稿人,想要联系的读者可以在微波Fenng。 几乎每天都能看到有人在谈论大数据,让人好生厌烦。什么是大数据(Big Data) ? 简单一点可以理解为超出传统数据管理工具处理能力的…

实在智能与光云科技战略合作,强强联手推进电商数智化转型
11月22日,杭州实在智能科技有限公司(简称“实在智能”)与杭州光云科技股份有限公司(股票代码:688365,简称“光云科技”)签署战略合作协议。实在智能创始人兼CEO孙林君、联合创始人兼CMO张俊九&a…

【Flink学习】入门教程之概览
文章目录概览整套教程的目标与覆盖范围基础概念Stream Processing 流处理Parallel Dataflows 并行DataflowsTimely Stream Processing 自定义时间流处理Stateful Stream Processing 有状态流处理Fault Tolerance via State Snapshots 通过状态快照实现的容错概览
官网文章地址…
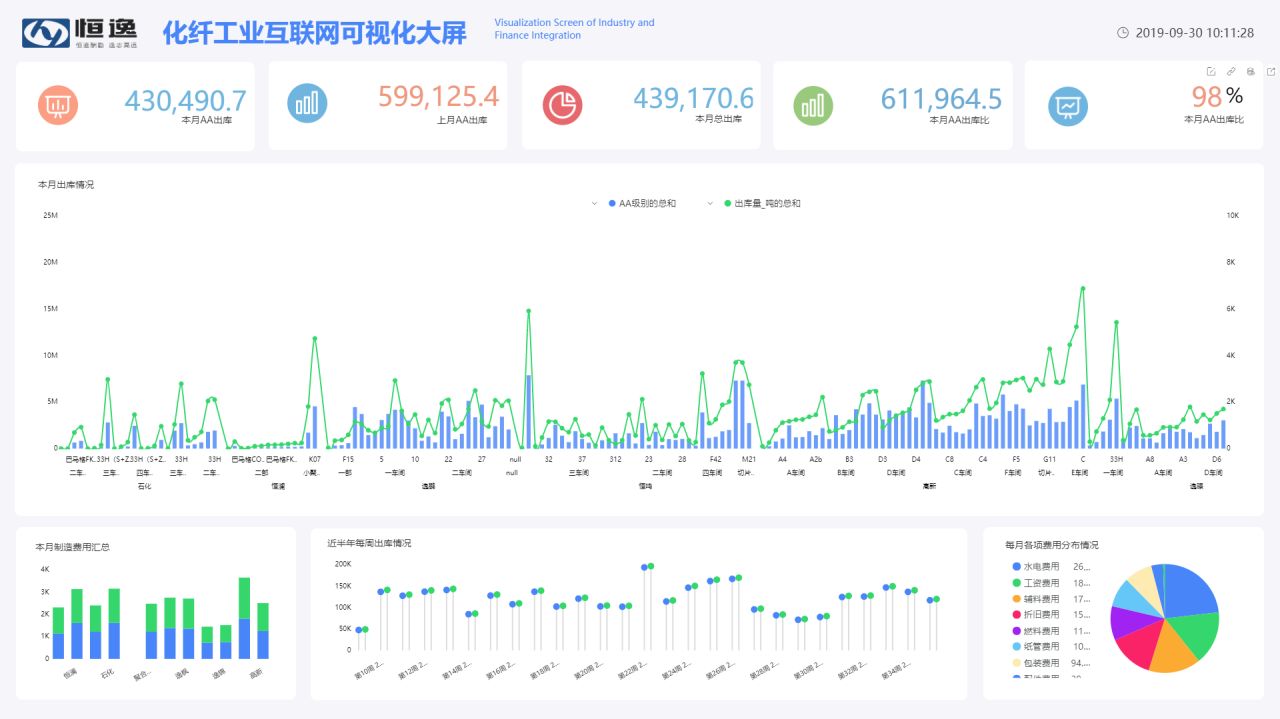
再见,Visual Basic——曾经风靡一时的编程语言
2020年3月,微软团队宣布了对Visual Basic(VB)的“终审判决”:不再进行开发或增加新功能。这意味着曾经风光无限的VB正式退出了历史舞台。
VB是微软推出的首款可视化编程软件,自1991年问世以来,便受到了广大…
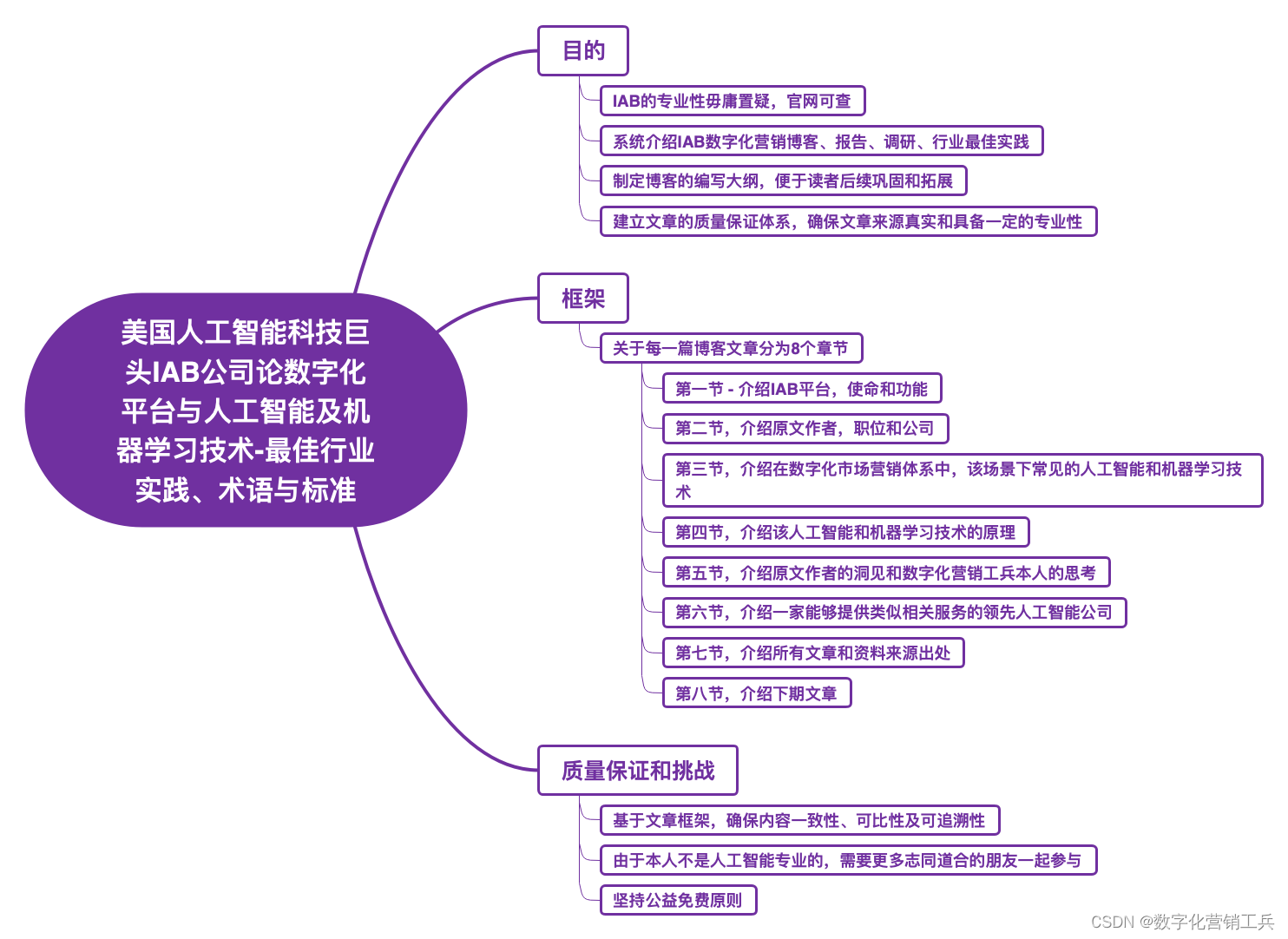
第八篇:预测受众(Predictive audience)技术是如何赋能数字化营销生态的?- 我为什么要翻译介绍美国人工智能科技巨头IAB公司
IAB平台,使命和功能
IAB成立于1996年,总部位于纽约市。
作为美国的人工智能科技巨头社会媒体和营销专业平台公司,互动广告局(IAB- the Interactive Advertising Bureau)自1996年成立以来,先后为700多家媒…


智数融合|低代码入局,推动工业数字化转型走"深"向"实"
当下,“数字化、智能化”已经不再是新鲜词汇。事实上,早在几年前,就有企业开始大力推动数字化转型,并持续进行了一段时间。一些业内人士甚至认为,“如今的企业数字化已经走过了成熟期,进入了深水区。” 但事…
Eureka心跳机制与自动保护机制原理分析
Eureka心跳机制:
在应用启动后,节点们将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
Eureka自动保护机制&am…
Hive cube / rollup / grouping sets/GROUPING__ID用法详解
Hive CUBE / ROLLUP / GROUPING SETS / GROUPING__ID用法详解GROUPING SETSGROUPING__ID(注意这里是两个下划线)CUBEROLLUPcube / rollup / grouping sets/GROUPING__ID,经常会被问到这几个函数的区别,今天就好好整理一下。GROUPI…

收购艾瑞咨询,亚信科技如何释放1+1>2的发展效应?
任何企业的发展,成功的秘诀少不了战略坚持的定力,以及稳中求进的创新。
自2019年底亚信科技正式发布“一巩固、三发展”的整体战略后,便开启了业务转型的进程。在过去两年左右的时间里,稳固运营商市场BSS业务的同时,亚…

Spark基础之:集群角色以及任务提交流程
Spark集群角色以及任务提交流程一、Spark主要角色介绍1、Spark主要角色MasterWorkerDriverExecutor2、yarn主要角色资源管理层面任务计算层面二、Spark提交任务流程1、Spark On Standalone2、Spark On Yarnclient模式cluster模式2、Spark On Yarn原理本篇主要介绍两块内容&…
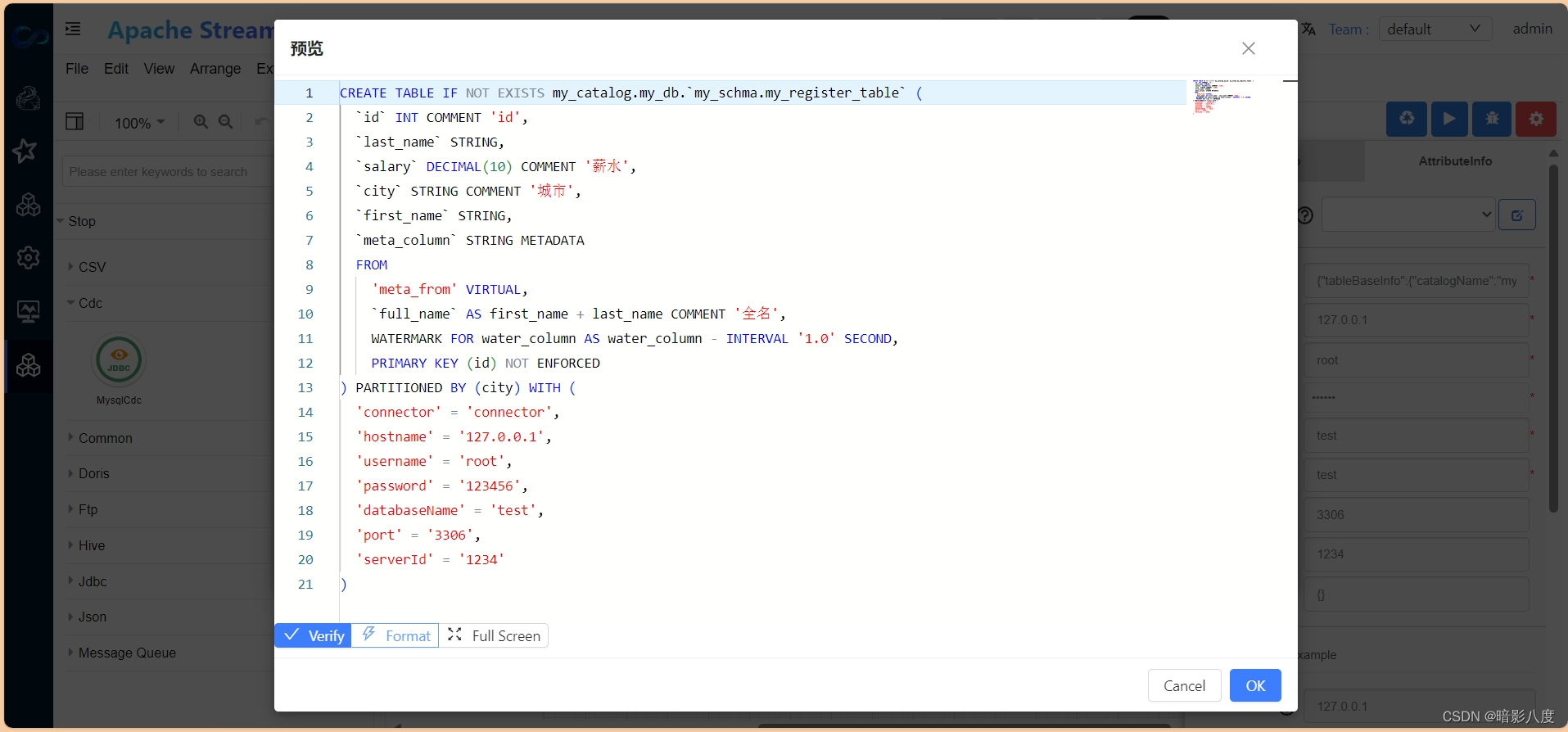
PiflowX如何快速开发flink程序
PiflowX如何快速开发flink程序
参考资料
Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com)
Flink SQL 背景
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标…
Hive参数调整详细
--压缩配置:
-- map/reduce 输出压缩(一般采用序列化文件存储)
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK;--任务中间压缩
set hive.exec.compress.i…
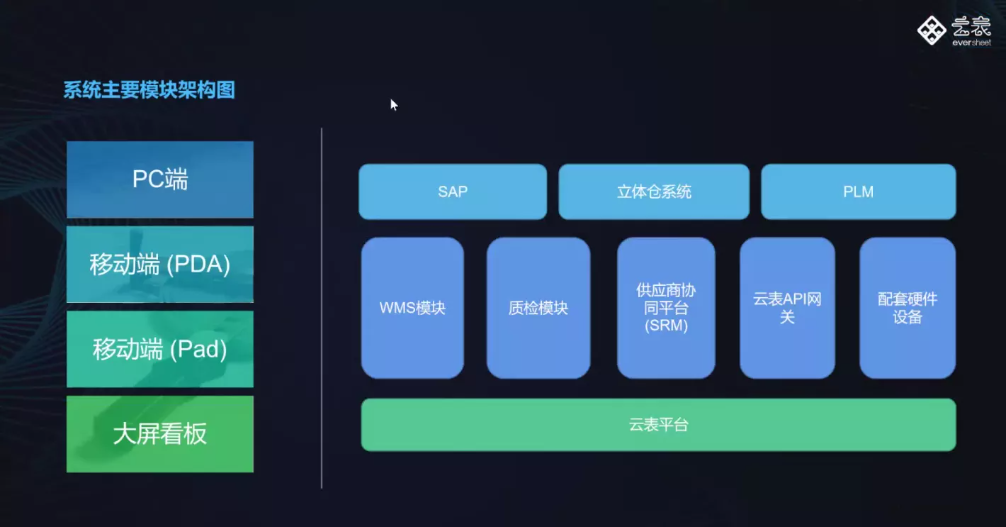
懂这3件事情,就能成功实施MES管理系统实现“数字化”工厂
当前,很多企业对MES管理系统需求旺盛,但是,要保证MES管理系统能够有效地实施,实现精益化管理,打造出一个“数字化”工厂,公司在实施MES管理系统之前,还必须弄明白为什么要MES管理系统、MES有什么…
2021年氧化工艺报名考试及氧化工艺新版试题
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:氧化工艺报名考试是安全生产模拟考试一点通总题库中生成的一套氧化工艺新版试题,安全生产模拟考试一点通上氧化工艺作业手机同步练习。2021年氧化工艺报名考试及氧化工…
(二)常用Shuffle类算子:groupByKey、reduceByKey、aggregateByKey 和 sortByKey
在数据分析场景中,典型的计算类型分别是分组、聚合和排序。而 groupByKey、reduceByKey、aggregateByKey 和 sortByKey 这些算子的功能,恰恰就是用来实现分组、聚合和排序的计算逻辑。 这些算子看上去相比其他算子的适用范围更窄,也就是它们只能作用(Apply)在 Paired RDD …
⑧RDD,DataFrame,DataSet对比
RDD困境 map、filter,它们都需要一个辅助函数 f 来作为形参,通过调用 map(f)、filter(f) 才能完成计算。以 map 为例,我们需要函数 f 来明确对哪些字段做映射,以什么规则映射。filter 也一样,我们需要函数 f 来指明以什么条件在哪些字段上过滤。这样一来,Spark 只知道开发…

21:Spark+Kafka
结合实例,说一说 Spark 与 Kafka 这对“万金油”组合如何使用。随着业务飞速发展,各家公司的集群规模都是有增无减。在集群规模暴涨的情况下,资源利用率逐渐成为大家越来越关注的焦点。毕竟,不管是自建的 Data center,还是公有云,每台机器都是真金白银的投入。
实例:资…
面经|我的面试记录加油丫
阿里-数据研发实习(一挂)
(2021.4.21,一面,差不多一个小时)
1、自我介绍
2、你理解中的数据研发是怎样的?为什么想要做数据研发?(岗位理解吧)
3、介绍一个…

低/无代码赋能企业,IT与业务的角色正在悄然改变
现在这个社会,年轻人的压力是真的大,需要会的技能多到数不清。想学习多点技能也不知道去哪学,主要是网络资源太丰富,很难找到一个适合自己的。那接下来推荐4个大神级别的资源网站你可一定得码住,都是年轻人特别 …

了解 Spark中的master、worker和Driver、Executor
master和worker是物理节点,是在不同环境部署模式下和资源相关的两大内容 Driver和executor是进程,是在spark应用中和计算相关的两大内容
1、master和worker节点 master节点常驻master守护进程,负责管理worker节点,并且会从master…
人工智能注入城市,可统盘城市各方信息的联动学习
城市作为国家发展的主要载体,被放在更加重要的位置,城市数字化转型是发展数字经济的时代选择;“城市是生命体、有机体”,打造城市的“眼(感知)、脑(中枢)、手(应用)、脉(网络)、血液(数据)”,让城市像人一样有新陈代谢、生长发育的更替演进,有应激性、自适应的调节反应;通过共筑…
Al+行业正在聚焦多元化的应用场景 为人工智能发展提供巨大空间
人工智能专用芯片与智能传感器的发展,大幅提高了端侧设备的计算资源容量。同时,模型压缩后的人工智能算法支持轻量化和低成本化部署。 终端设备开始内置嵌入深度学习算法,可以对采集的数据进行实时处理实时应用。边缘层作为智能终端最近的…
Flink1.10.1编译hadoop2.7.2 编译flink-shaded-hadoop-2-uber
从Flink 1.11开始,flink-shaded-hadoop-2-uberFlink项目不再正式支持使用发行版。 如果想建立flink-shaded对供应商特定的Hadoop版本,您必须首先描述配置特定供应商的Maven仓库在本地Maven安装在这里。 这是已经编译好的flink-shaded-hadoop-2-uber-2.7.…
Centos7 单机安装 kafka 0.11.0.1
一 安装 jdk 1 安装 jdk ,这里选择 openjdk 1.8
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
安装后的jre和jdk在 /usr/lib/jvm/ 里,本例中具体的文件夹是java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64,注意这里的版本…

嚣张|微软“光明正大”要数据,Access用户怎么办?WPS笑了
微软“光明正大”要数据
继微软“数据门”事件之后,微软又开始出“幺蛾子”了。
最近,电脑是windows11会提示:你的数据将在所在国家或地区之外进行处理。最让用户感到霸道的是,竟然没有“跳过”按钮。只能点击继续,否则…

一文带你了解HBase读取数据详细流程
HBase数据读取流程
1、hbase数据读取流程简单描述
一般来说,在描述hbase读取流程的时候,简单的描述如下:
1)、客户端从zookeeper中获取meta表所在的regionserver节点信息
2)、客户端访问meta表所在的regionserver节点࿰…
如何找到真正的问题?
如何找到真正的问题? ID:AcmeCore单爆营 问题是什么?
“问题”是指:有意识地寻求某一适当的行动,以便达到一个被清楚意识到但又不能立即达到的目的。也有学者对问题给出的定义是“实际状态和期望状态之间的差距”。
…
hadoop 大数据笔记
1、问题1 localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-na menode-ubuntu-1.out
hadooplocalhosts password:
localhost: Connection closed by …

实时数仓分层之DWM存在的意义
采集层,就是ODS(原始数据)层DWD层,离线数仓中在这一层当中分为了两块内容,一个是DWD,还有一个叫DIM,主要是针对于这个业务数据而言的,那如果说行为数据很简单,就都是DWD&…

Phoenix踩坑记录(包括phoenix连接HBase一直卡住)
1.第一个坑
Exception in thread “main” java.lang.NoSuchMethodError: com.ctc.wstx.stax.WstxInputFactory.createSR(Lcom/ctc/wstx/api/ReaderConfig;Lcom/ctc/wstx/io/SystemId;Lcom/ctc/wstx/io/InputBootstrapper;ZZ)Lorg/codehaus/stax2/XMLStreamReader2;
踩坑过程…
宁德时代B站联手做PE,战投也要“手把手”?
开年最强私募,当这个称号落在宁德时代和B站联手发起的孚腾基金身上时,市场投资风向的细微变化被更多人感知到了。实际上,上海孚腾私募基金管理有限公司这个名字的背后,还有上海国投资本、上汽集团全资子公司上汽金控、博裕资本旗下…

华人运通高端车销量难及蔚小理,处在第二梯队何时能加速上位?
2021年对于新能源汽车行业来说是突飞猛进的一年。根据乘联会数据,国内各大新能源汽车品牌共计销售了352.1万辆车,同比增长1.6倍。除了“蔚小理”三巨头持续发力外,众多新势力也整装待发。
此前就有媒体报道,合众新能源汽车考虑通…

NewLink能链IPO,能源物联网的先行者?
今年以来,有大量公司赴港上市。近日,一家为能源行业提供数字化服务的内地公司也传来考虑香港上市的消息。
港股研究社获悉,来自内地的能源产业物联网公司能链(Newlink)考虑来香港上市,计划募资3亿至4亿美元,据说能链目…
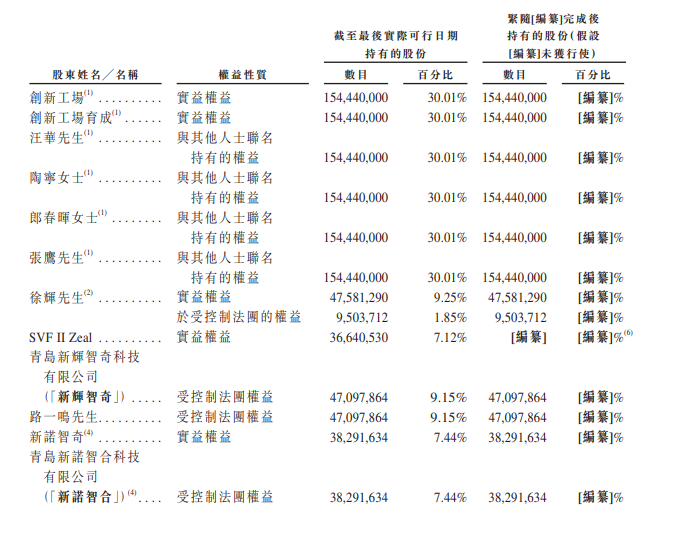
二次闯关港交所,创新奇智能否成为国内AI+制造第一股?
1月3日晚间,青岛创新奇智科技集团股份有限公司(简称“创新奇智”)向港交所递交招股书,拟在香港主板上市。据了解,这是继2021年6月25日递表失效后,创新奇智的第二次申请,其招股书显示,…
离线数仓中的同步策略、Flume、Kafka
离线数仓当中Sqoop采集MySQL中数据同步策略有:增量全量新增及变化特殊;Sqoop怎么处理? where判断日期:新增:where 创建时间 当天;全量:where 1 1;新增及变化:创建时间 …

P2 数据库系统概论——数据技术的产生和发展
文章目录什么是数据管理数据管理技术的发展过程数据管理三个阶段比较应用程序与数据的对应关系人工管理阶段(一一对应)文件系统阶段数据库系统阶段数据库系统的特点数据结构化数据的共享性高,冗余度低且易扩充数据独立性高数据有数据管理系统…
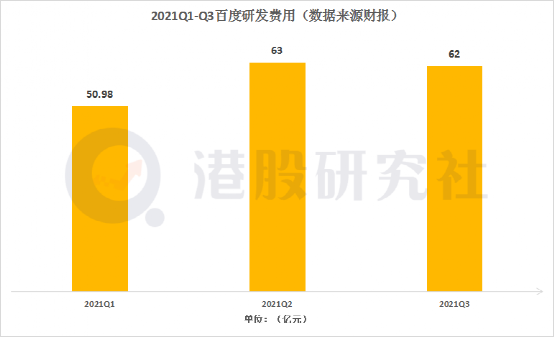
百度Q3新财报:智能云从颠覆性创新到超越式进化
埃德蒙伯克说过:“骑士时代已经过去,随之而来的是智者、经济学家和计算机专家的时代。”
智能化时代,可以说是属于那些拥有先进科技的大厂的时代。
若要在现阶段的国内找到一个将智能化故事说得不错的企业,笔者认为,…
大数据技术的一些题目
1. kafka相关
1.1 怎么解决kafka的数据丢失 producer端: 宏观上看保证数据的可靠安全性,肯定是依据分区数做好数据备份,设立副本数。 broker端: topic设置多分区,分区自适应所在机器,为了让各分区均匀分布在所在的broker中,分区数要大于broker数。 分区是kafka进行并行读…
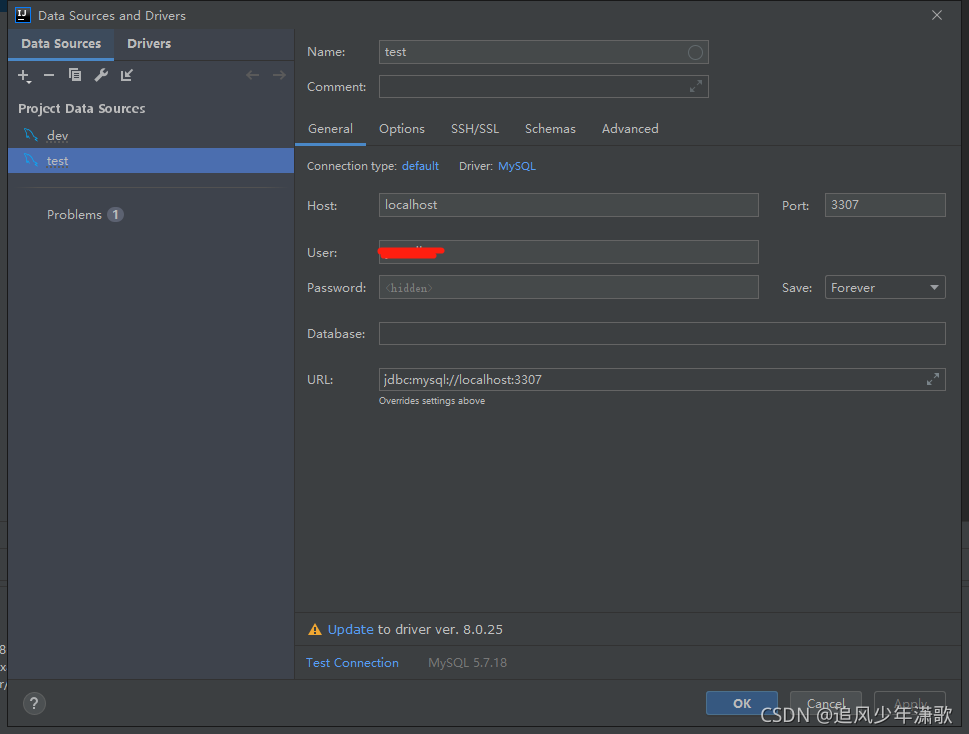
教你一招让Idea搭配上Xshell连接远程服务器端数据库(内网地址连接),再也不用在命令行输入繁琐的指令操作~~~
因为公司服务器端数据库提供的是内网地址,远程连接无法直接通过内网地址进行连接,只能在命令行输入mycli -h 内网地址命令进行访问。 现在提供一种简易的方式去连接服务器端的数据库内网地址
侦听端口是你本地自定义的端口号,如3307 而3306…
“鲸置”入场,一场C2C的较量,闲鱼慌了吗?
从古代的当铺到如今的闲鱼、转转都反映着二手交易的存在。
“去年的衣服配不上今年的我”“衣服到用时方恨少,但是整理起来一大堆”也是现在很多年轻人的真实写照。在大众购物欲增加的同时,许多物品被挤压在箱底。“左手新品消费,右手旧物出…

营收增长亏损收窄,国美重回巅峰之路走到了哪一步?
近日,国美对外发布了截至2021年6月30日的中期业绩报告。
财报显示,期内,国美营收实现同比增长,与此同时,亏损也在进一步收窄。
回头来看,十二年前,国美可以说是业内的龙头企业,掌握…
2021-09-282021年起重机械安全管理试题及解析及起重机械安全管理操作证考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:2021年起重机械安全管理试题及解析为正在备考起重机械安全管理操作证的学员准备的理论考试专题,每个月更新的起重机械安全管理操作证考试祝您顺利通过起重机械安全管理…
正式上架!TDengine 插件入驻 Grafana 官网
小 T 导读:为了更方便用户使用 TDengine Grafana 这个组合,在 TDengine 和 Grafana 两个团队的协作之下,TDengine 插件正式上架 Grafana 官网!一行命令即可完成安装配置。 Grafana 某种程度上已经成为当前最流行的图形化运维监控…

Live800|哪家在线客服系统性价比高?
性价比高的在线客服系统有哪些?如何选择在线客服系统最划算?是很多企业所关心的问题。 性价比高的在线客服系统有哪些?
影响在线客服系统价格的因素有很多如部署方式、智能化程度以及系统的功能、性能,因此显然性价比随企业的需求…
kakfa 3.0 创建topic流程(源码)
文章目录1、通过create命令到组装创建topic需要的数据流程(scala部分)2、创建一个客户端,此客户端通过队列多线程异步发送创建topic的请求(1)runnable.call(队列和多线程执行)(2)getCreateTopicsCall(创建发送创建topic的requestBuilder)3、服务端创建topic的请求(h…
yii框架数据库操作
查一条数据
$model new Merchant();
$merchant_id Yii::$app->request->get(merchant_id);
$data $model::find()->where([id>$merchant_id])->one();json转数组
Json::decode()数据库原生SQL
// 返回多行. 每行都是列名和值的关联数组.
// 如果该查询没有…
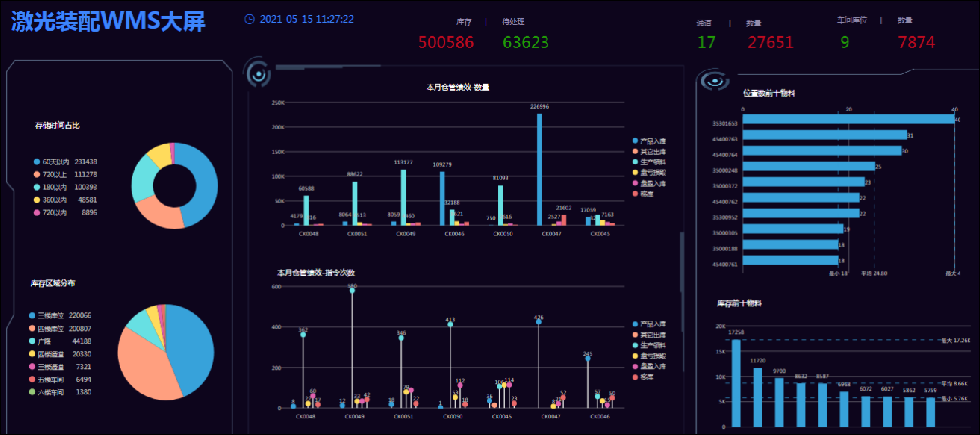
WMS仓库管理系统,你能操作明白吗?别让"智能"变"滞能"
随着社会的进步,智能车间、智能工厂等申报的展开,“智能化”的概念,让企业系统出现更迭。以智能化仓储管理系统为例,企业工厂利用WMS的优势,依照运行的工作标准和运算法则,对仓库进行精细化管理。 WM…
银行数字化转型导师坚鹏:兴业银行《天才与算法》读书拆解培训
兴业银行杭州分行《天才与算法》读书拆解培训圆满结束
兴业银行股份有限公司(简称“兴业银行”)成立于1988年8月,2022年总资产9.27万亿元,是经国务院、中国人民银行批准成立的首批股份制商业银行之一,总行设在福州市。…

MES系统智能工厂,搭上中国制造2025顺风车
MES在电子制造业中的应用日益广泛,越来越多的厂商已经购置或自行开发了MES,并将其作为“智能化工厂”。国内大大小小、各行各业都有上百个MES系统,还有很多的国外MES系统,怎么才能在MES系统公司中找到适合自己的MES?希…
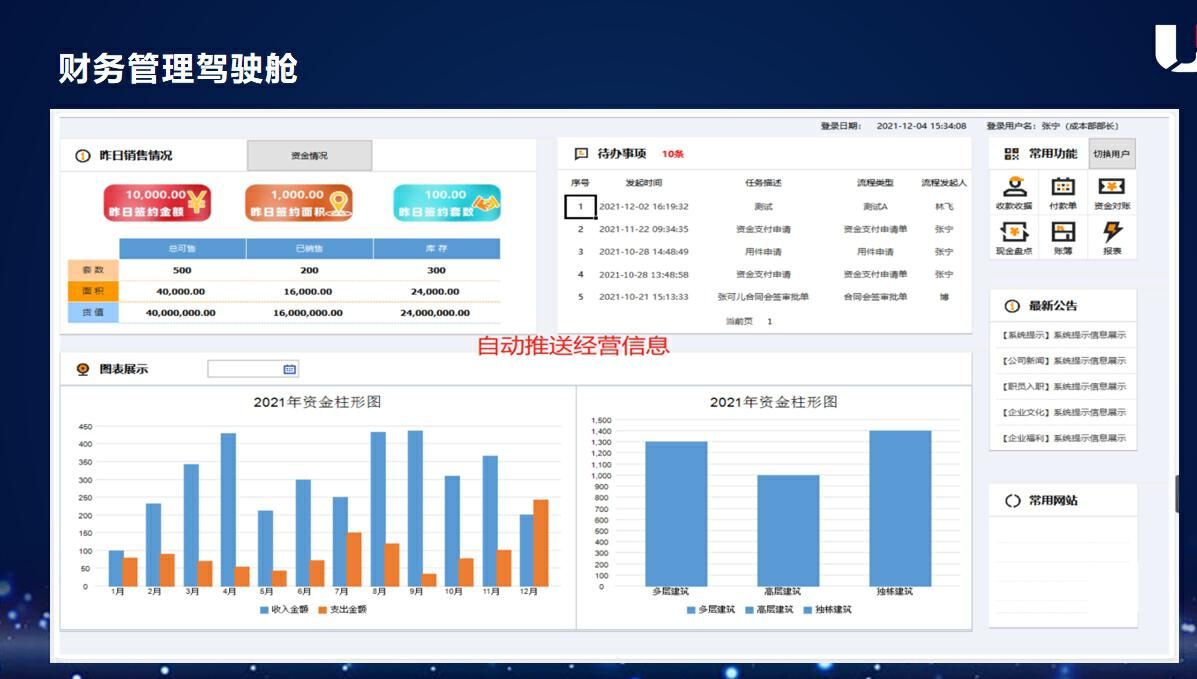
3款强大到离谱电脑软件,都是效率神器,从此远离加班
闲话少说,直接上狠货。
1、ImageGlass
ImageGlass是一款值得吹爆的电脑图片浏览工具,使用极其方便,体积50M左右,非常小巧,功能却强大到离谱,ImageGlass打开图片的速度极快,实现快速不同图像间切…

2:数据库的基本操作-MySQL
目录2.1 数据库的显示讲解2.2 创建数据库1. 创建数据库2. 创建带有关键字的数据库(不推荐)3.判断并创建一个不知道是否存在的数据库2.3 删除数据库1. 删除数据库2. 如果存在则删除数据库2.4 查看创建的数据库的SQL2.5 创建数据库指定字符编码以及查看字符…
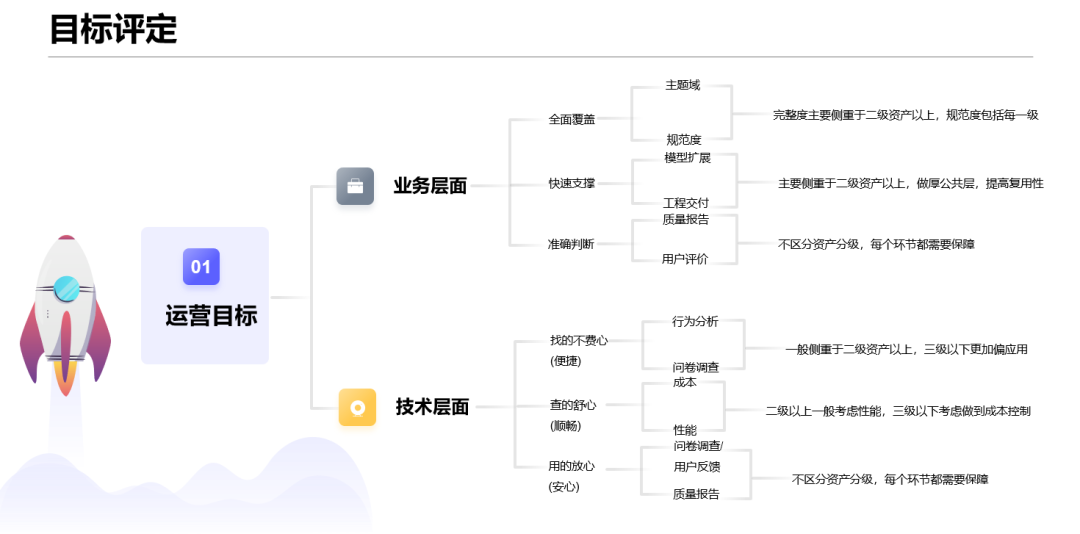
聊聊我对数仓建设的一些思考
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
目前大部分行业中的数仓建设大多是采用Kimball指导思想进行的,在初期发展阶段为了快速支撑业务,而且希望能让领导感受到数仓存在的价值从而带来更大…

我说2w字可以入门ES,非但不信还打我
感谢兄弟们的关注与支持,如果觉得有帮助的话,还请来个点赞、收藏、转发三操作
该文章已同步到语雀中,后台回复“语雀”可获取公众号:进击吧大数据整个职业生涯持续更新的所有资料
一、概述
Elasticsearch是一个基于Apache Luce…

0:数据库的产生-MySQL
目录0.1 什么是数据库 database0.2 抛出问题,数据库的产生0.3 数据库萌芽阶段的发展历程0.4 CRUD0.5 层次模型0.6 网状模型0.7 关系型数据库0.8 企业和我们都选什么数据库呢?0.1 什么是数据库 database
数据库是存放数据的仓库。它的存储空间很大&#…
智能化时代,物业管理何去何从?捷径智慧物业管理模式推陈出新
智能化时代,物业管理何去何从?捷径智慧物业管理模式推陈出新
21世纪,移动互联网从发展到逐渐成熟,已经开始影响人们生活中的方方面面。对于物业管理来说,跟随时代脚步及时转型已经成为不可阻挡的趋势。
近年来&#…
捷径智慧物业管理系统,全面覆盖了物业所面临的每一项痛点问题,让物业工作开展的更加顺利。-捷径智慧物业管理
业主与物业纠纷不断,捷径智慧物业系统化难题
在互联网技术革新的大浪潮中,小区物业服务公司想要在竞争愈加激烈的市场中保持出色的核心竞争力,需要从行业发展中的痛点问题着手,有针对性的对运营方式进行创新和改革。
如果物业公…
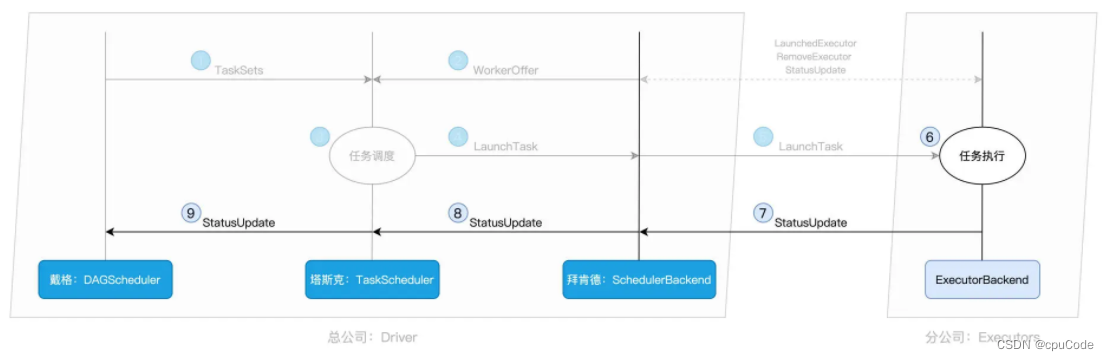
Spark 调度系统
调度系统的任务:先将 DAG 转为分布式任务,根据分布式集群资源的可用性,基于调度规则依序把分布式任务分发到执行器
Spark 调度系统的工作流程:
步骤作用核心组件所在进程1将 DAG (计算图) 拆成不同的远行阶段(Stages)根据 Stage…
利用基于云的人工智能平台,对设备进行预测性维护和产品的异常检测
在未来,人工智能几乎会影响到 IT 行业的每个方面,包括编程和开发。在过去的几年里,我们已经看到了诸如代码大师这样的工具,该产品会在开发者编程时,为其提供智能建议,以提高代码质量,并识别出应…
人工智能,就是人建造可替代人类心灵来进行工作的机器
历史上,每一次技术上的突飞猛进都会造成人类社会结构的巨大变革。人工智能的快速发展向人类展现了未来社会的多种可能性。然而,人工智能在给人类带来福祉的同时也在给社会带来现实的或者可能的“技术代价”。南京大学哲学系教授潘天群认为,面…

Spring的import注解解析及使用场景
一、导言 在spring框架下做开发时,会给容器中导入组件,通常我们给容器中注入组件的方式,可以通过Spring的xml配置方式,也可以通过注解,如Component等,也可以通过java配置类的方式给容器中导入,I…
4个封神的资源网站,颠覆你对免费白嫖的认知,干货奉上
想学习想提升但是总是不知道该去哪找资源,有些网站的资源都是付费才能继续观看。那只是你没找对资源网站罢了,下面给大家分享几个高质量的资源网站。内容丰富还免费,一定要偷偷使用哦~一、Oeasy
在新媒体时代,很多东西的制作都离不…

工业软件+无代码开发,国产软件崛起正当时
智能制造大势所趋,工业软件必不可少中国的制造业是一个低效率的行业,而智能化的制造业是推动其转型的关键。智能制造是以新一代信息技术与先进制造技术为基础,将其融入到了设计、生产、管理、服务等制造交互的每一个环节之中,并具…
可视化图表API格式要求有哪些?Sugar BI详细代码示例(2)
Sugar BI中的每个图表可以对应一个数据 API,用户浏览报表时,选定一定的过滤条件,点击「查询」按钮将会通过 API 拉取相应的数据;前面说过,为了确保用户数据的安全性,Sugar BI上的所有数据请求都在Sugar BI的…
捷径物业管理系统打造智慧社区,业主都说好-捷径系统
老旧小区改造新思路,捷径物业管理系统打造智慧社区,业主都说好-捷径系统
随着全国上下老旧小区改造如火如荼进行,社区发展迎来新机遇。
共享社区、社区团购等模式不断涌现,社区发展面临多样化、创新化、智慧化,如何把…

捷径晚年生活/养老方式大全110+城市旅居场景
辛苦了几十年,劳碌了一辈子,终于可以休息了。 在停下的这刻,才发现皱纹已经爬满了脸颊,手脚动作不再那么利落,一切变得慢了起来。 从出生到工作,从出差到旅游,走遍无数的城市,看过…

捷径智慧物业应该如何智慧服务于业主
从过去只知道收物业费的物业管理,随着时间的变化,随着社会智能化的进步,物业也革命了。
过去的监控安防、电梯、楼宇水电、停车服务、卫生保洁、公共维修,到后来的小区广告、垃圾分类、防疫安全、快递服务,物业不断在…

数字化转型利器,云表无代码“打破”工业软件开发壁垒
近年来,“数字化”概念成为了各行各业的“热词”,作为与信息化程度高度相关的工业软件,在数字化转型中扮演着不可或缺的角色。据 Gartner最新研究数据显示,目前中国工业软件市场规模已经达到了380亿美元,但与发达国家相…
leecode 数据库:608. 树节点
导入数据:
Create table If Not Exists Tree (id int, p_id int);
Truncate table Tree;
insert into Tree (id, p_id) values (1, None);
insert into Tree (id, p_id) values (2, 1);
insert into Tree (id, p_id) values (3, 1);
insert into Tree (id, p_id) v…

最全面的WMS系统选购指南:从功能到价格一网打尽
WMS(仓库管理系统)是一款能够提高仓储和物流企业效率的重要工具,并且能够帮助客户更好地管理他们的供应链网络。但是市面上有很多不同的WMS系统,如何选出最适合自己的系统呢?下面将为您介绍全面的WMS系统选购指南。 功…

SaaS突围战,用友走了8年,金蝶却用了10年,成果却被捷足先登
“南金蝶北用友”得风口在哪里?
众所周知,在企业软件管理市场中,一直有着这样的说法“北用友南金蝶”,足以可见,两家企业在市场中的份量。两家公司最初都是以财务软件起家,关于创始人王文京和徐少春的创业…
supervisor配置kafka启动
报错:/usr/local/kafka-2.11-2.3.0/bin/kafka-run-class.sh: 第 299 行:exec: java: 未找到
可在supervisor中配置的kafka.err文件中看到报错信息
解决办法有三种: 方法一:修改实际Java安装路径,与kafka默认的路径一致ÿ…
leecode 数据库:1070. 产品销售分析 III
导入数据: Create table If Not Exists Sales (sale_id int, product_id int, year int, quantity int, price int);
Create table If Not Exists Product (product_id int, product_name varchar(10));
Truncate table Sales;
insert into Sales (sale_id, product…

在大数据中探寻治病密码,中山六院精准医学踏数而行
2015年初,精准医学正式进入大众的视野,美国总统奥巴马在国情咨文中提出“精准医学”计划。自此,精准医学在全球掀起一股浪潮,个性化医学的大幕也正式拉开。
所谓精准医学,是以个体化医疗为基础、随着基因组测序技术快…

持续进阶,软通动力稳步推动云智能战略
伴随国内云MSP市场在逐渐步入融合阶段,软通动力将围绕MSP的云战略也逐步升级到围绕云智能服务展开,以期为客户的价值重塑和公司的业务的扩张插上新的翅膀。 MSP成为云业务强大抓手,助推企业数字化
之前,IDC曾分析指出,…
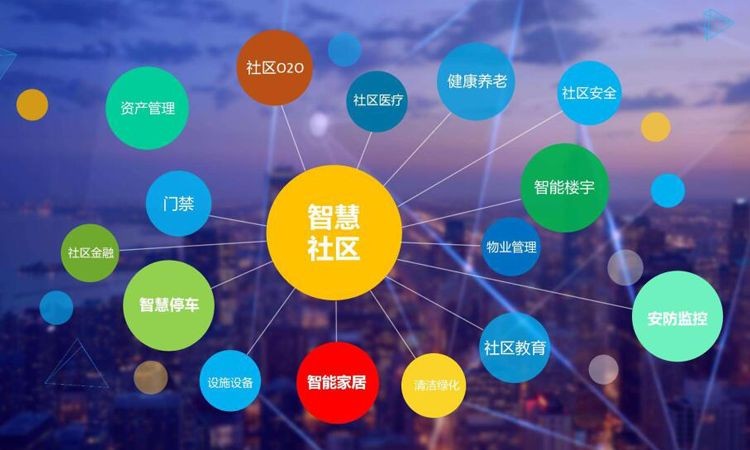
物业上市赛道再添新丁,金茂物业能否打破低毛利魔咒?
2019年以来,房地产行业整体估值下降明显。相对而言,轻资产、低负债的物业管理行业在资本市场认可度更高,于是,房企开始纷纷拆分物业上市。
据港交所2月6日披露,中国金茂旗下附属公司金茂物业服务发展股份有限公司通过…

Flink的安装和部署--伪分布模式
Flink的安装和部署主要分为伪分布模式和集群模式:伪分布:如果Flink对应的Java进程都运行在一个物理机器上,称为伪分布模式,如果Flink对应的
Java进程运行在多台物理机器上,称为集群模式.
伪分布模式就是在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行…
同程艺龙Q3财报:深耕“下沉”之外,诠释另一个增长维度
2021年是“十四五”规划开局之年,也是“两个一百年”的历史交汇点。
这一新的历史节点,对于企业而言,既是挑战也是与社会、自然共融共生的蜕变过程。
作为与人们生活质量息息相关的OTA行业,同样肩负起实现社会价值的责任和使命。…

全行业数字化转型加速,到底什么存储会更吃香?
之前,有全球专业分析机构IDC的公开数据显示,自2010年以来全球正式进入ZB时代,预计到2025年全球数据量估计将会增至175ZB。
那么,全球数据量高速增长的背后,到底是什么在推波助澜呢?这又引发了另一个重要的…
迈向ZB时代,这个存储厂商再次刷新了一下HDD与SSD的定义
这下,ZB时代真的来了。
满足ZB时代下企业级数据存储的多方面需求,助力企业更好地应对诸多挑战,进一步挖掘和实现数据的价值。这成为所有存储厂商关注的焦点。
无论是传统企业还是新兴企业,数字化加速必然对于数据存储的需求倍增…

基于Flink实时数仓——DWM 层-跳出明细计算(3.2)
什么是跳出?
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。而 跳出率就是用跳出次数除以访问次数。 关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间 的质量对比&am…
后版权时代,网易云用IPO开启进击之路
时隔三个月,网易云IPO有了新进展。
近日,网易在对外发布了Q3财报,同日,网易云音乐通过上市聆讯并在港交所更新了聆讯后资料集。
事实上,今年8月,网易云音乐就已经通过港交所聆讯,但是基于市场…
数据仓库为什么要分层
离线数仓中为什么要分层? 简单概述一下:
解耦提高数据复用性(最重要)将复杂需求简单化,从原本的需要执行十几步,分层之后只需做一步两步防止重复计算可以屏蔽敏感数据 建设实时数仓的目的,主要…
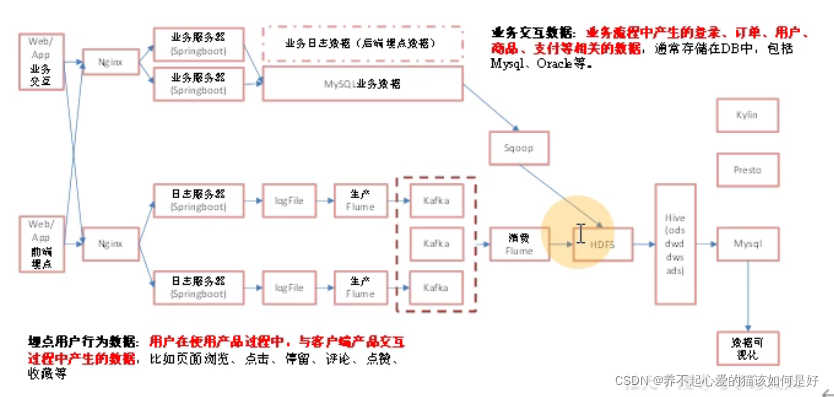
实时数仓与离线数仓架构对比、Flink消费流程
实时数仓架构图: 离线数仓:
与离线数仓区别:
MySQL业务数据采集改用FlinkCDC;FlinkCDC与Maxwell处理方式和Cannal一样通过监控binlog方式(行级别),而Sqoop是通过MR方式处理数据,这种方式太慢…

200亿美元是不是少了点,思科公司看上了Splunk这个香饽饽?
【全球云观察 | 科技明说】200亿美元是不是少了点,思科公司看上了Splunk这个香饽饽?
思科这样的大佬,也情中于Splunk,不管传言是否属实,都充分表明了Splunk要不早已看穿了发展的天花板,要不要不早就疯狂转…

A Text-Based Analysis of Corporate Innovation
A Text-Based Analysis of Corporate Innovation(Gustaf Bellstam) – 论文精读 文章目录A Text-Based Analysis of Corporate Innovation(Gustaf Bellstam) -- 论文精读核心速览问题背景方法论研究方法细节通过LDA得到创新主题根据创新主题得到衡量指标主回归比专利衡量更优的…

rdd算子之byKey系列
spark中有一些xxxByKey的算子。我们来看看。 rdd算子之byKey系列groupByKey解释实现groupByreduceByKeydistinctaggregateByKeycombineByKeygroupByKey
解释
假设我们要对一些字符串列表进行分组:
object GroupByKeyOperator {def main(args: Array[String]): Un…

ElasticSearch基础篇
ElasticSearch
一、简介
mysql作为数据持久化,ElasticSearch提供检索功能
基本概念
ESMySQLindex(索引)databasetype(类型)tabledocument(文档)record(记录)在ES中,数据是以json格式存储的 ES模型 ES的工作原理
倒排索引
将要保存的数据data进行分…
2021-10-14 2021年中式烹调师(中级)证考试及中式烹调师(中级)理论考试
题库来源:安全生产模拟考试一点通公众号小程序
安全生产模拟考试一点通:中式烹调师(中级)证考试考前必练!安全生产模拟考试一点通每个月更新中式烹调师(中级)理论考试题目及答案!多…

P10 数据库系统概论——关系代数1(传统集合操作)
文章目录关系数据库语言的分类【关系代数语言】【关系演算语言】具有关系代数和关系演算双重特点的语言关系代数关系代数运算符1.传统的集合运算一些符号(1)【并】Union(2)【差】Difference(3)【交】Inters…

TDengine 在水电厂畸变波形分析及故障预判系统中的应用
作者:深圳双合电机监测和故障预测产品研发团队 小 T 导读:深圳双合电气股份有限公司成立于 1993 年,是国家级高新技术企业和广东省专精特新企业。公司致力于电力及工企业系统应用解决方案及相关智能监测设备的研究、开发、生产与实施…

涛思数据荣登“创业邦 100 未来独角兽榜单”“2021 AIoT 新维奖行业先锋榜”
2021 年临近年末之期,涛思数据的荣誉墙上再添两个重量级奖项,这也成为新收到的最耀眼的“新年礼物”。 涛思数据荣登 2021 AIoT 新维奖企业榜行业先锋榜 在数字化时代,物联网无疑已经成为企业转型升级的技术底座,各行各业都在借助…

MYSQL数据库配置
原子性:要么都成功,要么都失败 一致性:加起来总是13000 持久性:只要变化就要提交 隔离性:两个进程操作同一个进程需要隔离开
########数据库:######## GPL通用公共许可证 General Public License GNUGNU i…

条信息流oCPC调研报告
1. oCPC原理
控制人群出价,提高单次点击价值
对预估高转化人群提高出价,获取流量;对预估低转化人群降低出价,减少展现,最终使平均转化成本低于设定的目标价格。
其核心:是通过控制人群出价、提高转化率&…

Spark实现数据生产到parquet及hive表
1. spark-shell 执行脚本
spark-shell 中相当于定义了一个Object并提供main(),且代码都是在其中执行,不需额外定义Object。
test.scala
//import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSe…
Nebula图数据库的使用
1. 服务启动
1.1 docker开启
# 启动docker服务
systemctl start docker
# 或使用该命令重启docker服务
systemctl restart docker
# 关闭docker服务
systemctl stop docker
1.2 开启nebula服务
# 下载nebula-docker-compose文件
git clone https://github.com/vesoft-i…

Spark的安装和使用方法
1. 安装Spark 2. 在Spark shell中运行代码
Spark Shell本身就是一个Driver,Driver包mian()和分布式数据集。
启动Spark Shell 命令: ./bin/spark-shell --master <master-url> Spark的运行模式取决于传递给SparkContext的Master URL的值…

Spark讲解与使用
Map Reduce存在的问题
在介绍Spark首先需要介绍为何要提出Spark,Hadoop高度支持的Map Reduce框架有什么不好的地方吗?
答:没有完美的机制,Map Reduce范式存在下面问题
1、模型能处理的应用有限,主要基于Map和Reduce…

数据挖掘——第一章:概述
文章目录1. 数据分析与数据挖掘1.1 数据分析1.2 数据挖掘1.3 知识发现(KDD)的过程1.4 数据分析与数据挖掘的区别1.5 数据分析与数据挖掘的联系2. 分析与挖掘的数据类型2.1 数据库数据2.2 数据仓库数据2.3 事务数据2.4 数据矩阵2.5 图和网状结构2.6 其他类…
ES根据两个条件分组查询
一 : 需求: 根据sn码值进行分组,获取每个分 组中成功个数,进行计算成功率.
代码: /*** 音箱播报成功率监控 分页查询** param soundBoxBroadcastQuery 音箱播报入参查询* return {link R}*/GetMapping("soundBoxBroadcastMonitor")public R soundBoxBroadcastMonito…
企业治理实战-经验分享
该文章已同步到语雀公开知识库《大数据技术架构手册-1》中;公众号后台回复“小程序注册码”可免费查看面试题小程序
前言
作为一名数据人,常常自嘲为SQL Boy,某天突然发现原来SQL boy还有一些更高级的工作内容:数据治理。这两年也有很多的大…
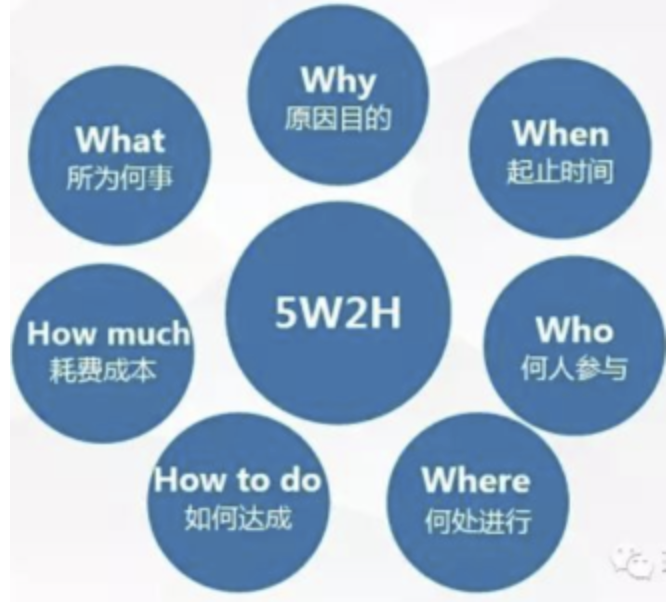
依托公众号场景建设指标体系
概念
首先看一下百度百科对指标体系的解释:“指标体系指的是若干个相互联系的统计指标所组成的有机体”。它主要由指标和体系两部分组成。那么也就是将零散指标通过某种关系系统化的整合起来形成完整的一棵树。
指标是指将业务单元细分后量化的度量值,…
头歌Educoder云计算与大数据——实验四 HDFS文件读写
头歌Educoder云计算与大数据——实验四 HDFS文件读写答案在下面的链接里https://blog.csdn.net/qq_36595013/article/details/80571441
捷径智慧物业系统助力“书香小区”建设
物业与业主共赢,捷径智慧物业系统助力“书香小区”建设
我国的物业管理在不断发展,虽然没有达到理想化的程度,但是相比之前几年能看到改善,在这样的背景下,大多数小区物业和业主的关系也没有那么剑拔弩张了。
但是&a…
物业营收翻倍,捷径智慧物业系统打造物业多维服务新趋势
物业营收翻倍,捷径智慧物业系统打造物业多维服务新趋势
伴随社会智能化、信息化飞速发展,智能手机已经成为大众化选择,而以智能手机为核心的智能家居也已经走进千家万户。
如何适应信息化智能发展,已经成为各个行业面临的通用挑…
物业业主一家亲?该如何化解?-捷径智慧物业管理系统
物业业主一家亲?该如何化解?-捷径智慧物业管理系统
我国的物业管理在不断发展,虽然没有达到理想化的程度,但是相比之前几年能看到改善,在这样的背景下,大多数小区物业和业主的关系也没有那么剑拔弩张了。 …
捷径智慧物业系统提出社区建设新方向
物业也能玩共享?捷径智慧物业系统提出社区建设新方向
随着国家大力支持社区发展建设,越来越多的社区发展模式开始涌现。
从社区团购兴起到社区文化服务拓展,社区发展已经进入高速期,如何提高社区资源利用率,构建多重…

DT时代,企业要有“经营安全、安全经营”新思维
8月26日,主题为“经营安全、安全经营”的2021北京网络安全大会(下称BCS)以云峰会形式举行。来自全球的顶尖专家、行业学者、企业高管们齐聚一堂,就当前网络安全的新形式、新趋势、新机遇等进行了畅谈和分享。
01
在BCS2021看网络…
我在这个小区买了套房,只因它有-捷径智慧物业系统
我在这个小区买了套房,只因它有-捷径智慧物业系统
作为一个曾一年内搬家三次的搬家星人,真的能够踏踏实实的体验到:一家好的物业有多么多么重要。
这不仅仅是安全问题,更多的是让业主及住户安心。
在我入住这个小区之前&#x…
刚从 Nova 生出来的 Placement 是什么东西?
历史背景
私有云的用户,尤其是传统 IT 架构转型的私有云用户一般会拥有各式各样的存量资源系统,与这些系统对接会让 OpenStack 的资源体系变得复杂。
从用户的视角出发,或许你会希望: 作为使用共享存储解决方案的用户࿰…
申请把公司系统升级为捷径系统的报告-捷径系统
申请把公司系统升级为捷径系统的报告
尊敬的徐总、陈总、总部管理成员:
XX游泳健身,成立7年了,从我入职时的1家店,至今在XX市有了4家成品店,即将新增2家店。我们每家店平均每月会籍业绩10多20万,私教业绩…
社区居家养老实践中的问题,以及捷径智慧养老系统解决方案-捷径系统
社区居家养老实践中的问题,以及捷径智慧养老系统解决方案-捷径系统 老龄化问题持续受到关注,除了传统家居养老外,目前社区养老和机构养老并轨前行。根据现状发现,越来越多的高龄老人倾向于考虑离家近的社区养老照护服务。 一般有这…

Spark RDD编程
一、 实验目的:
1.熟悉 Spark RDD的基本操作。 2.熟悉使用RDD编程解决具体问题的方法。
二、 实验内容和要求:
编程实现输出前3个学生的信息、文件中前3个学生的平均分、文件中前3个学生的最高分、文件中前3个学生的平均分、总分数最高的前三名、Scal…

分布式一致性协议之 2PC 和 3PC
分布式系统的一致性协议之 2PC 和 3PC
在分布式系统领域,有一个理论,对于分布式系统的设计影响非常大,那就是 CAP 理论,即对于一个分布式系统而言,它是无法同时满足 Consistency(强一致性)、Availability(可用性) 和 …

zookeeper应用场景一:实现配置中心动态更新配置
思路:
我们在开发的时候,有时候需要获取一些公共的配置,比如数据库连接信息等,并且偶然可能需要更新配置。如果我们的服务器有N多台的话,那修改起来会特别的麻烦,并且还需要重新启动。这里Zookeeper就可以…

《技术的本质》 读书笔记
序一 路径依赖性:人口、经济、技术
凡技术发明者,首重适用性和便利性,发明专利所谓“实用新型”。这两大性质要求使用新技术的人群将以往行为与新技术相合。如果你从微软视窗系统转入苹果系统,你会有很多这样的体会,多…
【ES源码分析】强制合并分段(_forcemerge API)源码分析
_forcemerge API 源码分析 文章目录_forcemerge API 源码分析合并方式只合并删除文档没有限制最大segment数的合并限制了最大segment数的合并合并策略合并策略的动态设置ES对于Lucene的策略封装合并调度调度相关动态配置使用场景使用说明源码基于6.7.2 合并方式
RestForceMerg…

【Flink学习】入门教程之Data Pipelines ETL
文章目录数据管道 & ETL无状态的转换map()flatmap()Keyed StreamskeyBy()通过计算得到键Keyed Stream 的聚合(隐式的)状态reduce() 和其他聚合算子有状态的转换Flink 为什么要参与状态管理?Rich Functions一个使用 Keyed State 的例子清理…
Java实现kudu的增删查改
文章目录1、依赖导入2、创建kudu表3、删除kudu表4、插入数据到kudu5、查询kudu数据6、修改kudu表数据7、删除kudu中指定行的数据1、依赖导入
<dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-client</artifactId><version&…
利用Java的API实现HBase数据库的增删查改
文章目录一、功能描述二、依赖导入三、配置信息3.1log4j的配置3.2连接配置四、Configuration五、Common六、Java操作HBase集群一、功能描述
本功能组件主要通过Java的API实现HBase的操作。利用log4j进行数据迁移过程的记录,采取批处理的方式实现数据迁移的过程。
…
【Flink学习】flink-training浅析
文章目录官网练习数据集说明Schema of Taxi Ride Events 乘坐出租车事件的结构项目工程commonride-cleansingRideCleansingSolutionhourly-tipsHourlyTipsSolutionrides-and-faresRidesAndFaresSolutionlong-ride-alertsLongRidesSolution官网练习
数据集说明
纽约市出租车和…
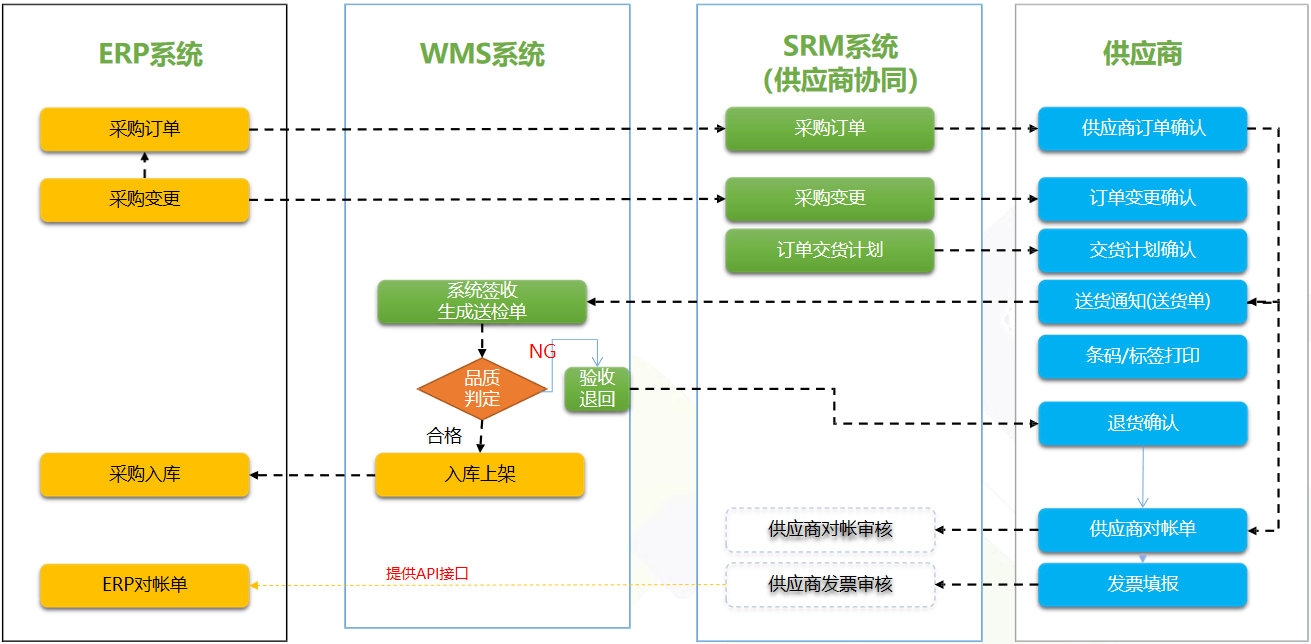
MES生产管理系统简介与实践经验分享,一篇就够了
MES系统是制造业企业数字化转型的重要组成部分,也是实现智能制造的基础。本文将从MES系统的定义、功能和应用实践等方面进行介绍和分享。
一、MES系统简介
MES系统(Manufacturing Execution System)又称生产执行系统,是在企业信…
数据库十大经典常见经典问题
一 索引 1)索引之无索引案例 问题描述: 用户系统打开缓慢,数据库CPU 100% 问题排查: 发现数据库中大量的慢SQL,执行时间超过了 2 s 慢SQL: select id from user where user_no13772556391 limit 0,1; 执行计…
sql数据库中的timeStamp转成Date,Date转成LocalDateTime
Testpublic void testDate(){Date dt new Date();System.out.println(dt);long l System.currentTimeMillis();Date dt2 new Date(l);System.out.println(dt2);//timeStamp和Date的转换long l2 Long.parseLong("1628160003000");System.out.println(new Date(l2)…
⑦Flink窗口、时间和水印
我们在之前的课时中反复提到过窗口和时间的概念,Flink 框架中支持事件时间、摄入时间和处理时间三种。而当我们在流式计算环境中数据从 Source 产生,再到转换和输出,这个过程由于网络和反压的原因会导致消息乱序。因此,需要有一个机制来解决这个问题,这个特别的机制就是“…
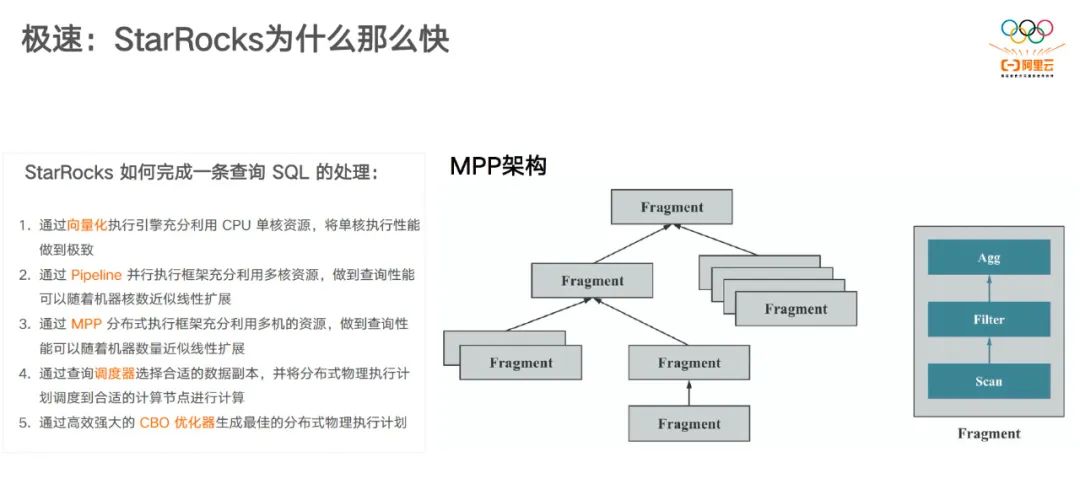
让数据分析极速统一,阿里云和StarRocks一起干了件大事
“过去,仅仅是管理层少数人定期查看各种数据报表;如今,哪怕基层员工都是数据消费者,日常业务中随时需要使用历史数据和实时数据做决策,这种趋势将不可阻挡。”去年一家银行数据部负责人对大数据在线如是说。
的确&…
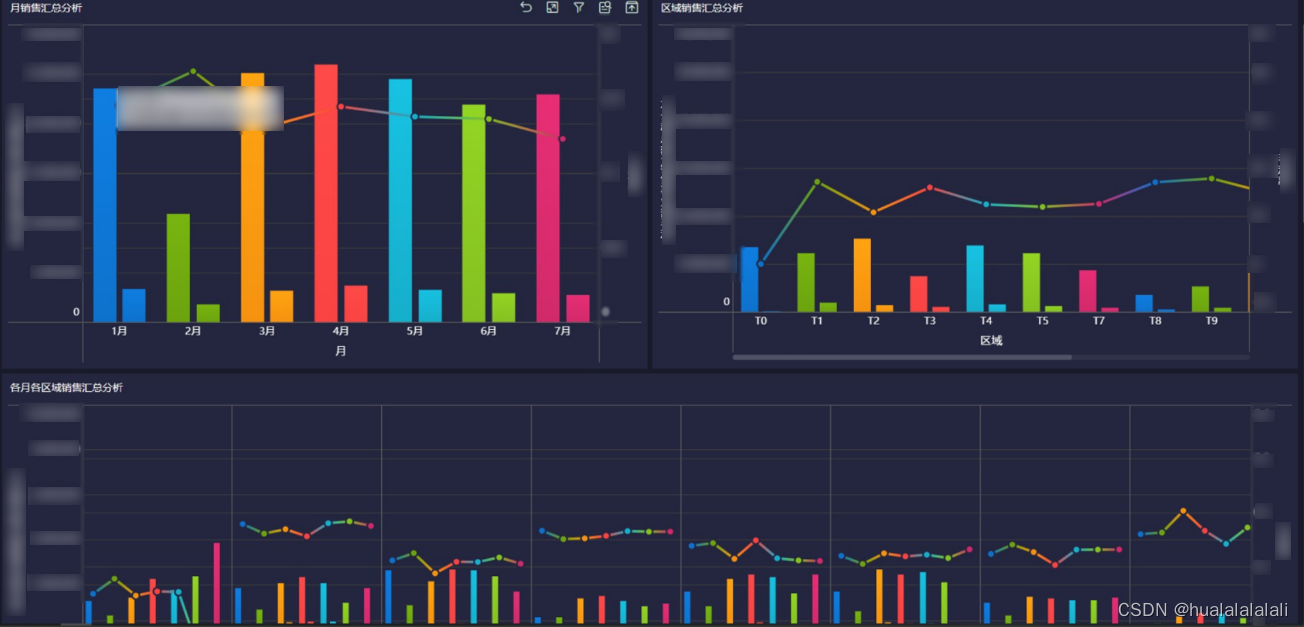
怎么搭建大数据平台,这个大数据平台方案值得学习
在大数据的时代,不仅仅是个人,企业的发展也离不开大数据。对于企业来说,一方面用户越来越多从线下转移到线上,用户的特点属性需要通过网络获取,企业需要依靠大数据把握市场变化并了解客户,从而提供满足市场…

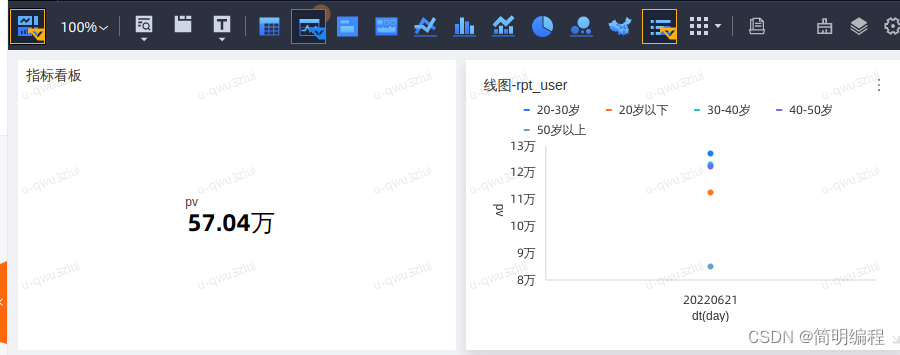
阿里云全链路数据治理
阿里云全链路数据治理实验全流程阿里云全链路数据治理实验全流程实验地址实验流程通过DataWorks采集日志数据至MaxCompute创建业务流程配置workshop_start节点新建表配置离线同步节点。提交业务流程。运行业务流程确认数据是否成功导入MaxCompute。通过DataWorks计算和分析已采…
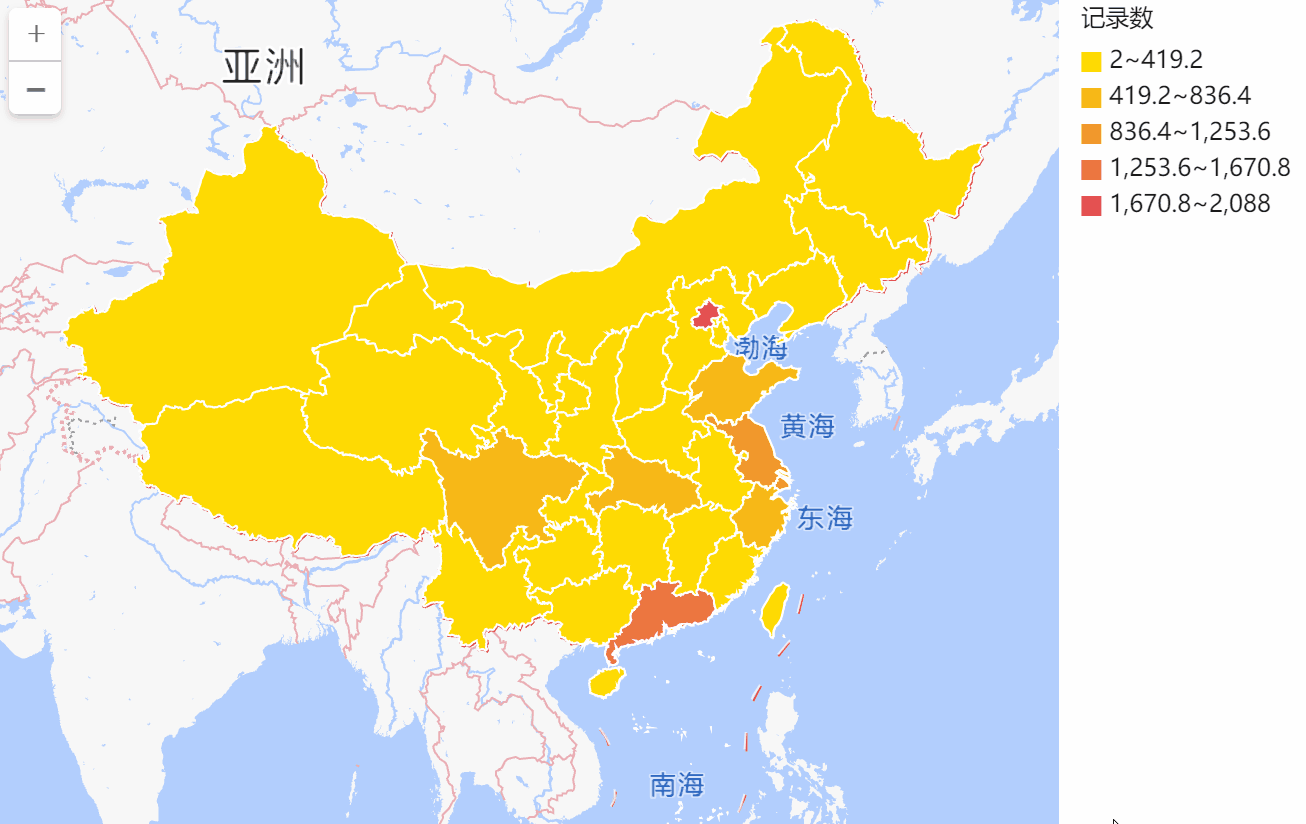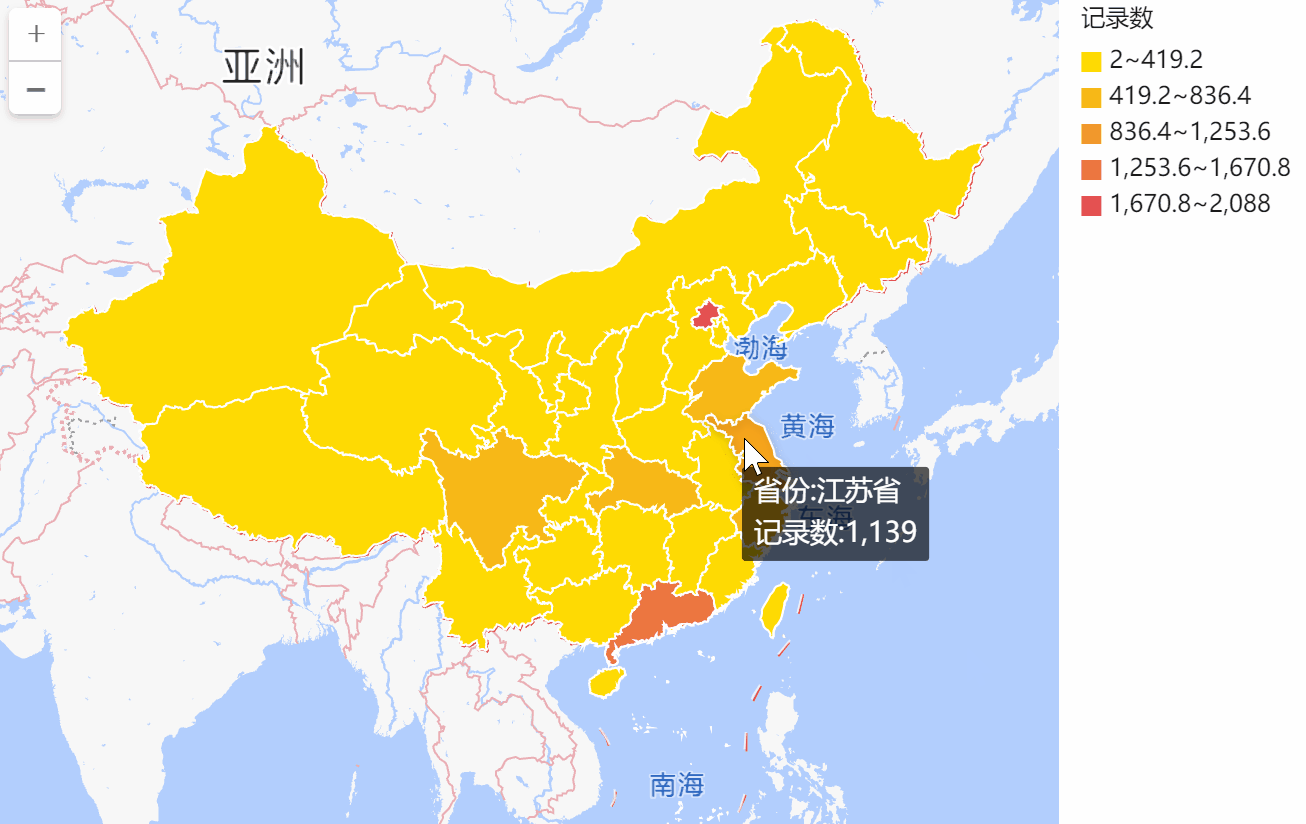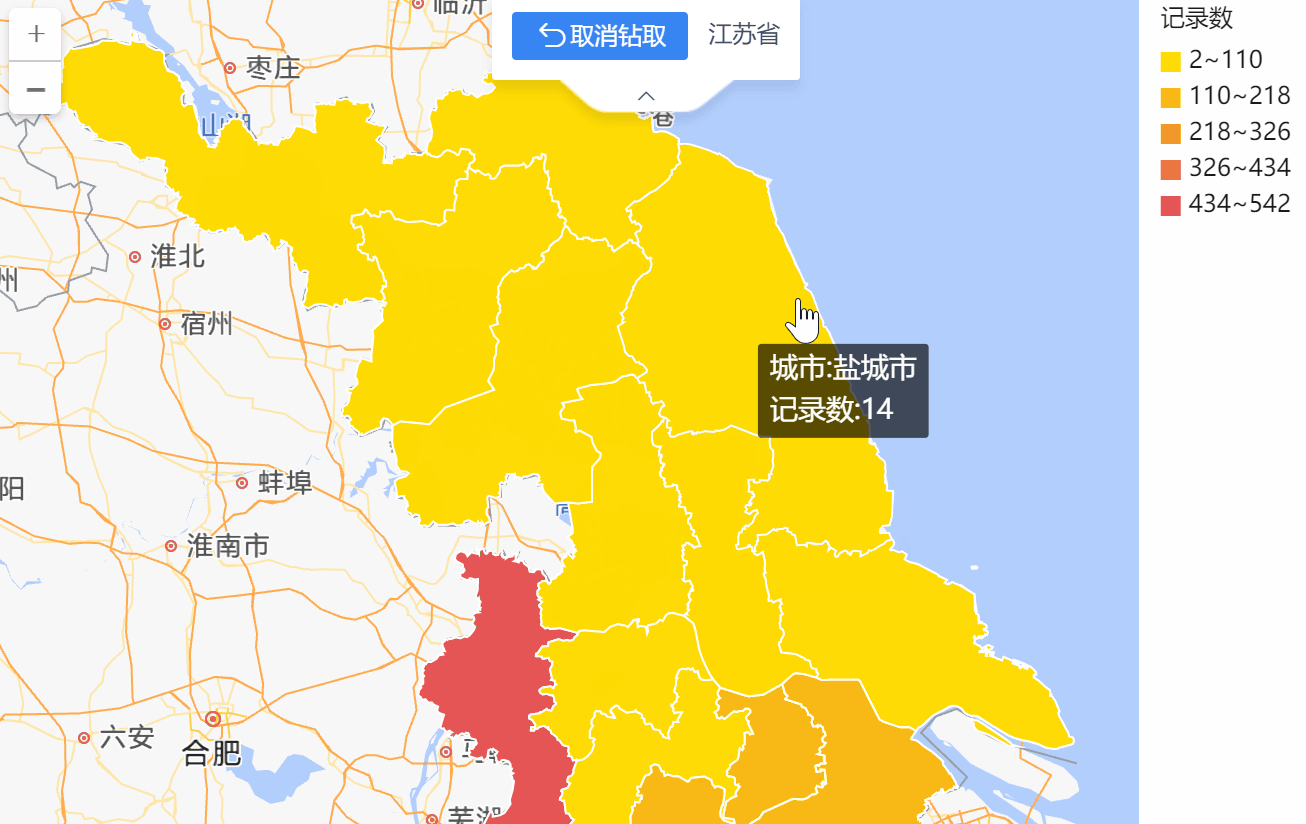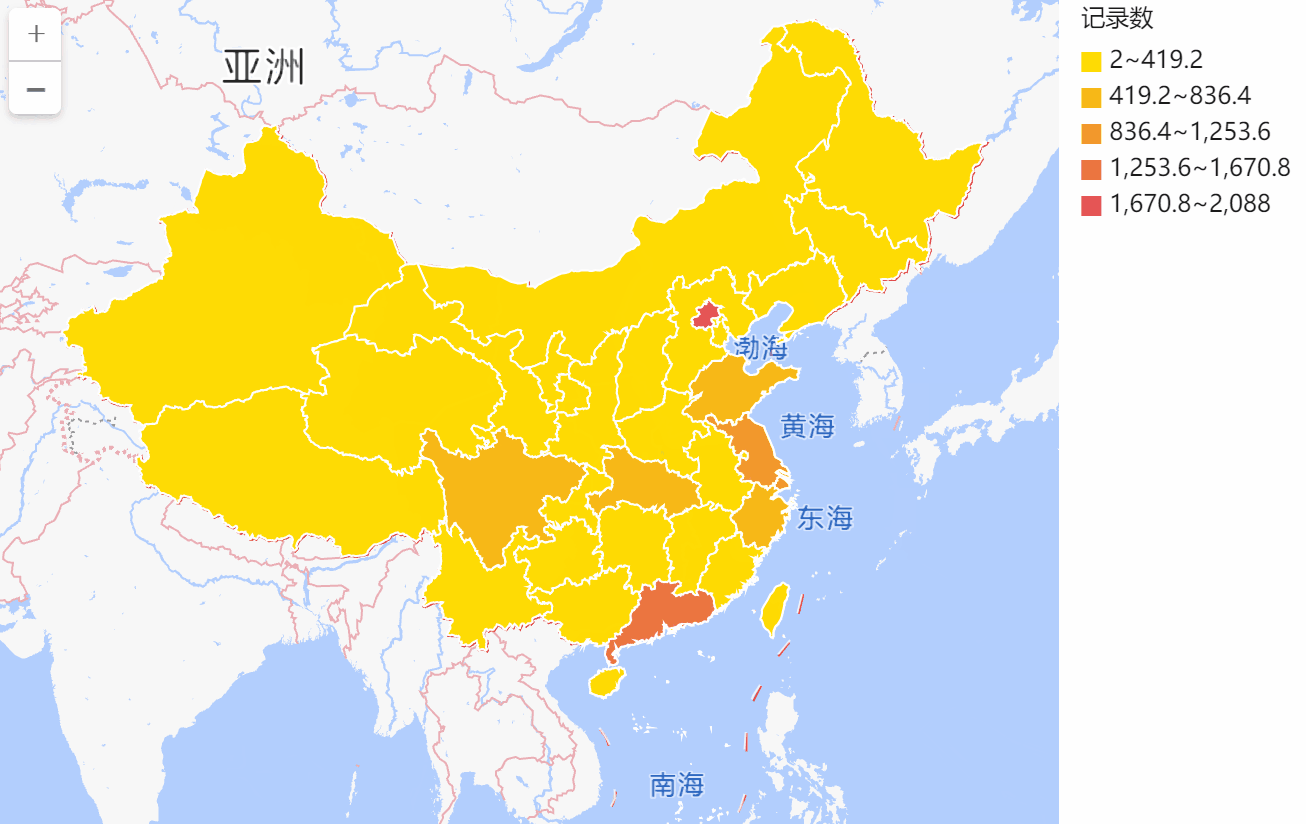
这款多维数据分析工具超级好用
在进行数据分析的过程中,我们如果想要了解数据,就需要从不同维度去探索。如果仅仅从单一维度去分析,很有可能会遗漏掉重要的数据信息。多维分析(OLAP)对于企业来说是进行数据分析时的核心,借助OLAP可以进行多角度、立体化、灵活动…

电商RPA教你玩转商品上下架
随着新型电商的顺势崛起,传统电商在运营方面似乎显得有些乏力,要不就是效率低成本高,要不就是缺乏人手。就拿简简单单的商品上下架来说,传统电商在其中也要花费大量的时间人力成本,可以说是得不偿失。
很多朋友都认为…
实在智能RPA助你揭开淘宝搜索权重引流规则
摘要:实在智能为电商运营提供RPA自动化解决方案,淘宝搜索框下拉框关联词获取机器人、生意参谋平台自动化下载报表机器人……实在智能RPA助力电商人提升运营效率!
说到电商,就避不开店铺运营,而店铺整体的引流布局&…

Flink自主内存管理——JVM堆上内存和堆外内存的问题
系列文章目录 文章目录系列文章目录前言一、JVM内存管理在大数据场景下的问题1.有效数据密度低2.垃圾回收1.OOM问题影响稳定性1.缓存未命中问题二、自主内存管理堆上内存的问题堆外内存的不足之处前言 Java语言的好处是不用考虑底层,JVM可以对代码进行深度优化&…

基于Flink实时数仓——DWS层-关键词主题表FlinkSQL(9)
需求分析与思路:
关键词主题这个主要是为了大屏展示中的字符云的展示效果,用于感性的让大屏观看者感知目前的用户都更关心的那些商品和关键词。 关键词的展示也是一种维度聚合的结果,根据聚合的大小来决定关键词的大小。 关键词的第一重要来…

Chapter6 数据仓库Hive
6.1数据仓库概念
6.1.1什么是数据仓库
数据仓库:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据仓库的目的:支持企业内部的商业分析和决策,让企业可以基于数据仓库的分析结果…

基于Flink实时数仓——DWS 层-地区主题表(8)
这个主题使用FlinkSQL实现:数据直接从dwm_order_wide主题获取 代码实现:
public class ProvinceStatsSqlApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env StreamExecutionEnviro…
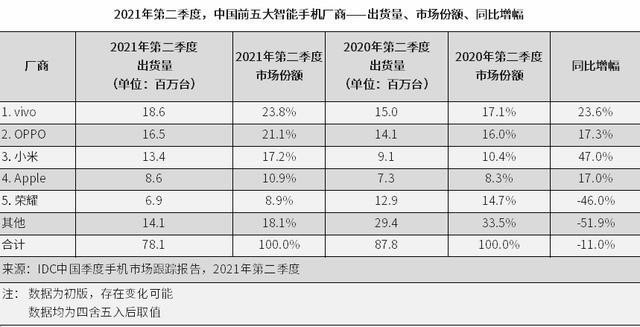
时隔两年,再战女性市场,但小米这次还能重回C位吗?
作为人们生活中早已离不开的电子产品,发展至今,国内各大手机品牌也从单一的销售模式走向多元化发展,手机行业集中度明显提高。
据前瞻经济研究院数据显示,从2015年到2020年我国智能手机市场前五大品牌市占率从59.7%升至96.5%。可…

纳入沪港通却遭ARK减持,移卡距“中国版Square”还有多远?
要说近年来资本市场上,最风光的投资公司之一,ARK投资便是其中之一。
创始人Cathie Wood,被无数投资者奉为科技女股神,凭借着“颠覆性创新”的投资手段,今年1月ARK系列基金投资回报超过贝莱德、道富等传统投管巨头。
…

智慧社区数字孪生IOC系统
智慧社区数字孪生IOC可汇聚综合态势、事件感知、监督指挥、决策分析、公共服务等功能,通过整合社区“人、地、事、物、组织”等全要素,实现辖区内人口、房屋、车辆、设施设备、突发事件、应急预案等信息及数据联动,实现“一张图”服务的360全…

浅析 Spark 中 Key-Value 类型的 RDD
1.partitionBy
1)函数签名
def partitionBy(partitioner: Partitioner): RDD[(K, V)]2)函数说明 将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner 注意:要将 rdd 转换为 Key-Value 元组类型,才…
全国范围内-购物中心数据-2023-08月更新
最新收录全国8000购物中心基础信息和电子围栏信息,字段如下:
数据纬度字段名注释枚举值基础信息id主键ID13066name项目名称南通通州新瑞广场lat纬度32.08407593lng经度121.0762939address地址通州区建设路66号area行政区/县通州区city城市南通市provinc…

Spark数据读写--HDFS、HBase、Json
1. 本地文件的读写
1.1 读文件
import org.apache.spark.sql.SparkSessionval inputPath "file:///Users/zz/Desktop/aa.sh"
val rdd spark.sparkContext.textFile(inputPath)
上面代码执行后,因为Spark的惰性机制,并不会真正执行&#x…


《从0开始学大数据》的启示
《从0开始学大数据》学习后感方法论与哲学学习的目的以及形成思维体系抽象能力,为什么是A而不是B?从MR-Spark看产品思维模式思维大数据发展历史分布式计算的核心思想——移动计算而非移动数据大数据系统与大型网站系统设计思路的差异大型网站的思路大数据…
Hadoop namenode重新格式化需注意问题
Hadoop namenode重新格式化需注意问题
1、重新格式化意味着集群的数据会被全部删除,格式化前需考虑数据备份或转移问题; 2、先删除主节点(即namenode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs…
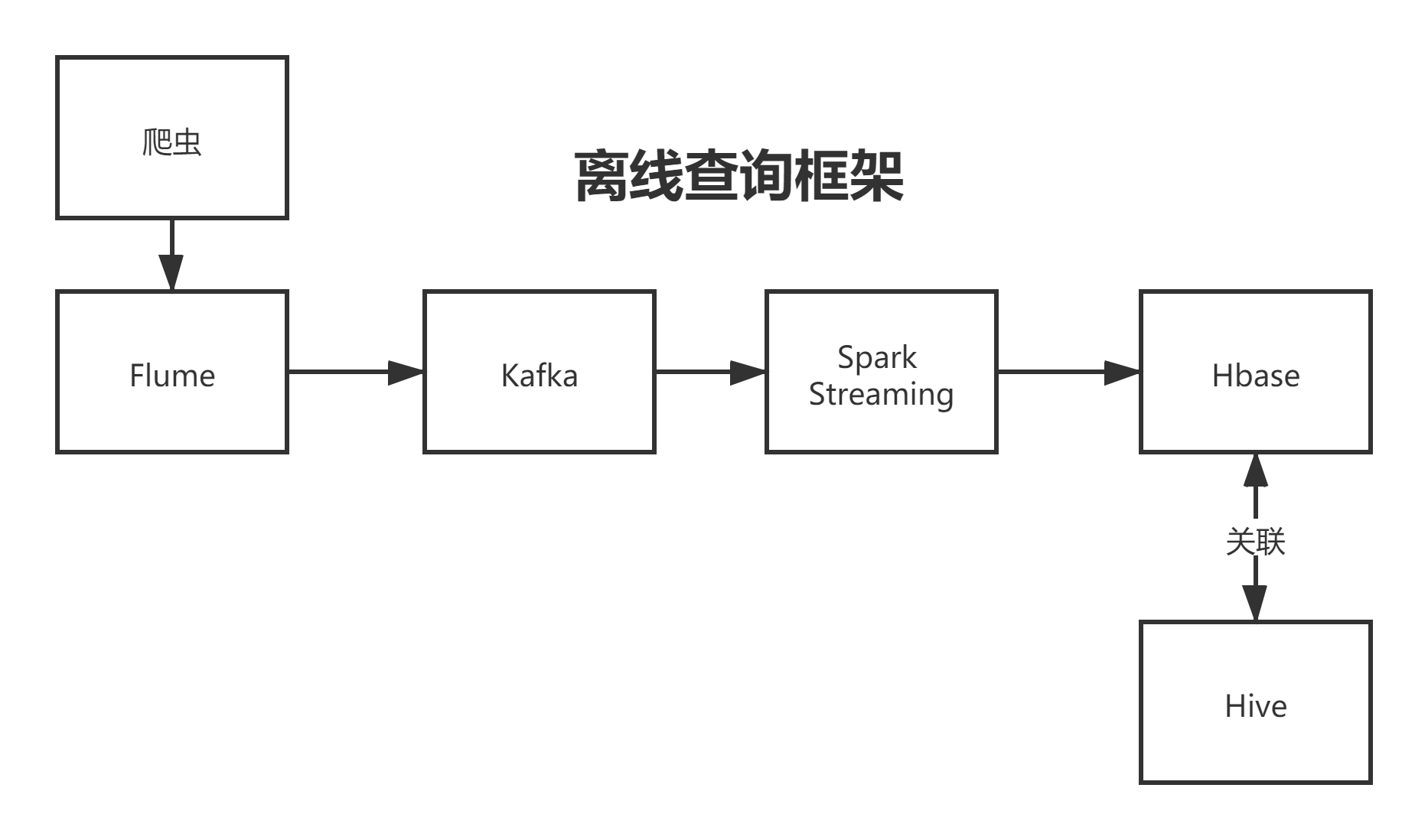
Spark Streaming实时写入HBase(十分稳定,不会导致宕机)
文章目录Spark Streaming实时写入HBase0--适用框架1-代码解析1-1 Kafka部分1-2 Hbase部分2-代码源码3-pom.xmlSpark Streaming实时写入HBase
0–适用框架 1-代码解析
1-1 Kafka部分
//定义一个主题数组,内可包含多个主题,此处只有一个
val kafkaTopic…
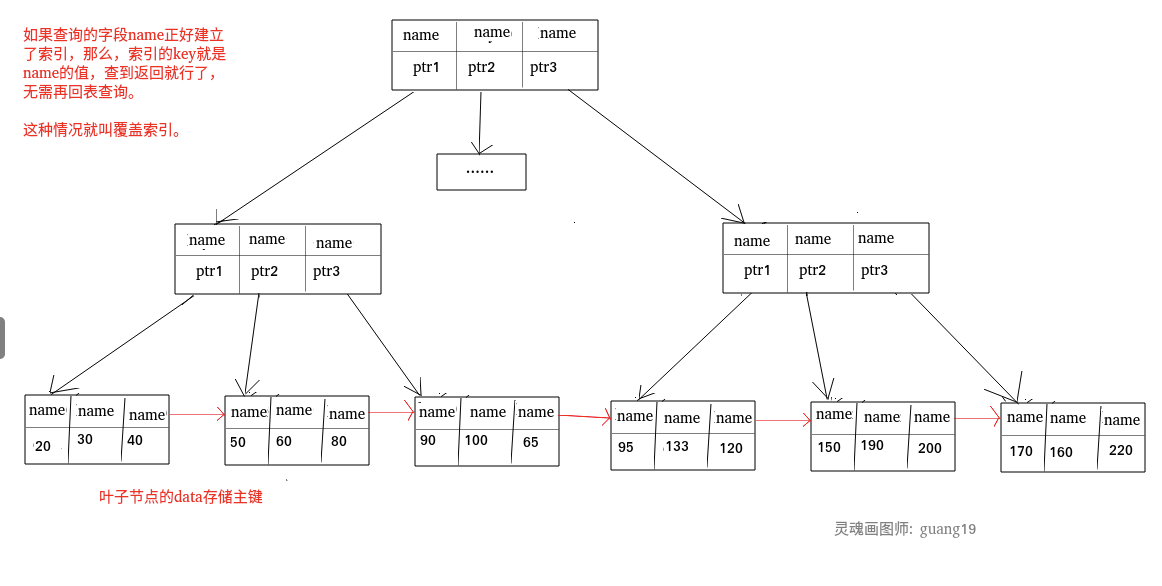
MySQL数据库索引详解
何为索引?有什么作用?
索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B 树, B树和 Hash。
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找…

融资租赁行业的小问题,喜相逢的大难题
喜相逢的高光时刻,是作为国内第一家融资租赁平台挂牌新三板。目前,喜相逢在全国24个省份及直辖市,布局有66间线下销售门店。
起家于汽车租赁,自2012年将业务模式的重心转放向以租代购业务,也就是融资租赁。
2017年&a…


Kudu用法详尽剖析
最近在招聘要求下突然看到了Apache kudu 于是花了几天时间研究了下,下面简单的给大家介绍下 记得收藏。
一、Kudu 介绍
1.1、背景介绍 在KUDU之前,大数据主要以两种方式存储;
【1】:静态数据 以 HDFS 引擎作为存储引擎…
达梦V8使用dmrman恢复数据库
因业务测试需要恢复上周2的备份,我们停库通过dmrman工具进行数据库的恢复,记录下整个过程:
1、查看dmrman的备份片信息
#####show backupset 查看备份片的备份信息
RMAN> show backupset /dm8/bak/disql_inc_0902;
show backupset /dm8/…


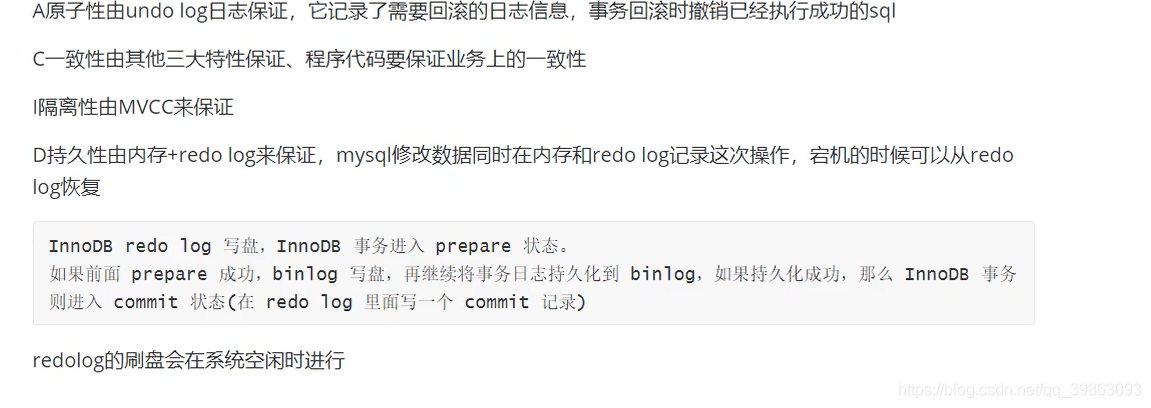

某互联网大厂亿级大数据服务平台的建设和实践
一、引言:
在大数据建设过程中,通用的建设思路:从数据埋点——数据采集——数据清洗(ETL)——数据服务——数据可视化。整体流程可参考下图: 这篇文章主要想和大家聊聊的是,数据服务平台的建设。 二、背景:…
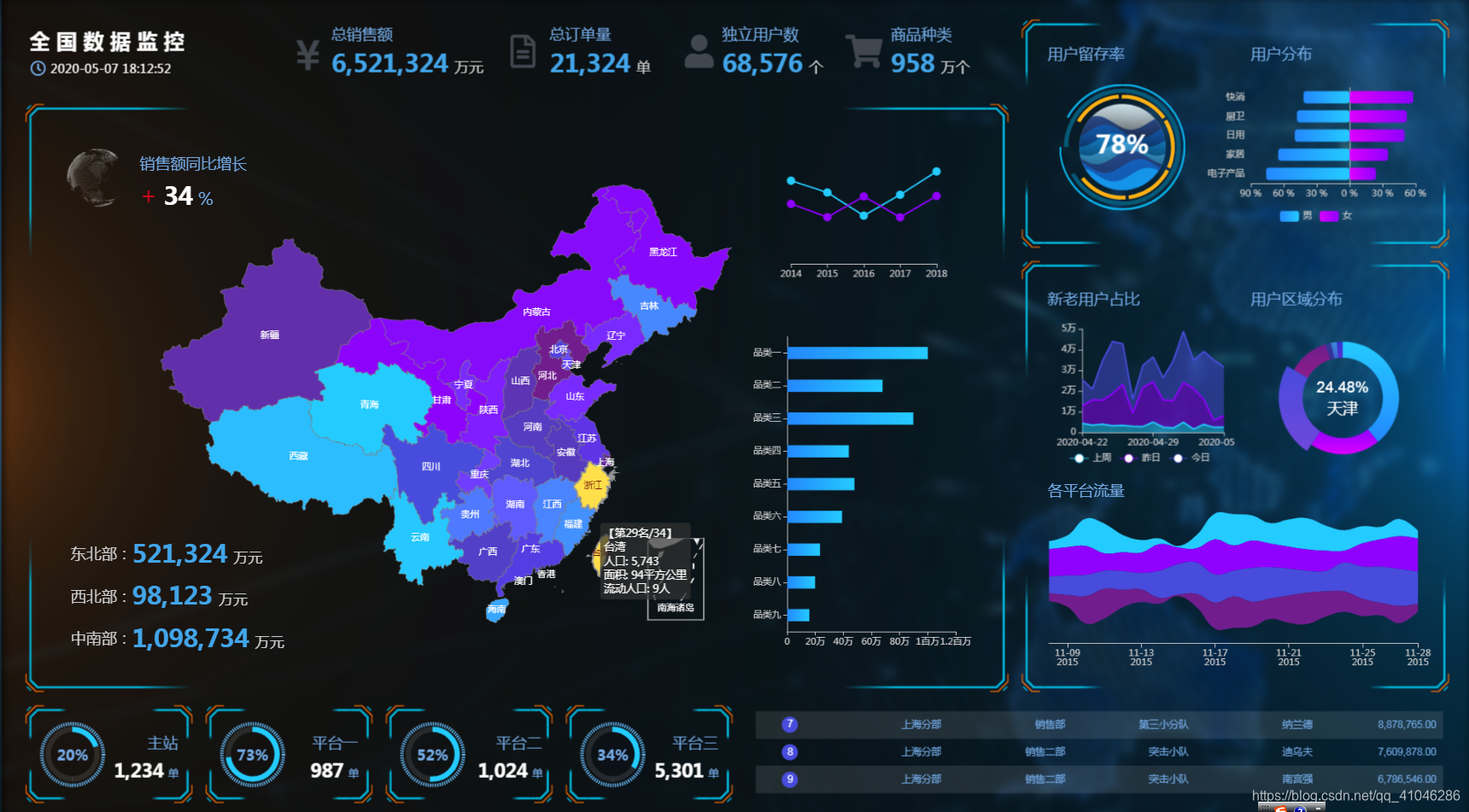
京东618实时数据大屏核心技术解密
一、背景
刚过去的618,京东销量GMV超3000亿。
(1)从用户在京东app、小程序、网页端下单、支付,到最终大屏上GMV和订单量实时累加,这中间究竟发生了什么呢?
(2)如何才能做到,用户下单,大屏上能够实时统计…

protobuf 使用和介绍
介绍
Protobuf 有没有比 JSON 快 5 倍?-InfoQ
(3条消息) protobuf、thrift、avro对比_wangqiang9x的博客-CSDN博客
序列化:ProtoBuf与JSON的比较_Java笔记虾-CSDN博客
Protobuf 使用介绍及原理: Protobuf 使用介绍及原理 (gitee.com)
(2条消息) Pro…
聊聊大数据质量监控的那些事
在这个信息化时代,你用手机打开微信聊天、打开京东app浏览商品、访问百度搜索、甚至某些app给你推送的信息流等等,数据无时无刻不在产生。
数据,已经成为互联网企业非常依赖的新型重要资产。数据质量的好坏直接关系到信息的精准度࿰…
大数据组件之HBase
文章目录前言一、HBase1、Region2、RegionServer3、Master4、Zookeeper二、HBases的Standalone安装1、解压配置环境变量1.下载2.解压3.配置环境变量2、修改配置文件信息1.hbase-env.sh2.hbase-site.xml3.启动HBase4.验证启动是否成功三、HBase完全分布式搭建四、HBase常见shell…
Hadoop的存储策略
Hadoop的存储策略
策略 ID策略名称块分布creationFallbacksreplicationFallbacks15Lazy_PersistRAM_DISK: 1, DISK: n-1DISKDISK12All_SSDSSD: nDISKDISK10One_SSDSSD: 1, DISK: n-1SSD, DISKSSD, DISK7Hot (default)DISK: n< none >ARCHIVE5WarmDISK: 1, ARCHIVE: n-1A…

HDFS读取与写入步骤详解
HDFS读取与写入步骤详解
1、Hadoop写流程
Hadoop写流程主要实现将文件上传到HDFS中,其指令格式如下所示:
#hadoop上传文件语法
hdfs dfs -put localpath hdfspath 其上传步骤可以分为以下八个步骤: 客户端通过Distributed FileSystem模块…
hadoop一键关闭脚本
hadoop一键关闭脚本
#!/bin/bash
jps>tmp.txt
NNcat tmp.txt|grep -w NameNode
DNcat tmp.txt|grep -w DataNode
SNNcat tmp.txt|grep -w SecondaryNameNode
RMcat tmp.txt|grep -w ResourceManager
NMcat tmp.txt|grep -w NodeManager
JHScat tmp.txt|grep -w JobHistoryS…
hadoop一键启动脚本
Hadoop一键启动脚本
#!/bin/bash
jps>tmp.txt
NNcat tmp.txt|grep -w NameNode
DNcat tmp.txt|grep -w DataNode
SNNcat tmp.txt|grep -w SecondaryNameNode
RMcat tmp.txt|grep -w ResourceManager
NMcat tmp.txt|grep -w NodeManager
JHScat tmp.txt|grep -w JobHistoryS…
Impala内存优化/溢出管理
一. 引言 Hadoop生态中的NoSQL数据分析三剑客Hive、HBase、Impala分别在海量批处理分析、大数据列式存储、实时交互式分析各有所长。尤其是Impala,自从加入Hadoop大家庭以来,凭借其各个特点鲜明的优点博取了广大大数据分析人员的欢心。 Impala通过主节点…

拾伍:SparkUI:高效定位性能问题一级页面(JOB-STAGE-STORAGE-ENVIRONMENT-EXECUTE-SQL)
Spark Core 与 Spark SQL 运行得是否稳定与高效,决定着 Spark 作业或是应用的整体“健康状况”。不过,在日常的开发工作中,我们总会遇到 Spark 应用运行失败、或是执行效率未达预期的情况。对于这类问题,想找到根本原因(Root Cause),我们往往需要依赖 Spark UI 来获取最…
(五)Spark广播变量,累加器
做应用开发的时候,总会有一些计算逻辑需要访问“全局变量”,比如说全局计数器,而这些全局变量在任意时刻对所有的 Executors 都是可见的、共享的。那么问题来了,像这样的全局变量,或者说共享变量,Spark 又是如何支持的呢? 按照创建与使用方式的不同,Spark 提供了两类共…
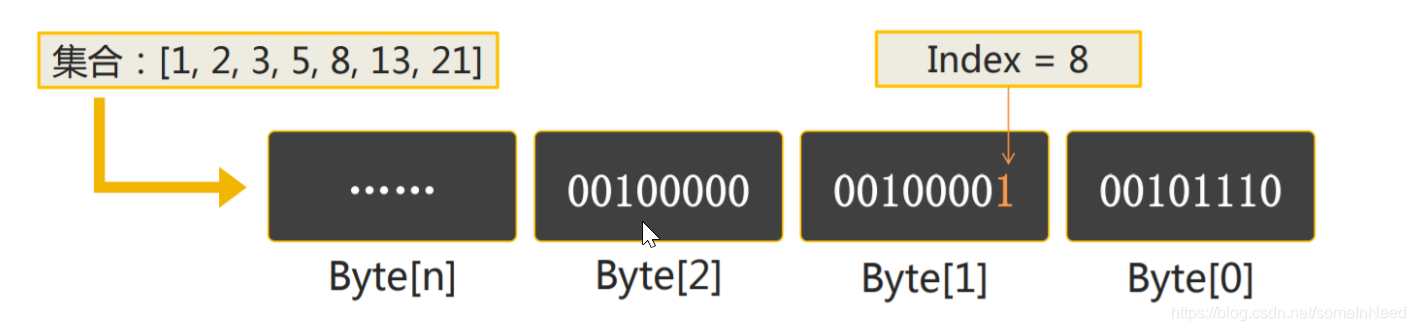
ClickHouse企业应用实战(2)
本文主要讲解 ClickHouse 的一些典型分析应用案例,重点就是告诉,一些大厂在做技术选型的时候,也就是因为 ClickHouse 的这些特点才使用的。 下面主要内容大致如下:
分组前几函数 TopK
窗口分析函数
同比环比
漏斗分析 windowF…

MSSQL数据库安全实验
预备知识
本实验要求实验者具备如下的相关知识。
1、数据库安全的概念
对任何企业组织来说,数据的安全性最为重要。安全性主要是指允许那些具有相应的数据访问权限的用户能够登录到数据库,并访问数据以及对数据库对象实施各种权限范围内的操作&#x…

学科机构转型,素质教育与成人教育的分岔路口,该如何选择?
“双减”政策发布一个月后,学科类培训机构开始在迷茫中寻求转型之路。 曾经的风口行业面临巨大挑战,核心业务受挫,各家不得不开始拓展新的业务渠道,学习新的赚钱方式。从目前各家转型动作来看,素质教育正成为主流的重点…
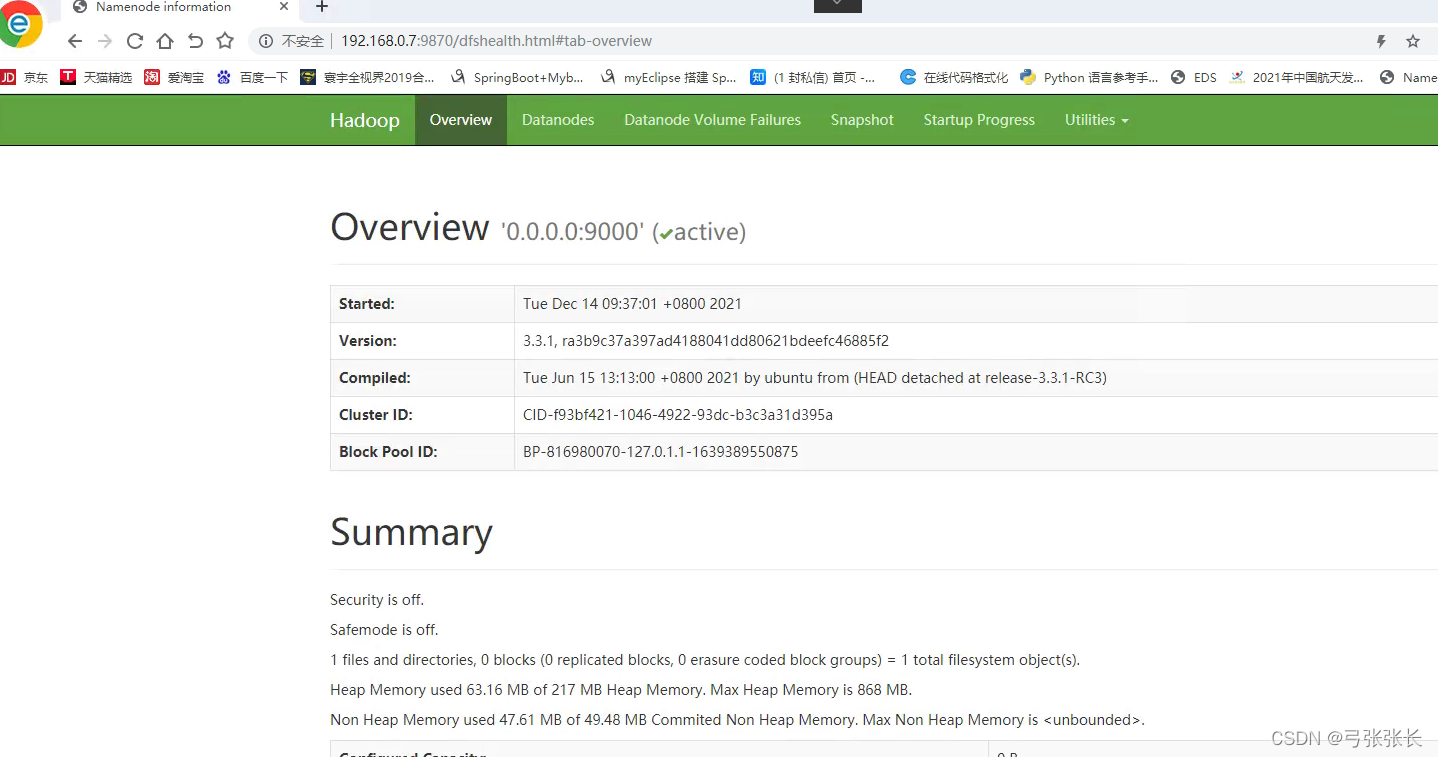
hadoop wind主机不能访问虚拟机部署的hadoop
1.查看hadoop是否启动成功:通过jps我们能够看到hadoop启动正常 2.虚拟机里面能否正常访问:9870端口,虚拟机能够通过localhost:9870正常访问 3.查看虚拟机与主机能否ping,telnet通
wind主机能够ping通 telnet 192.168.0.7 9870 发现不能够链…

新东方百万年薪招聘私域运营,实在智能RPA数字员工以一抵百
11月7日晚,俞敏洪在个人的抖音直播间表示,新东方将涉足直播农产品电商带货,随后一张关于新东方招聘以百万年薪招聘私域流量负责人的截图就在各大社交平台刷屏,大家一边感叹于新东方转型速度之快,另一方面,私…

实在智能RPA@你:再赢双12,店铺转化率靠这些
截至11月11日0点45分,382个品牌成交额破1亿元。
据每日经济新闻消息,天猫双十一成交额 :从11月1日0点到11日0点45分,已有382个品牌在天猫双11的成交额超过1亿元。其中不仅有华为、鸿星尔克等一大批人气国货品牌,也有苹…

Chapter2 大数据处理架构Hadoop
2.1 Hadoop简介和版本演变
2.1.1 Hadoop简介
Hadoop是Apache软件基金会旗下开源软件,为用户提供高层接口,为用户提供了底层细节透明的分布式基础架构。 Hadoop是基于java语言开发的,具有很好的跨平台性,但是它支持多种语言&…
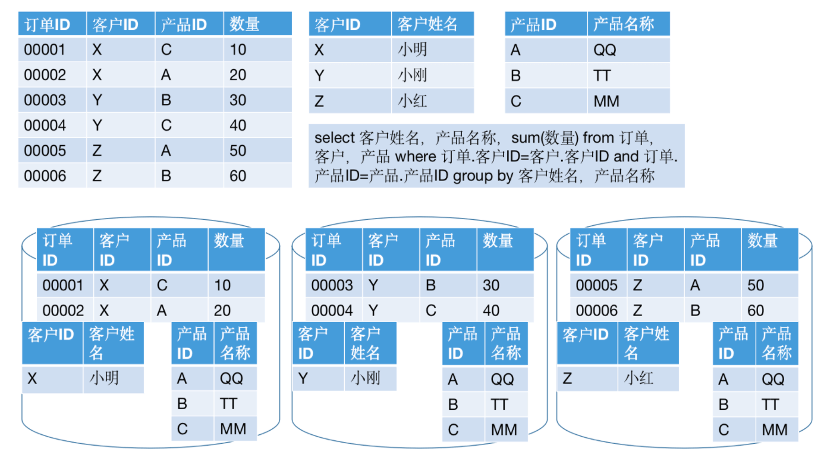
MPP架构与Hadoop架构是一回事吗?
计算机领域的很多概念都存在一些传播上的“谬误”。
MPP这个概念就是其中之一。它的“谬误”之处在于,明明叫做“Massively Parallel Processing(大规模并行处理)”,却让非常多的人拿它与大规模并行处理领域最著名的开源框架Hado…
基于Flink实时数仓——用户行为日志DWD层(1)
用户行为日志DWD层实现目标:
识别新老用户,虽然客户端有新老用户的标识,但是不准确,需要用实时计算再次确认利用侧输出流实现数据拆分,根据日志数据内容,将日志数据分为3类, 页面日志、启动日志和曝光日志。页面日志输…
Spark - SizeEstimator.estimate 字节估算之时间都去哪了
一.引言
org.apache.spark.util.SizeEstimator 类提供了 estimate 方法,该方法估计给定对象在JVM堆上占用的字节数。估计包括给定对象引用的对象占用的空间、它们的引用等。使用场景主要用于 spark 计算 broadCast 的内存容量,因为是 estimate …

新生儿注视对象注意事项:促进宝宝视觉发展的关键
引言: 新生儿的视觉发展是他们探索世界的重要方式之一。当宝宝开始盯着东西看时,这标志着他们对周围环境的兴趣和好奇心。然而,家长们也需要注意一些细节,以促进宝宝健康的视觉发展。在本文中,我们将探讨新生儿盯着东西…
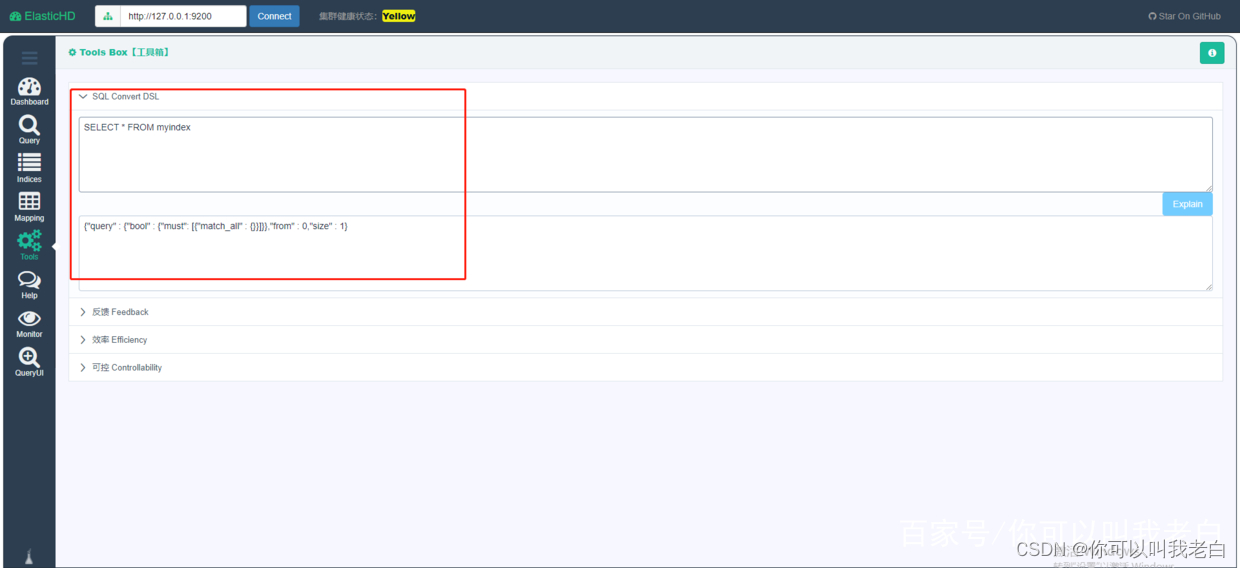
Elasticsearch好用的客户端(可视化)工具选择
前言:有道是-工欲善其事,必先利其器。老白这次想重新深入学习下Elasticsearch相关的知识。但是Elasticsearch和我们的数据库是一样的都需要客户端才可以看到相关数据。
网上推荐的五种客户端:
1.Elasticsearch-Head ,弃用。 Ela…

spark学习——scala基础篇
1、基础语法
1.1 两种变量类型
Val:不可变,在声明时就必须进行初始化,且初始化后就不能被再次赋值 Var:可变,在声音是需要进行初始化,但后续还可以进行再次赋值 在Scala中声明变量必须有这两者其一的定义…
日更100天(36)每天进步一点点
不与傻瓜论长短,不和短视者聊将来,不与安于现状者谈努力。
开始时间:2021.08.01
结束时间:2021.10.08
愿意一起进步就每天点进来看看,如果哪里有错误请在评论下方指教。第一个百更是关于阿里ACP证书的考试ÿ…
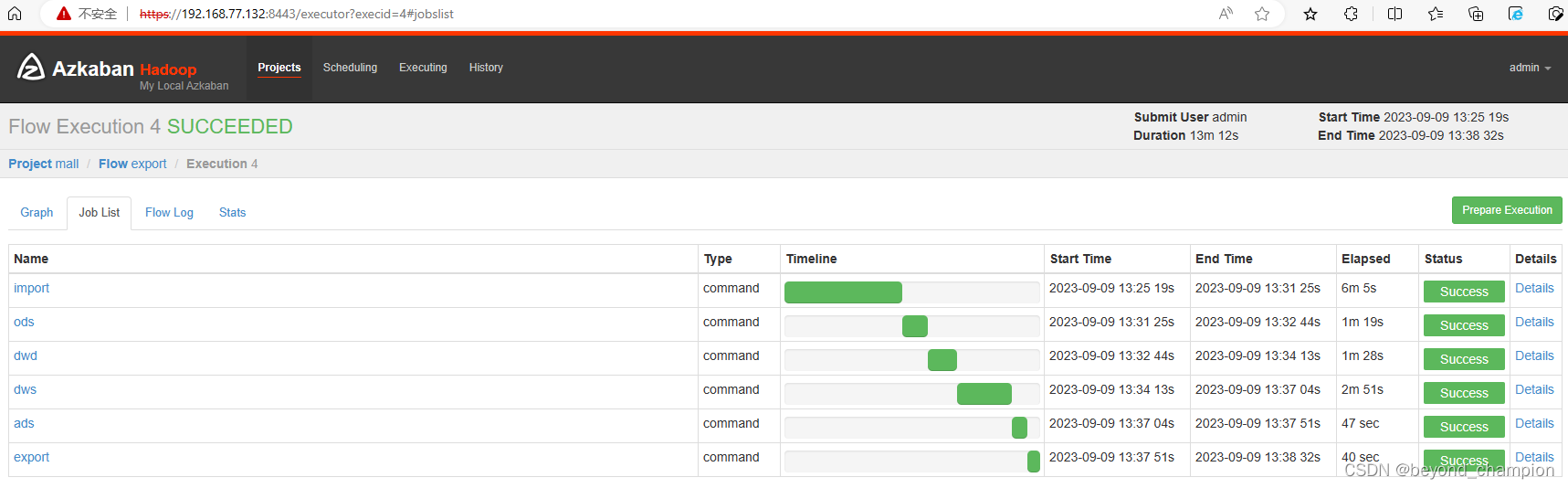
企业级数据仓库-数仓实战
数仓实战
安装包大小 安装清单 环境搭建 一、环境搭建01(机器准备)
准备好三台虚拟机,并进行修改hostname、在hosts文件增加ip地址和主机名映射 。
1、设置每个虚拟机的hostname
vi /etc/sysconfig/network
修改HOSTNAMEnode02修改hostna…
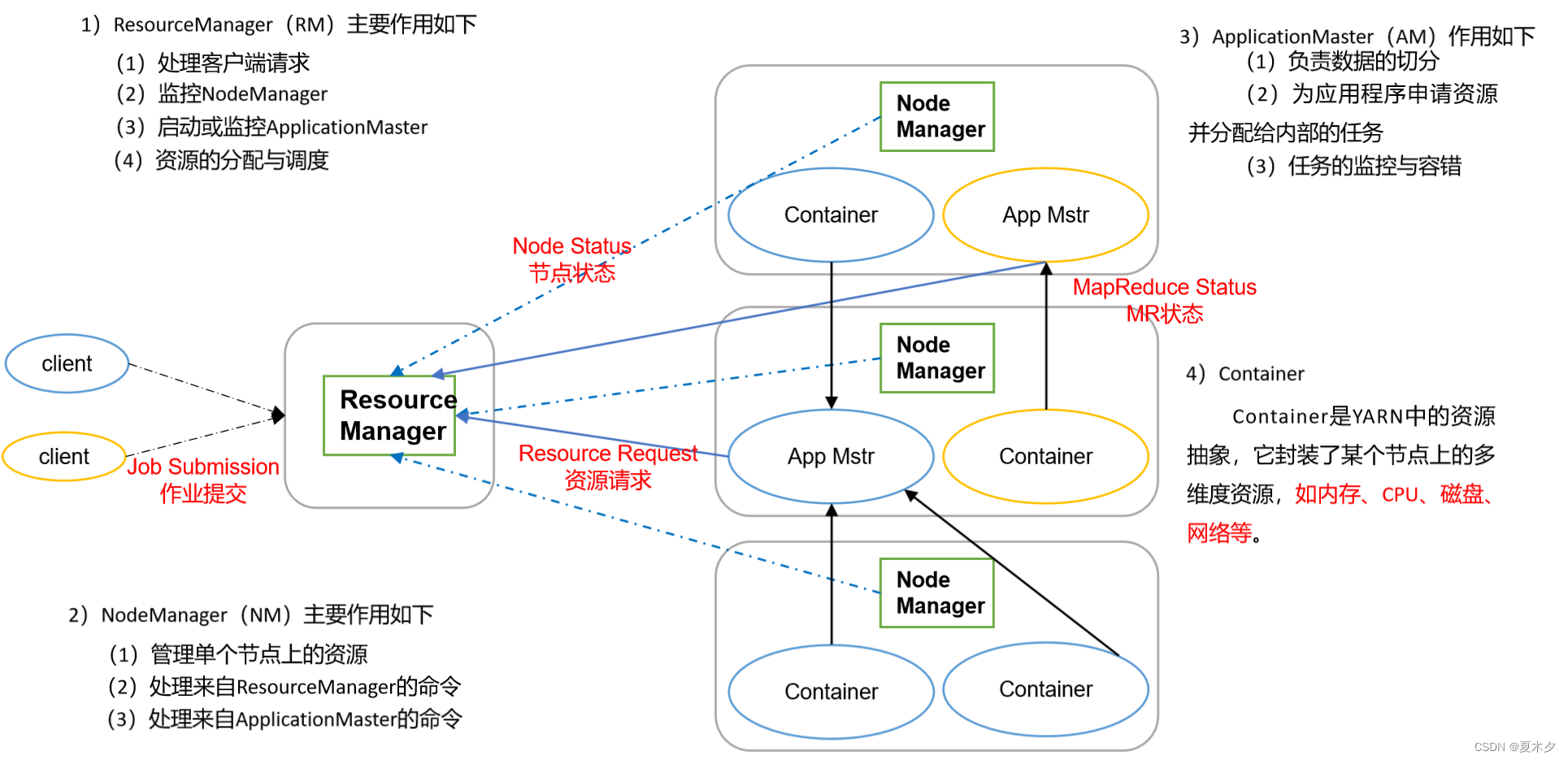
大数据技术学习笔记(一)——初识大数据
1 大数据的概念
大数据:指无法在一定的时间范围内用常规的软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储和海量数据的分析计…

Clion + mysql (win/Mac + 本地/远程)
【新手教程】那些年我用clion操作mysql的一些经验教训 本文目录使用clion自带的数据库工具,对数据库进行操作连接本地数据库建库建表编辑表格修改字段名查询数据插入新的数据sql常用语句(mysql版)【win】Clion工程连接Mysql数据库官网提供的三…
ClickHouse 相关
ClickHouse 是分布式实时分析型列式数据库服务,查询效率数倍于传统数据仓库,适用于海量数据的实时查询分析。
Notice:
操作语句需要加上ON CLUSTER default!!建表时能用数值型或日期时间型表示的字段,就不…
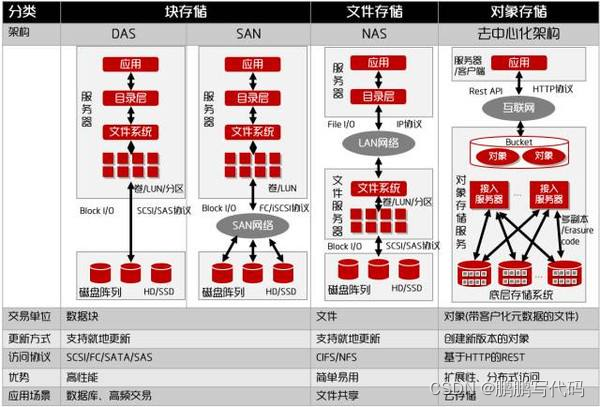
云计算基础2-什么是云存储?
云存储 万企上云,云计算作为当今时代发展趋势,云计算是一种网上在线存储的模式,即把数据存放在通常由第三方托管的多台虚拟服务器,而非专属的服务器上。托管(hosting)公司运营大型的数据中心,需…

Java--基于Java编写的数据库加解密工具包(附)GitHub源码
GitHub源码地址:https://github.com/JustinJava/pwd-encrypt-decrypt (图1)项目应用场景 (图2)SHELL脚本应用场景 一、背景介绍
如上图1和图2标记部分所示,项目中数据库连接配置的密码密文和SHELL脚本中的…

ArcGIS学习总结(一)——空间数据库管理及属性编辑
本文转载自《https://blog.csdn.net/weixin_43626557/article/details/90637450》
一、介绍 ArcCatalog 用于组织和管理所有 GIS 数据。它包含一组工具用于浏览和查找 地理数据、记录和浏览元数据、快速显示数据集及为地理数据定义数据结构。 ArcCatalog 应用模块帮助你组织和…
4.HTML5新特性:拖拽API与本地数据库
本地文件
介绍:通过使用在 HTML5 中加入到 DOM 的 File API,使在web内容中让用户选择本地文件然后读取这些文件的内容。
概念:FileReader接口 主要是用来把文件读入内存,并且读取文件中的数据,fileReader接口提供异步API
在学习FileReader…
平台系统老板驾驶舱的重要性,我选云表
平台系统老板驾驶舱的重要性在于它是一个集成的管理和分析工具,能够提供对平台系统运行情况的全面和实时的监控、分析和管理功能。以下是平台系统老板驾驶舱的重要性:
老板驾驶舱 该表单可供老板实时把控企业运营情况,包括销售业绩、…
4年前,当我进入这家公司,便深感管理无力
有形的东西,看得见摸得着,只要有一道有形的围墙,管理也乱不到哪里去,可是这个行业的核心,是以合同为纽带的信息流管理。以长租合同为例,履约期限长达3年,涉及合同签约、归档、应收登记、实收登记…

新生儿发烧:原因、科普和注意事项
引言:
新生儿发烧是新父母常常担心的问题之一,因为婴儿的免疫系统尚未完全发育,对感染更为脆弱。尽管发烧在婴儿中是相对常见的,但它可能引起家长的焦虑。本文将科普新生儿发烧的原因,提供相关信息,并为父…
国产企业级低代码开发哪个最好?这一款超好用
低代码开发平台(Low-code Development Platform)正在迅速崛起,成为未来软件技术发展的主导趋势。通过使用低代码开发平台,企业能够显著提高开发效率,降低对专业开发人员的依赖,并实现更快速的软件交付和使用…
2023.11.18 Hadoop之 YARN
1.简介
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。支持多个数据处理框架&…

低代码平台全解析:衍生历程、优势呈现与未来趋势一览无余
在数字化时代,应用程序的开发与更新已成为企业保持竞争力的关键。传统的编码方式,虽然精细且功能强大,但耗时且要求开发者具备较高的技术水平。在这样的背景下,低代码开发平台的出现无疑为企业带来了福音。 低代码开发平台是一种创…
PiflowX组件-ReadFromKafka
ReadFromKafka组件
组件说明
从kafka中读取数据。
计算引擎
flink
有界性
Unbounded
组件分组
kafka
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子kafka_hostKAFKA_HOST“”无是逗号分隔的Ka…

PiflowX组件-JDBCWrite
JDBCWrite组件
组件说明
使用JDBC驱动向任意类型的关系型数据库写入数据。
计算引擎
flink
有界性
Sink: Batch
Sink: Streaming Append & Upsert Mode
组件分组
Jdbc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默…

利用低代码技术,企业怎样开拓数字化转型新路径?
近年来,随着技术的发展和市场竞争的加剧,企业数字化转型已成为一种趋势。许多企业已经完成了线上协作办公的初步转型,这主要得益于像钉钉、企微等发展完善的平台,只需将员工全部拉入这些平台,就能实现线上协作办公。 然…
性能比较:in和exists
当在Hive SQL中使用NOT IN和NOT EXISTS时,性能差异主要取决于底层数据的组织方式、数据量大小、索引的使用情况以及具体查询的复杂程度。下面是对这两种方法的性能分析:
1. NOT IN:- 工作原理:NOT IN子查询会逐个比较主查询中的值…
数字化转型导师坚鹏:金融科技咨询方法论
金融科技咨询方法论
——方法、做法、演法、心法 课程背景:
数字化转型背景下,很多机构存在以下问题:
不知道先进的金融科技咨询方法论?
不知道如何运作金融科技咨询项目?
不知道如何汇报咨询项目关键成果&…
第八篇 - 预测受众(Predictive audience)技术是如何赋能数字化营销生态的?- 我为什么要翻译介绍美国人工智能科技巨头IAB公司
IAB平台,使命和功能
IAB成立于1996年,总部位于纽约市。
作为美国的人工智能科技巨头社会媒体和营销专业平台公司,互动广告局(IAB- the Interactive Advertising Bureau)自1996年成立以来,先后为700多家媒…
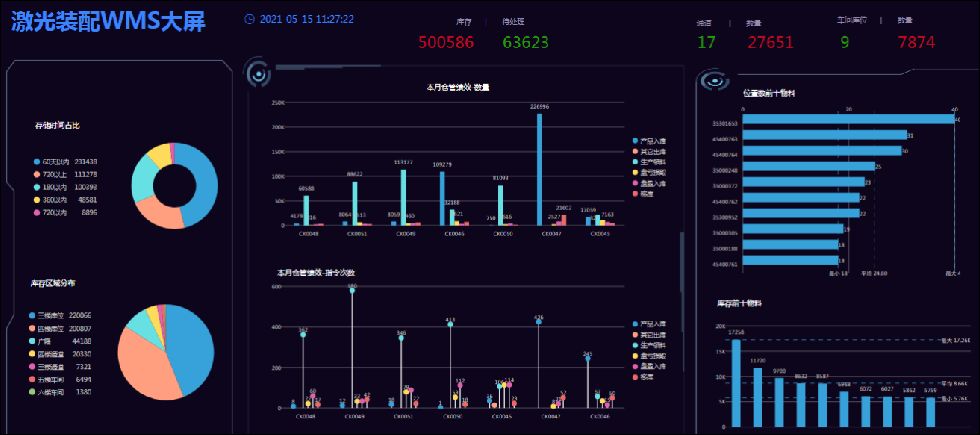
3款免费又实用的良心软件,功能强大到离谱,白嫖党的最爱
闲话不多说,直接上硬货!
1、酷狗概念版
这款正版音乐APP可谓是“良心之作”。不论你是新用户还是老用户,只要踏入概念版的门槛,即可获得3个月VIP作为见面礼。更令人惊喜的是,每天只需轻松一点播放歌曲,即…
数字化转型导师坚鹏:银行业科技产品及零售贷款咨询方法与案例
银行业科技产品及零售贷款咨询方法与实战案例 课程背景:
数字化转型背景下,很多机构存在以下问题:
不知道银行业科技产品咨询方法?
不知道零售贷款咨询方法与案例?
不知道信贷中台咨询方法与案例?
…
Python控制摄像头并获取数据文件
一、引言 摄像头作为计算机视觉领域的核心设备之一,广泛应用于视频监控、图像采集和数据处理等领域。通过Python编程语言,我们可以实现对摄像头的精确控制,包括摄像头的开启、关闭、参数设置以及数据获取等功能。 目录
一、引言
二、摄像头…

关于远程协作可以分享的有很多,今天单说“定期面对面实现反熵”
自 Tubi 中国团队创立以来,我们就与美国的同事进行着跨时区、跨地域的远程协作。在过去的七年里,我们通过日复一日的协作实践,逐步形成了一个可靠可扩展的分布式协作模型,并且在全球疫情期间得到了进一步有效的验证。
在分布式系…

云表:MES系统是工业4.0数字化转型的核心
随着信息技术与工业技术的深度融合,网络、计算机技术、信息技术、软件与自动化技术相互交织,产生了全新的价值模式。在制造领域,这种资源、信息、物品和人相互关联的模式被德国人定义为“工业4.0”,也就是第四次工业革命。工业4.0…

使用 Data Assistant 快速创建测试数据集
使用 Data Assistant 快速创建测试数据集
Data Assistant 提供超过 100 种数据类型,为任何开发、测试或演示目的生成大量、异构、真实的数据。
官网地址: http://www.redisant.cn/da
主要功能 Windows 原生 Data Assistant 使用 Windows Native 技术…

主成分分析(PCA)及其可视化——python
可以看看这个哦python入门:Anaconda和Jupyter notebook的安装与使用_菜菜笨小孩的博客-CSDN博客
如果你学会了python 可以看看matlab的哦
主成分分析(PCA)及其可视化——matlab_菜菜笨小孩的博客-CSDN博客
目录
一、主成分分析的原理
二…

评比无代码低代码平台时,可以考虑以下几个方面
无代码低代码平台是近年来兴起的一种软件开发工具,它们旨在帮助非技术人员快速创建应用程序,而无需编写大量的代码。这些平台通过提供可视化的界面和预先构建的组件,使用户能够通过拖放和配置的方式来构建应用程序。选择无代码低代码平台时&a…

低代码开发是不是“简易低智”的玩具?看这篇就够了
低代码的概念自2014年由研究机构Forrester提出以来,已经在国外市场逐渐成熟,形成了稳定的商业模式。而在国内,从2018年开始,这一理念逐渐受到广泛关注,尽管初期伴随着一些质疑的声音,如“简易低智”、“新瓶…

数字化转型:云表低代码开发助力制造业腾飞
数字化转型已成为制造业不可避免的趋势。为了应对市场快速变化、提高运营效率以及降低成本,制造业企业积极追求更加智能化、敏捷的生产方式。在这个转型过程中,低代码技术作为一种强大的工具,正逐渐崭露头角,有望加速制造业的数字…
PiflowX-MysqlCdc组件
MysqlCdc组件
组件说明
MySQL CDC连接器允许从MySQL数据库读取快照数据和增量数据。
计算引擎
flink
组件分组
cdc
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子hostnameHostname“”无是MySQL…
【美团】SaaS技术部-后端研发工程师(海外业务)
部门介绍
美团餐饮系统为餐饮企业提供一站式IT解决方案,帮助餐饮商户实现从供应链管理、生产管理、前厅管理到外卖的数字化经营。美团餐饮系统不仅打通了餐厅和平台,更帮助餐厅连接客人,让商户更了解顾客需求,在帮助商户做商业决…
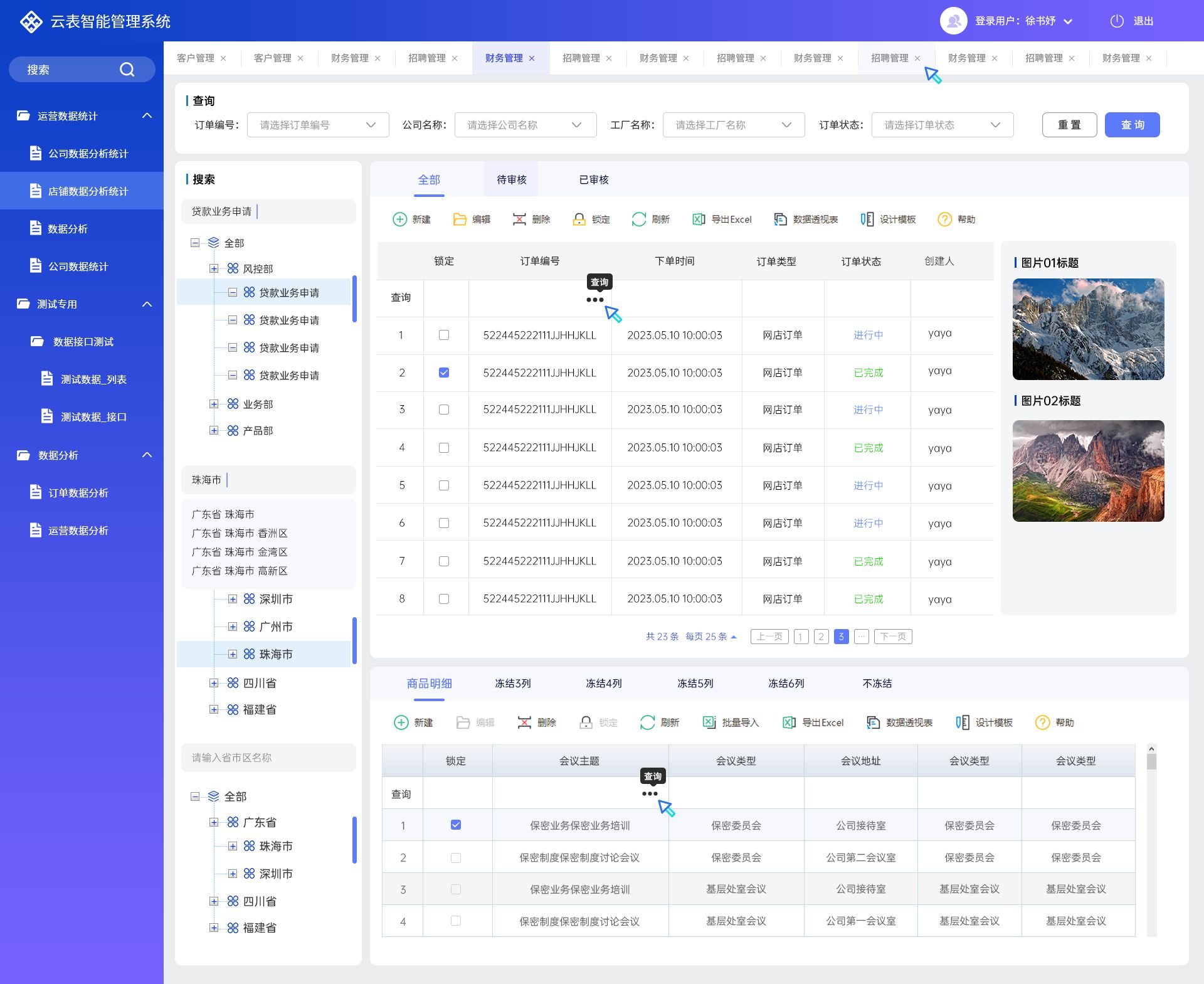
办公软件巨头CCED、WPS面临新考验,新款办公软件异军突起
办公软件巨头CCED、WPS的成长经历
众所周知,CCED和WPS在中国办公软件领域树立了两大知名品牌的地位。然而,它们的成功并非一朝一夕的成就,而是历经了长时间的发展与积淀。 在上世纪80年代末至90年代初,CCED作为中国大陆早期的一款…
跨平台开发:浅析uni-app及其他主流APP开发方式
随着智能手机的普及,移动应用程序(APP)的需求不断增长。开发一款优秀的APP,不仅需要考虑功能和用户体验,还需要选择一种适合的开发方式。随着技术的发展,目前有多种主流的APP开发方式可供选择,其…
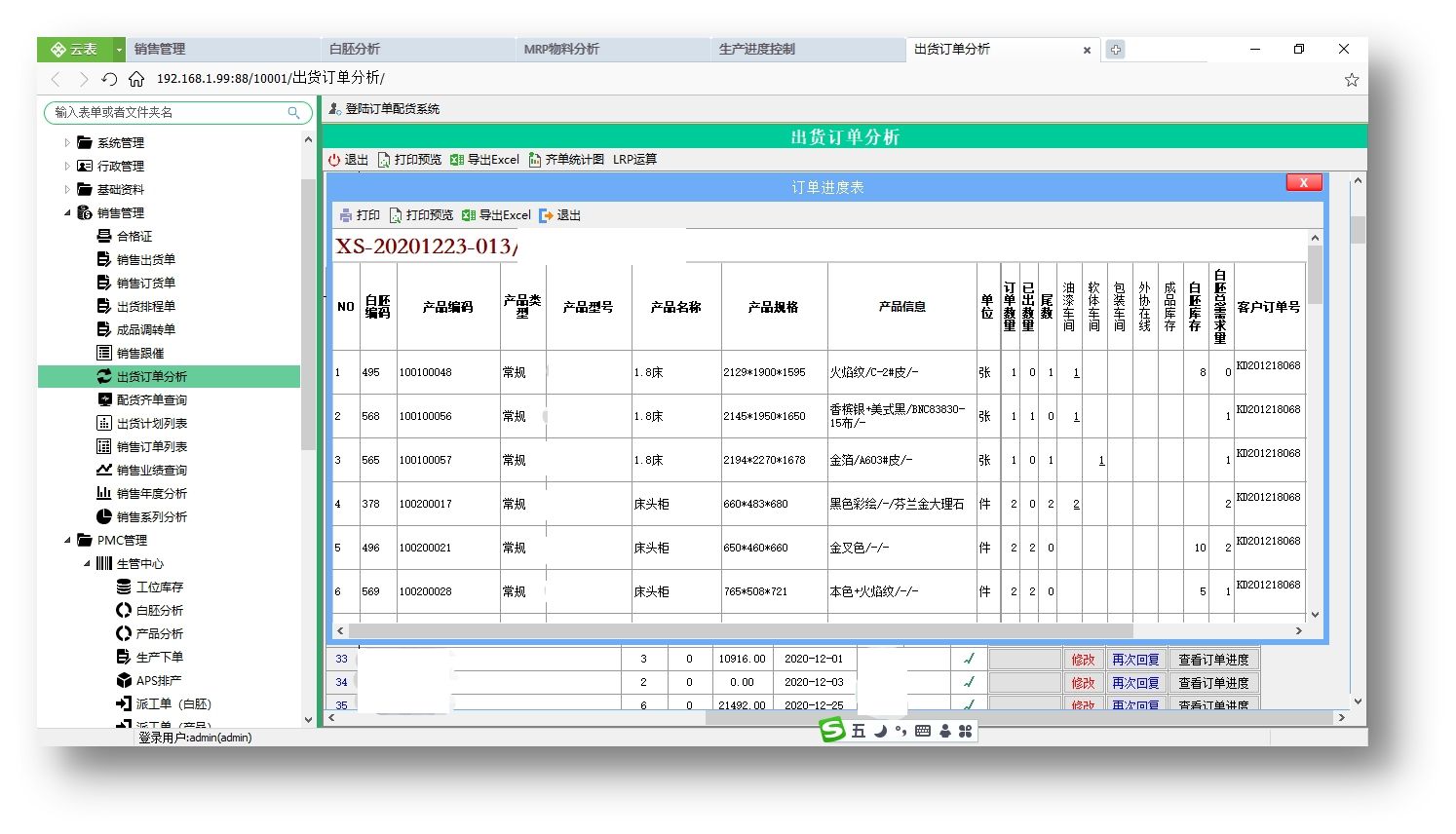
为电子表格嵌入数据库,Excel/WPS一键升级为管理系统
将Excel表格转化为管理系统,这款工具能够实现只需导入表格数据,即可自动生成相应的软件和APP。
表格办公的烦恼,有遇到吧?
对于具有一定规模的企业而言,各类表格如同繁星般众多,既有日常使用的常规表格&a…

数据可视化Tableau
目录
一.第一次实验课内容
1、熟悉Tableau Desktop的工作环境。
2、熟悉数据导入、维度和度量的区分以及不同数据字段类型的标识符。
3、熟悉工作表的基本操作,主要包括行列功能区,标记卡,筛选器,智能推荐的使用。
4、作业--…
【30秒看懂大数据】留存分析
30秒看懂大数据专栏
让您在有限的碎片化时间,快速看懂最火热的大数据 简单说
公众号:知幽科技,更多知识分享及社群欢迎关注。
留存分析是对不同时间周期存留的情况作分析,常常和7天、30天这样的时间周期一起出现。 举例理解 …
数字化转型导师坚鹏:数字政府技术、业务、数据融合发展路径探索
数字政府建设与发展研究
——技术、业务、数据融合发展路径探索
课程背景:
很多政府存在以下问题:
不清楚数字政府建设内涵
不清楚数字政府建设现状
不清楚数字政府融合路径
课程特色:
有实战案例
有原创观点
有精彩解读
学…
数字化转型导师坚鹏:县域数字化转型案例研究
县域数字化转型案例研究
课程背景:
很多县级政府存在以下问题:
不清楚县域数字化转型的发展模式
不清楚县域数字化转型的成功案例
课程特色:
针对性强
实用性强
创新性强
学员收获:
学习县域数字化转型的发展模式。
学习县…
数字化转型导师鹏:政府数字化转型政务服务类案例研究
政府数字化转型政务服务类案例研究
课程背景:
很多地方政府存在以下问题:
不清楚标杆省政府数字化转型的政务服务类成功案例
不清楚地级市政府数字化转型的政务服务类成功案例
不清楚县区级政府数字化转型的政务服务类成功案例
课程特色&#x…

银行数字化转型导师坚鹏:银行数字化转型案例研究
银行数字化转型案例研究 课程背景:
数字化背景下,很多银行存在以下问题:
不清楚银行科技金融数智化案例?
不清楚银行供应链金融数智化案例?
不清楚银行普惠金融数智化案例?
不清楚银行跨境金融数智…
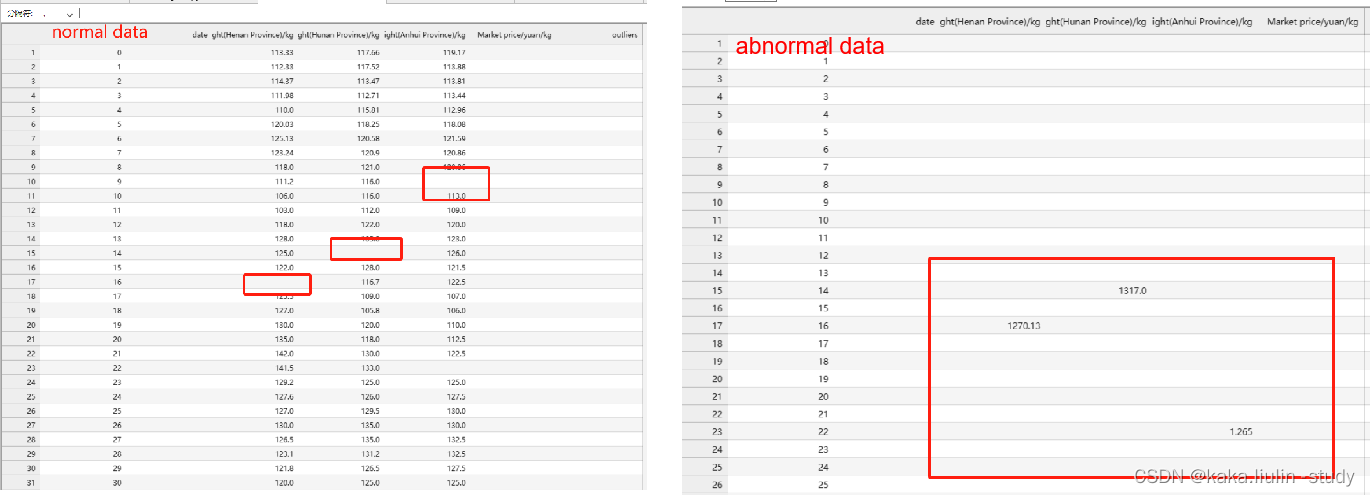
LLM 构建Data Multi-Agents 赋能数据分析平台的实践之②:数据治理之一
概述
数据治理不仅是产业数字化转型的基石,更是推动产业向更高层次、更精细化、更智能的方向发展的重要引擎。通过科学有效的数据治理实践,产业能够在数字化进程中实现数据驱动的决策与行动,最终达到转型升级的战略目标。 一、数据治理在产业…
第二章Iceberg简介
Iceberg数据类型
Iceberg数据类型是在Apache Iceberg这一开源大数据表格管理库中定义的一系列数据格式,它们用于描述和存储表格中的数据。Iceberg旨在提供可扩展且可靠的方式来管理海量数据表格,因此其数据类型设计也充分考虑了大数据处理的需求。
以下…

大数据的关键技术之——大数据采集
大数据的关键技术之——大数据采集 本文目录:
一、写在前面的话
二、大数据采集概念
三、大数据采集步骤
3.1、大数据采集步骤(总体角度)
3.2、大数据采集步骤(数据集角度)
3.3、大数据采集步骤(数据…